|
DOI: 10.25136/2644-5522.2021.1.35101
Received:
22-02-2021
Published:
01-10-2021
Abstract:
This article explores certain aspects of the process of numerical solution of the tasks of continuous medium mechanics in the conditions of ongoing chemical reactions. Such tasks are usually characterized by the presence of multiple local areas with elevated temperature, which position in space is relatively unstable. In such conditions, rigidly stable methods of integration with step control, which in the “elevated temperature” areas that have higher time input comparing to other areas. In terms of using geometric parallelism, this fact leads to substantial imbalance of CPU load, which reduces the overall effectiveness of parallelization. Therefore, this article examines the problem of CPU load balancing in the context of parallel solution of the aforementioned tasks. The other offers a new modification of the algorithm of large-block distributed balancing with improved time prediction of the numerical integration of chemical kinetics equations, which is most effective in the conditions of drift of the areas with “elevated temperatures”. The improvement consists in application of the linear perceptron, which analyzes several previous values of time integration (the basic version of the algorithm uses only one previous spot from the history of time integration). This allows working in the conditions of fast and slow drift of the areas with “elevated temperatures”. The effectiveness of this approach is demonstrated on the task of modeling the flow-around the building with high-temperature combustion on its roof. It is indicated that the application of modified algorithm increases the effectiveness of parallelization by 2.1% compared to the initial algorithm.
Keywords:
parallel computations, load balancing, linear perceptron, chemical kinetics, continuous medium mechanics, distributed balancing, numerical simulation, numerical experiment, approbation, geometrical parallelizing
Введение
Существует большое количество задач механики сплошной среды, осложненных необходимостью учета фактора химической кинетики. Назовем задачи моделирования процессов возникновения и распространения пожаров, задачи моделирования процессов образования фотохимического смога на улицах большого города, а также разнообразные технические задачи, связанные с горением. Обычно такие задачи имеют постановку в виде системы дифференциальных уравнений в частных производных, описывающей распространение реагентов, к которой присоединяется система обыкновенных дифференциальных уравнений химической кинетики, описывающая изменение концентраций реагентов в результате химических реакций.
Обычно задачи такого класса решаются итерационно, с применением схем расщепления. При этом на каждой итерации по времени сначала осуществляется шаг численного интегрирования уравнений в частных производных, определяющий изменение концентраций реагентов в ячейках расчетной сетки в результате межъячеечного переноса, а затем выполняется шаг численного интегрирования обыкновенных дифференциальных уравнений химической кинетики. Важной отличительной чертой второго шага является значительное различие скоростей протекания химических реакций в ячейках, если в расчетной области присутствуют существенные тепловые неоднородности. Расчет протекания таких реакций обычно производится жестко устойчивыми методами с контролем шага (например, методом Гира), причем различие скоростей протекания реакций приводит к существенному различию времени интегрирования уравнений химической кинетики в ячейках.
Задачи рассматриваемого класса трудоемки с вычислительной точки зрения и решаются почти исключительно с применением параллельных вычислений, обычно с применением геометрического параллелизма. При этом различие времени, требуемого на интегрирование кинетических уравнений в разных узлах, в условиях тривиального геометрического параллелизма приводит к значительным неоднородностям времени счета областей, относящихся к различным процессорам, что резко снижает эффективность распараллеливания и значительно увеличивает время счета.
Эффективное решение проблемы неоднородности вычислительной загрузки процессоров возможно, если пытаться (на каждой итерации, при осуществлении шага решения уравнений химической кинетики) динамически перераспределять узлы так, чтобы вычислительная неоднородность загрузки процессоров была минимальной.
Такие алгоритмы динамической балансировки загрузки известны [1], они обладают различной эффективностью для различных систем. Их можно разделить на следующие группы [1]: а) с применением вычисляющей среды [2], б) централизованные (см., например, обзор в [3]), в) распределенные [4], г) диффузные (В.Э.Малышкин, А.П.Карпенко, см. обзор в [3], также Cybenko [5] и Boillat [6]), д) случайные [7]. Подробное сравнение алгоритмов проведено в работе [1], здесь же отметим следующее:
а) алгоритмы вычисляющей среды могут иметь недостаточно высокую эффективность балансировки, поскольку перераспределение нагрузки между процессорами выполняется фиксированными «слоями» узлов;
б) централизованные алгоритмы имеют сравнительно высокие коммуникационные затраты на взаимодействие центрального процессора с рабочими и, как следствие, недостаточные надежность и эффективность распараллеливания;
в) распределенные алгоритмы часто имеют хорошие показатели по эффективности балансировки и эффективности распараллеливания, и вполне могут быть взяты за основу в настоящей работе;
г) алгоритмы диффузной балансировки осуществляют перераспределение узлов между процессорами, обрабатывающими соседние блоки расчетной области, что также может давать недостаточную эффективность балансировки;
д) алгоритмы случайной балансировки также часто могут давать недостаточную эффективность балансировки, давая средние по качеству балансировки результаты.
В работе [1] показано, что для задач с медленным дрейфом «горячих» областей эффективен распределенный алгоритм, при котором распределение нагрузки по процессорам основывается на предполагаемом времени интегрирования, которое считается условно равным времени с предыдущего шага. Недостатком такого подхода к предикции времени является его ограниченная применимость в условиях быстрого дрейфа «горячих» областей. Актуален вопрос об уменьшении данного недостатка.
Целью данной работы является повышение эффективности алгоритма распределенной балансировки загрузки [1] и его распространение на случаи с быстрым дрейфом «горячих» областей. Поставим задачи: а) предложить соответствующие модификации алгоритма на базе более совершенных средств предсказания времени интегрирования; б) провести апробацию полученного алгоритма на реальной задаче.
1. Базовый алгоритм
Алгоритм распределенной крупноблочной балансировки [1] выполняется на каждом шаге интегрирования системы уравнений химической кинетики. Перед началом шага известна история замеров времени счета для каждого узла-ячейки. Используя эту информацию, каждый процессор определяет предполагаемое время обработки каждого изначально приписанного ему (в соответствии с геометрическим параллелизмом) узла (в базовом варианте считается, что это время равно соответствующему времени с предыдущей итерации, по этой причине базовый вариант успешно применим только в условиях медленного дрейфа «горячих» областей с высоким временем обработки) и делится этой информацией с остальными процессорами. На основании этих данных каждый i-й процессор вычисляет предполагаемую среднюю нагрузку M и определяет, насколько она отличается от его текущей, геометрически распределенной нагрузки Ri. Эта информация используется для априорного перераспределения нагрузки в начале текущего шага.
Процессоры с M < Ri однократно определяют, каким процессорам они будут передавать лишнюю нагрузку, а процессоры с M > Ri однократно определяют, от каких процессоров они примут нагрузку. После этого процессоры приступают к обработке оставшихся «своих» узлов, одновременно с этим выполняются крупноблочные (это позволяет передавать данные более быстро) обмены излишней/недостающей нагрузкой. При завершении обменов процессоры-получатели обрабатывают принятые узлы и алгоритм расчета химической кинетики с балансировкой завершает текущий шаг.
2. Модификация
Предположим, что для предсказания загрузки процессора Vi в каждом i-м узле (i = 1…N, где N – число узлов) можно использовать линейную экстраполяцию, опирающуюся на историю из P предыдущих замеров величины загрузки в i-м узле (это величины Hi,j, j = 1…P). Экстраполяция реализуется линейным соотношением:
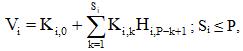
где Ki,k – коэффициенты i-го экстраполятора, Si – порядок i-го экстраполятора. Такой экстраполятор эквивалентен линейному персептрону из одного нейрона со смещением Ki,0. Персептрон обучается методом наименьших квадратов. В данной работе персептрон программно реализуется авторегрессионным точечным каналом [8].
3. Апробация
Рассмотрим нестационарную задачу с относительно быстрым изменением положения «горячих» областей. Пусть это будет двумерное обтекание здания переменным воздушным потоком, причем отмечается тепловая неоднородность: на крыше здания наблюдается процесс горения при высокой температуре.
Проведем несколько численных экспериментов с балансировкой загрузки (на базе линейной экстраполяции) на вычислительной системе с 4-ядерным процессором Intel Atom. Результаты замеров времени решения и расчетов эффективности распараллеливания кинетического блока сведены в таблицу 1. При расчетах использовалась замеренная величина времени решения на одном процессоре T(1) = 299,45 с. Также было замерено и время решения в параллельном варианте (T(N), на N процессорах), но без балансировки – оно составило величину в 195,73 с. Сравнивая эту величину с данными таблицы 1, легко видеть, что балансировка была оправданной.
Таблица 1. Показатели решения с балансировкой (модификация)
|
Расчетная величина
|
Порядок экстраполятора Si
|
|
1
|
2
|
3
|
|
Время решения T(4), с
|
99,88
|
97,06
|
100,43
|
|
Эффективность распараллеливания T(1)/(4×T(4))
|
0,75
|
0,771
|
0,745
|
Из таблицы 1 очевидно, что расчет по модифицированному алгоритму (Si = 2) оказался несколько быстрее расчета по базовому алгоритму, соответствующему Si = 1. Выигрыш составил величину около 2,1% эффективности распараллеливания. В то же время вариант с Si = 3 не только не дал прироста производительности, но и снизил ее. Это может объясняться двумя причинами: а) ростом затрат на собственно предикцию, которые превысили эффект выравнивания загрузки, б) некорректностью предикции (предиктор реализует фиктивные или частные зависимости, использующие чрезмерно большое количество предыдущих точек). Тем не менее, можно предположить, что модификации алгоритма при Si > 2 могут найти применение в каких-либо еще более сложных случаях.
Заключение
В данной работе предложена модификация алгоритма крупноблочной распределенной балансировки, основанная на применении линейного персептрона для предсказания времени интегрирования в узлах, пригодна для случаев как с медленным, так и с относительно быстрым дрейфом "горячих" областей. Модификация апробирована в задаче о моделировании обтекания одиночного здания с горением на крыше (случай быстрого дрейфа "горячих" областей). Показано, что применение модифицированного алгоритма повышает эффективность распараллеливания на 2,1% по сравнению с исходным алгоритмом.
References
1. Pekunov V.V. Novye metody parallel'nogo modelirovaniya rasprostraneniya zagryaznenii v okrestnosti promyshlennykh i munitsipal'nykh ob''ektov // Dis. dokt. tekh. nauk.-Ivanovo, 2009.-274 s.
2. Nuzhdin N.V., Yasinskii F.N. Predstavlenie o vychislyayushchei srede i ego primenenie dlya rasparallelivaniya algoritmov v mekhanike zhidkostei i gazov // Vestnik IGEU. — Ivanovo, 2003. — Vyp.1. — S.82-84.
3. Yakobovskii M.V. Vychislitel'naya sreda dlya modelirovaniya zadach mekhaniki sploshnoi sredy na vysokoproizvoditel'nykh sistemakh: Avtoref. dis. dokt. fiz.-mat. nauk. — Moskva, 2006. — 37 s.
4. Kornilina M.A., Yakobovskii M.V. Dinamicheskaya balansirovka zagruzki protsessorov pri modelirovanii zadach goreniya // Vysokoproizvoditel'nye vychisleniya i ikh prilozheniya: Tr. Vseross. nauch. konf. — M.: Izd-vo MGU, 2000. — S.34-39.
5. Cybenko G. Load balancing for distributed memory multiprocessors /Par. Distr. Comp.— 1989.— Vol.7.— P.279-301.
6. Boillat J.E. Load balancing and Poisson equation in a graph. /Currency Practice and Experience.— 1990. — Vol.2.— №4.— P.289-313.
7. Rudoph L., Slivkin-Allouf M., Upfal E. A simple load balancing scheme for task allocation in parallel machines. /Proc. 3rd Annual ACM Symp. On Parallel Algorithms and Architectures (APAA, 91).— 1991.— P.237-245.
8. Pekunov V.V. Preditsiruyushchie kanaly v parallel'nom programmirovanii: vozmozhnoe primenenie v matematicheskom modelirovanii protsessov v sploshnykh sredakh // Programmnye sistemy i vychislitel'nye metody. – 2019. – № 3. – S. 37-48. DOI: 10.7256/2454-0714.2019.3.30393 URL: https://nbpublish.com/library_read_article.php? id=30393
|









