|
Software systems and computational methods
Reference:
Simankov, V.S., Drilenko, M.V. (2021). Integration of information resources of situational centers . Software systems and computational methods, 4, 58–67. https://doi.org/10.7256/2454-0714.2021.4.34845
Integration of information resources of situational centers
Simankov Vladimir Sergeevich
Doctor of Technical Science
Professor, the department of Computer Technologies and Information Security, Kuban Technological University
350072, Russia, Krasnodarskii krai, g. Krasnodar, ul. Moskovskaya, 2

|
sv@simankov.ru
|
|
 |
|
Drilenko Maxim Vladimirovich
Postgraduate student, the department of Computer Technologies and Information Security, Kuban Technological University
350072, Russia, Krasnodarskii krai, g. Krasnodar, ul. Moskovskaya, 2
|
|
dril.max@rambler.ru
|
|
|
|
DOI: 10.7256/2454-0714.2021.4.34845
Received:
12-01-2021
Published:
31-12-2021
Abstract:
The existing approaches towards formation of a single information space for accessing from various information resources are not effective enough from the economic and operational perspective. The subject of this research is the information assets from different sources used for the work of intelligent situational centers. The goal lies in the development of methodology for unification of such resources into a single information space, which is essential for the processing of large volumes of unstructured and poorly structured information. The article explores the models and types of data, information space of the activity for determining the end type of data representation, and the algorithm of transitioning from the object to NoSQL model. As a result of the conducted research, the author built a new information structure of the intelligent situational center. The proposed methodology for the formation of physical data models is compatible with the four types of NoSQL databases: columns, documents, graphs, and a key value. The data models (conceptual, logical, and physical) used in the developed process comply with the meta-models: from conceptual to logical stage, followed by from logical to physical stage. The offered solution should be implemented in the form of a hardware-in-the-loop complex that utilizes the described methodology for integrating the information flows from various situational centers. This would ensure the adaptive dynamic transformation of incoming data and their further use within the situational center.
Keywords:
data integration, intelligent situational centers, data processing, data analysis, data structuring, situation center consolidation, information flow consolidation, data models, meta-models, NoSQL
Введение
В настоящее время существуют отдельные подходы к формированию единого информационного пространства для доступа из различных информационных ресурсов, которые представлены в виде сформированных вручную уникальных алгоритмов преобразования таблиц из различных источников. Такой подход вызывает потребность в наращивании организационных ресурсов при появлении новых значительных объемов неструктурированной информации, что приводит к экономическим и операционным потерям, что невозможно в условиях функционирования интеллектуального ситуационного центра.
Таким образом, существует необходимость совершенствования методических положений объединения информационных ресурсов из различных источников для решения различных прикладных задач.
Исследование зарубежной литературы [1–4] по данной тематике показывает, что научные изыскания направлены на автоматическое приведение данных к единой структуре. Однако разнообразие имеющихся типов данных не позволяет сформировать единый подход для обработки получаемой информации (рис. 1).
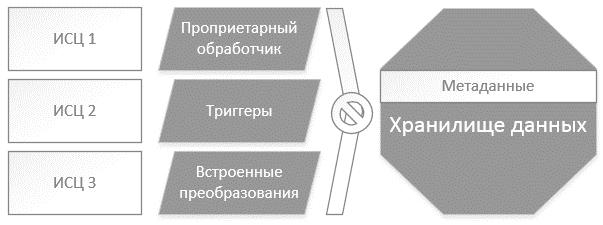
Рис. 1. Представление данных
Целью данной работы является формирование методики объединения информационных ресурсов из различных источников для решения задач интеллектуального ситуационного центра, что необходимо и важно при обработке больших объемов неструктурированной информации.
1. Модели и типы данных
Для достижения поставленной цели в работе требуется осуществить исследование неструктурированных информационных потоков и их структуры, выделить особенности и модели таких данных, изучить возможности преобразования в различные формы представления.
Модель данных — это схема описания структуры данных для конечного потребителя (приложения, базы данных). Модель содержит типы и структуры, совокупность операций, накладываемые на типы ограничения [5].
Структурированные данные имеют определенные ограничения для каждого атрибута, которые усложняют модификацию модели в соответствии с новыми требованиями. Структура таких данных определена с помощью схем данных, автоматическое преобразование затруднительно [6].
Слабоструктурованные данные имеют неполную структуру, имеют исключения, значения скалярных полей зачастую представлены в виде текстовой информации. Дополнительно возникает проблема определения принадлежности данных, требуется дополнительная верификация идентифицированного документа.
Неструктурированные данные представлены полностью отсутствующей структурой и ограничениями применимых операций с ними. Автоматическое изменение структуры таких данных не может быть выполнено.
Представление накопленной информации в преломлении к каждому типу данных (структурированных, полуструктурированных, неструктурированных) показано на рис. 2 [7].
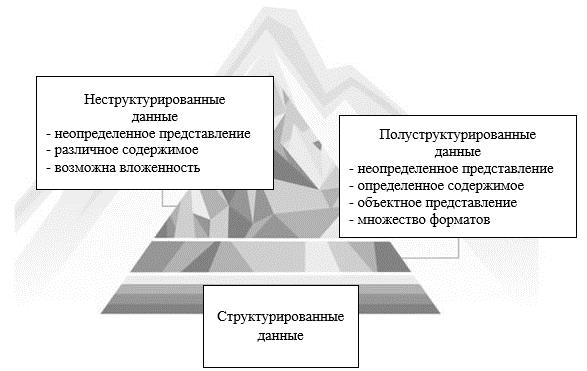
Рис. 2. Схема данных
В слабоструктурованных данных атрибуты могут быть сформированы в виде текста, следовательно, необходим надежный механизм проверки сопоставления данных конкретному атрибуту. Схема может не в полной мере отвечать обрабатываемой информации [2, 8]. Работать с документом, не имея представлений о его структуре, затруднительно, возникает задача определения схемы обрабатываемых массивов информации, их распознавания в процессе использования модели для получения новой информации. Дополнительно атрибуты могут не существовать или не удовлетворять условиям корректности данных, заданным для этих атрибутов. Таким образом, в формируемой модели должны использоваться инструменты обработки исключений, который позволят установить структуру запроса к таким данным, используя заданные критерии.
Для перехода к единому информационному пространству необходимо использовать общую модель данных универсального хранилища [9, 14], которая формируется последовательно и состоит из концептуальной, логической и физической модели данных. Переход между моделями осуществляется последовательно.
Концептуальная модель универсального хранилища данных рассматривается как описание основных объектов и связей между ними [10]. Концептуальная модель отражает предметную область в рамках планируемого универсального хранилища данных [11, 12].
Логическая модель расширяет концептуальную путем определения сущностей атрибутов, их описаний и ограничений, уточняет состав сущностей и взаимосвязи между ними.
Физическая модель данных описывает реализацию объектов логической модели на уровне объектов конкретной базы данных, на ней строится взаимодействие подсистем виртуального уровня и уровня приложений (рис. 3).
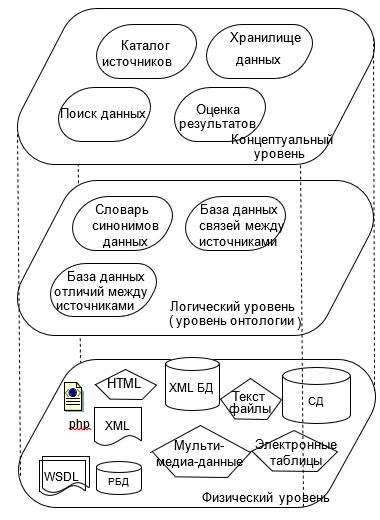
Рис. 3. Уровни реализации физической модели пространства данных
2. Информационное пространство
Для работы с неструктурированной или слабоструктурированной информацией требуется сформировать информационное пространство [13, 14] для определения конечного вида представления данных, который имеет необходимый функционал и является удобным для использования данных.
Поскольку для формирования ассоциаций между объектами и характеристиками необходимо работать с разными источниками данных, в которых один и тот же объект может быть представлен под разными названиями, для сравнения схем источников данных целесообразно использовать пространство данных с каталогом данных и словарем данных для сравнения названий объектов.
Каждый участник пространства данных поддерживает модель данных и язык запросов, соответствующий формируемой модели. Запрос к такому программному средству поддерживается в файловых системах относительно директорий: сопоставление имен, поиск в диапазоне дат, сортировка по размеру файла и др. На следующем уровне пространства данных модель данных должна поддерживать мультимножение слов с целью осуществления эффективного поиска необходимой информации по ключевым словам. Ниже уровня модели мультимножения слов в иерархии может располагаться модель слабоструктурированных данных, основанная на обозначенных графах. Поскольку источники данных разнотипные, необходимо определить платформу и архитектуру хранилища данных.
Платформа поддержания хранилища данных — это набор программного обеспечения для хранения и поиска данных в информационном пространстве [15].
Архитектура пространства данных спроектирована уровнями (рис. 3). Уровень приложений предназначен для реализации операций над данными в пространстве данных. Уровень онтологий используется для установления связи между источниками.
Последний уровень содержит источники данных и обеспечивает доступ к данным и выполнению операций уровня применений непосредственно в источнике (например, операция выборки на уровне реализации выполняется как запрос в конкретной базе данных).
3. Алгоритм перехода от объекта к модели NoSQL
Для обеспечения последовательного перехода от объекта данных (неструктурированных данных) к физической модели необходимо создать алгоритм перехода от объекта к конкретному представлению данных, что можно реализовать в виде модуля, который отвечает за преобразование в физическую модель NoSQL. В соответствии с обоснованием введен логический промежуточный уровень между концептуальным и физическим уровнями. Этот уровень направлен на техническое описание структуры данных без указания характеристик, характерных для каждой СУБД. Другими словами, модуль Object-to-NoSQL работает в два последовательных шага: концептуальный > логический, а затем логический > физический. Переход от одной модели к другой осуществляется с использованием преобразований типа M2M, формализованных в QVT.
Элемент модуля Object-to-NoSQL представляет собой диаграмму классов. Пользователь предоставляет входную группу данных, конкретизируя концептуальную мета-модель PIM. Данная мета-модель показывает основные элементы, составляющие модель данных, а также их структурные характеристики.
Окончательный результат, возвращаемый модулем Object-to-NoSQL, представляет собой физическую модель NoSQL (колонки, документы, графики или значение ключа), которая включает в себя:
· Модель данных, содержащую необходимые элементы для реализации базы данных NoSQL.
· Набор руководящих принципов, определяющих условия использования атрибутов и реализации отношений в соответствии с приемами, присущими выбранной СУБД NoSQL.
Очевидно, что для заданного вывода (физической модели NoSQL) необходимо сохранить его параметры, т.е. его мета-модель и правила преобразования, которые позволяют его генерировать. Для иллюстрирования работы выбрано производство физических моделей с очень четкими характеристиками, используя СУБД Cassandra, SSDB, Neo4j и Redis. Если пользователь хочет использовать другую СУБД, модуль необходимо дополнить новыми параметрами, специфичными для этой системы.
Модуль Object-to-NoSQL состоит из двух преобразований: Object-to-GenericModel и GenericModel-to-PhysicalModel. На первом этапе входная DCL трансформируется в общую NoSQL модель, соответствующую логической PIM-модели. На втором этапе в качестве входной информации принимается общая модель и генерируются элементы, необходимые для реализации БД, а также набор руководящих принципов поддержки, специфичных для выбранной СУБД NoSQL. Эти два преобразования выполняются набором правил M2M, формализованных в QVT, таким образом два преобразования бесшовно связаны между собой.
Стоит обратить внимание, что модуль преобразования DCL способен преобразовывать DCL в физическую модель [13] для одной из платформ реализации NoSQL: столбцов, документов, графиков и ключевых значений. Как уже упоминалось выше, в этой работе рассмотрены СУБД NoSQL каждого типа: Cassandra для колонок, SSDB для документов, Neo4j для графиков и Redis для ключей/значений. Выбранное решение совместимо и с другими СУБД NoSQL, такими как HBase (ориентированная на столбцы) и CouchDB (ориентированная на документы).
Рассмотрим этапы реализации модуля преобразования Object-to-NoSQL. Эта реализация требует предварительного определения набора мета-моделей и правил преобразования М2М-типа.
Сначала необходимо создать мета-модели ECORE. Это мета-модели концептуального MIP, логического MIP для Cassandra, SSDB, Neo4j и Redis. Эти мета-модели описывают, соответственно, структуру UML MCI, общую NoSQL модель и физические модели Cassandra, SSDB, Neo4j и Redis.
Используем язык QVT для реализации правил преобразования, обеспечивающих два прохода: концептуальный к логическому и логический к физическому. Предложим следующие шаги:
После формализации концепций, присутствующих в исходной модели (UML Class Diagram) и в целевой модели (Generic NoSQL model) преобразования UML-to-GenericModel, здесь представлен автоматический переход от концептуального PIM к логическому PIM. Этот переход выполняется цепочкой преобразований:
1. Шаг 1: Каждая диаграмма класса DCL преобразуется в базу данных, где BD.N = DCL.N.
2. Шаг 2: Каждый класс c ∈ C преобразуется в таблицу t ∈ T, где t.N = c.N:
a. каждый атрибут класса ac ∈ c.Ac преобразуется в табличный атрибут at, где at.N = ac.N, at.Ty = ac.C, а затем добавляется в список атрибутов его преобразованного контейнера t, который at ∈ t. At;
b. идентификатор объекта c трансформируется в идентификатор строки t, где Idt.N = Idc.N и Idt.Ty = Rid, затем добавляется в список t атрибутов типа 𝐼𝑑𝑡 ∈ t.At.
3. Шаг 3: Каждая связь l ∈ L степени 2, связывающая два класса c1 и c2, трансформируется в связь r ∈ R, связывающую таблицы t1 и t2, соответствующие классам c1 и c2, где r.N = l.N, r. Cpr = {(t1, 𝑐𝑟𝑐1),( t2, 𝑐𝑟𝑐2 )}.
4. Шаг 4: Каждое соединение l ∈ L степени n (при n > 2) приводит к (1) появлению новой таблицы tl с собственным идентификационным атрибутом 𝐼𝑑tl, где tl.N = l.N, tl.A = {Idtl} и (2) набор из n двоичных связей {r1, ... , rn }, ∀ i ∈ [1..n] ri связывает tl в другую таблицу tl, соответствующую родственному классу ci , где ri.N = (tl.N)_(ti.N) и ri. Cpr = {(tl, null), (ti, null)}.
5. Шаг 5: Каждый класс cаssо ассоциаций между n классами {c1, ... , cn} (с n ≥ 2) трансформируется как звено степени строго выше 2 в (1) новую таблицу tаssо, где tаssо.N = l.N, tаsso.A = cаssо.Ааssо и (2) набор n двоичных отношений {r1, ... , rn}, ∀ i ∈ [1...n] ri связывает tаssо с другой таблицей ti, соответствующей родственному классу ci, где ri.N = (tasso.N)_(ti.N) и ri. Cpr = {(tаssо, null), (ti, null)}.
Окончательный результат состоит из модели данных, содержащей элементы, необходимые для реализации БД, и набора руководящих принципов, специфичных для СУБД SSDB.
Преобразование объекта в общую модель (1) является первым шагом в процессе Object-to-NoSQL. Он транслирует диаграмму входного класса UML в общую модель NoSQL (2); эта модель соответствует логической PIM-модели. Преобразование общей модели в физическую (3) является вторым этапом, который генерирует физические модели NoSQL (PSM) (4) и набор ограничений (5) из общей модели.
Выводы
В результате исследования существующих методов объединения различных источников информации выявлена проблема отсутствия принципиальных подходов к интеграции данных в единое информационное пространство.
На основе рассмотрения действующих моделей преобразования информации построен подход к интеграции информации в виде модели «объект-характеристика», которая дает возможность обрабатывать данные разных форматов.
Решена задача определения модели ассоциации объектов и характеристик основных представлений данных. Построена новая информационная структура интеллектуального ситуационного центра.
Разработаны инструменты многоуровневого преобразования информации, которые состоят из цепочки преобразований с использованием общей модели, расположенной на промежуточном уровне между DCL (концептуальным уровнем) и моделью реализации информации в базы данных (физическим уровнем).
Предложена методика формирования физических моделей информации из разнородной неструктурированной и слабоструктурированной информации. Эта методика совместима с четырьмя типами СУБД NoSQL: колонками, документами, графиками и ключевым значением.
Модели данных (концептуальные, логические и физические), используемые в разработанном процессе, соответствуют мета-моделям, которые предложены для выполнения целей рассмотренных этапов: от концептуального к логическому, а затем от логического к физическому.
References
1. Silverston L. (2001) The Data Model Resource Book, Revised Edition. Volume 1: A Library of Universal Data Models for All Enterprises. — John Wiley & Sons, New York, 2001. — 542 p. — ISBN 978-0-471-38023-8.
2. Hay D. C. (2011) Enterprise Model Patterns: Describing the World (UML Version). — Technics Publications, LLC, Bradley Beach, USA, 2011. — 532 p. — ISBN 978-1-9355040-5-4.
3. Blaha M. (2010) Patterns of Data Modeling (Emerging Directions in Database Systems and Applications). — CRC Press, Washington, 2010. — 261 p. — ISBN 978-1-4398198-9-0.
4. Fowler M. (1996). Analysis Patterns: Reusable Object Models. — Addison-Wesley Professional, 1996. — 384 p. — ISBN 978-0-201-89542-1.
5. Simankov V. S., Drilenko M. V. (2020) Metodicheskie osnovy vybora platform predstavleniya informatsii v intellektual'nom situatsionnom tsentre // Sovremennaya nauka: aktual'nye problemy teorii i praktiki. Seriya: Estestvennye i Tekhnicheskie Nauki. — 2020. — №8. — S. 108–112. — ISSN 2223-2966. — DOI: 10.37882/2223-2966.2020.08.30.
6. Simankov V. S., Drilenko M. V. (2020) Metodicheskie osnovy preobrazovaniya informatsionnykh potokov ot kontseptual'noi k fizicheskoi modeli dannykh v intellektual'nom situatsionnom tsentre // Perspektivy nauki. — 2020. — №7 (130) — S. 39–43. — ISSN 2077-6810.
7. Levin N. A., Munerman V. I., Sergeev V. P. (2004) Algebra mnogomernykh matrits kak universal'noe sredstvo modelirovaniya dannykh i ee realizatsiya v sovremennykh SUBD // Sistemy i sredstva informatiki. Moskva: Nauka. — 2004. — Vyp. 14. — S. 86–99. — ISBN 5-02-032836-7.
8. Magoulas R., Lorica B. (2009) Big data: Technologies and techniques for large scale data // Jimmy Guterman, Release 2.0. — Issue 11. — O'Reilly Media, Inc., 2009. — ISBN 9780596520540.
9. Dittrich J. P., Kossmann D., Kreutz A. (2005) Bridging the gap between OLAP and SQL // Proceedings of the 31st International Conference on Very Large Data Bases. Trondheim, Norway, August 30 – September 2, 2005. — p. 1031–1042. — ISBN 978-1-59593-154-2.
10. Hooman J., van de Pol J. Equivalent semantic models for a distributed dataspace architecture // International Symposium on Formal Methods for Components and Objects. — Springer, Berlin, Heidelberg, 2002. — p. 182–201. — ISBN 978-3-540-20303-2. — DOI: 10.1007/978-3-540-39656-7_7.
11. The Open Archives Initiative Protocol for Metadata Harvesting Protocol Version 2.0 of 2002-06-14. [Elektronnyi resurs]. URL: http://www.openarchives.org/OAI/openarchivesprotocol.html (data obrashcheniya 20.10.2020).
12. Kumarasinghe C. U., Liyanage K. L. D. U., Madushanka W. A. T., Mendis R. A. C. L. (2015) Performance Comparison of NoSQL Databases in Pseudo Distributed Mode: Cassandra, MongoDB & Redis. [Elektronnyi resurs]. URL: https://www.researchgate.net/profile/Tiroshan_Madushanka/publication/281629653_Performance_Comparison_of_NoSQL_Databases_in_Pseudo_Distributed_Mode_Cassandra_MongoDB_Redis/links/55f113ba08aedecb68ffd294/Performance-Comparison-of-NoSQL-Databases-in-Pseudo-Distributed-Mode-Cassandra-MongoDB-Redis.pdf (data obrashcheniya 20.10.2020).
13. Cooper B. F., Silberstein A., Tam E., Ramakrishnan R., Sears R. (2010) Benchmarking cloud serving systems with YCSB. // Proceedings of the 1st ACM symposium on Cloud computing (SoCC ’10). — Association for Computing Machinery, New York, NY, USA, 2010. — p. 143–154. — DOI: 10.1145/1807128.1807152.
14. Chinonso O., Osemwegie O., Okokpujie K., John S. (2017) Development of an Encrypting System for an Image Viewer based on Hill Cipher Algorithm // Covenant Journal of Engineering Technology. — 2017. — Volume 1. — № 2. — p. 65–73. — ISSN 2682-5325.
15. Inmon W. H. (2005) Building the Data Warehouse. 4th Edition. — John Wiley & Sons, Indianapolis, 2005. — 576 p. — ISBN 978-0-76459944-6.
|







