|
Software systems and computational methods
Reference:
Pesoshin, V.A., Kuznetsov, V.M., Rakhmatullin, A.K. (2019). Synthesis and analysis of search algorithms for a set of inverse-segment sequences with a given period. Software systems and computational methods, 3, 73–84. https://doi.org/10.7256/2454-0714.2019.3.30541
Synthesis and analysis of search algorithms for a set of inverse-segment sequences with a given period
Pesoshin Valerii Andreevich
Doctor of Technical Science
Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University (KAI)
420111, Russia, respublika Tatarstan, g. Kazan', ul. K.marksa, 10

|
pesoshin-kai@mail.ru
|
|
 |
Kuznetsov Valerii Mikhailovich
Doctor of Technical Science
Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University (KAI)
420111, Russia, respublika Tararstan, g. Kazan', ul. K.marksa, 10
|
|
kuznet_evm@mail.ru
|
|
 |
|
Rakhmatullin Arslan Khanafievich
Master of the Department of Information Security Systems of Tupolev Kazan National Research Technical University (KAI)
420111, Russia, respublika Tararstan, g. Kazan', ul. K.marksa, 10
|
|
arslan.rahmatullin@outlook.com
|
|
 |
|
DOI: 10.7256/2454-0714.2019.3.30541
Received:
14-08-2019
Published:
08-09-2019
Abstract:
The problem of synthesis of search algorithms for a set of inverse-segment sequences with a given period is considered. Inverse-segment sequences are pseudorandom sequences having the likelihood of the occurrence of symbols 0 and 1 and the variety of their autocorrelation functions. In hardware implementation, the most widely used are inverse-segment sequences formed by pseudorandom sequence generators based on an n-bit shift register with linear feedbacks. To use inverse-segment sequences in applied problems, as well as further study of their properties, it is necessary to solve the problem of finding a set of inverse-segment sequences with a given period, and the number of disjoint sequences increases significantly with increasing n. A number of basic approaches to the synthesis of inverse-segment sequence search algorithms are considered, and the analysis of the obtained algorithms, their algorithmic complexity, and memory consumption are carried out. Inverse segment sequences are of practical interest due to the equiprobability of the occurrence of symbols 0 and 1 and the variety of their autocorrelation functions. A number of algorithms for finding inverse-segment sequences with a given period, with the principle of enumerating the initial states of the shift register at the base, are investigated. All the considered algorithms use an abbreviated method of storing inverse segment sequences in various data structures using the number of one-to-one given inverse segment sequences. Studied their algorithmic complexity and memory consumption. Recommendations have been made for choosing an algorithm for searching inverse-segment sequences and the synthesis of new algorithms.
Keywords:
inverse-segmental sequences, pseudo-random number generators, shift register, Bloom Filter, autocorrelation, algorithm analysis, optimization, computational complexity, red-black trees, probabilistic data structures
1. Введение
Инверсно-сегментные последовательности (ИСП) представляют практический интерес благодаря равновероятности появления символов 0 и 1 и многообразию их автокорреляционных функций. При аппаратурной реализации наибольшее распространение получили ИСП, формируемые генераторами псевдослучайных последовательностей (ГПСП) на основе n-разрядного регистра сдвига с линейными обратными связями [1]. Работа этих устройств основана на рекуррентном правиле формирования последовательности а с дискретным временны́м аргументом t:
 , (1) , (1)
где для двоичного случая  , ,  . Периодические свойства ИСП определяются характеристическим многочленом . Периодические свойства ИСП определяются характеристическим многочленом 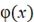 степени n в разложимой форме степени n в разложимой форме
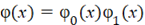 , (2) , (2)
где
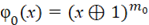 , (3) , (3)
причём 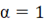 , а многочлен , а многочлен 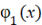 степениm1 примитивен ( степениm1 примитивен (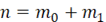 ). ).
Для многочлена 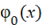 степениm0 при степениm0 при 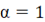 периодическая структура (ПС) определится как периодическая структура (ПС) определится как
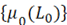 , (4) , (4)
где 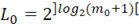 – длина периода, а – длина периода, а 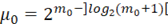 – количество периодов, ]z[ означает ближайшее большее целое число или равное z, если z целое число. – количество периодов, ]z[ означает ближайшее большее целое число или равное z, если z целое число.
Если 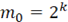 , где k – натуральное число, то , где k – натуральное число, то 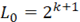 и в соответствии с формулой Шенемана и в соответствии с формулой Шенемана
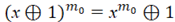 . (5) . (5)
При аппаратурной реализации многочлену (5) при условии 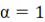 соответствует m0-разрядный счетчик Джонсона (кольцевой счетчик с инверсной обратной связью). Он формирует ИСП с периодом 2m0 [1]. В таблице 1 приведены ПС соответствует m0-разрядный счетчик Джонсона (кольцевой счетчик с инверсной обратной связью). Он формирует ИСП с периодом 2m0 [1]. В таблице 1 приведены ПС 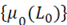 многочлена (5) для многочлена (5) для  , ,  . .
Таблица 1
ПС многочлена (5) для , .
|
k
|
0
|
1
|
2
|
3
|
4
|
5
|
|
m0
|
1
|
2
|
4
|
8
|
16
|
32
|
|
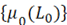
|
{1(2)}
|
{1(4)}
|
{2(8)}
|
{16(16)}
|
{2 048(32)}
|
{67 108 864(64)}
|
Для использования ИСП в прикладных задачах, а также дальнейшего исследования их свойств, необходимо решить задачу нахождения множества ИСП с заданным периодом 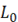 , причем количество , причем количество 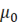 существенно увеличивается с ростом k. существенно увеличивается с ростом k.
2. Постановка задачи
В данной работе рассматриваются алгоритмы поиска множества ИСП, в основу которых положена идея последовательного перебора всех возможных начальных состояний регистра сдвига и определения того, является ли очередное состояние регистра элементом какой-либо из уже найденных ИСП.
При решении данной задачи возникает существенная проблема: необходимо быстро определять, генерирует ли данное начальное состояние регистра сдвига ранее найденную ИСП, либо совершенно новую, ранее не встреченную. Ниже рассмотрен ряд базовых подходов к синтезу алгоритмов поиска ИСП, а также проводится анализ полученных алгоритмов, их алгоритмическая сложность, потребление памяти.
3. Представление инверсно-сегментных последовательностей
Базовая подзадача, которую необходимо решить в каждой из предложенных далее алгоритмов – это форма представления ИСП, позволяющая быстро проверить, является ли данное начальное состояние частью, данной ИСП. Существует два подхода к решению данной подзадачи.
Первый подход: хранить в используемой структуре данных всю ИСП, тогда проверка сводится к задаче поиска вхождения подстроки (данное начальное состояния регистра сдвига) в строке (ИСП). Асимптотика сложности поиска подстроки в худшем случае О(MN), где M – длина ИСП, N – длина регистра сдвига, поскольку сравнения N элементов подстроки и строки выполняется относительно каждого последовательного начального элемента сравнения, т.к. M=2N, получаем O(N2), а также потребление памяти O(N) при хранении ИСП в используемой структуре данных [2].
Второй подход: поставить в соответствие каждому ИСП некоторое число, однозначно соответствующее одной и только одной ИСП заданной длины. Одно из возможных решений – это использование минимального, либо максимального числа ИСП, поскольку найти ИСП можно по одному члену последовательности путем линейного сдвига, и только её, так как различные ИСП заданной длины содержат различные члены. Таким образом, данная подзадача сводится к задаче нахождению минимального члена последовательности по одному из известных членов. Асимптотика сложности поиска минимального, либо максимального, члена ИСП O(N2), так как включает операцию линейного сдвига, выполняемую за O(N), и операции сравнения, выполняемой за O(N) на каждый сдвиг. Поскольку в используемой структуре данных достаточно хранить всего один член последовательности, а не всю ИСП, потребление памяти сводятся к O(N).
Из сравнения данных алгоритмов получаем, что второй алгоритм является более эффективным по затратам памяти, так как при равной асимптотике О(N) разница в скрытой константе позволяет сократить потребления памяти в два раза, поскольку на каждый элемент приходится 2N=M, в связи с чем в нижеизложенных алгоритмах поиска ИСП использоваться будет именно он.
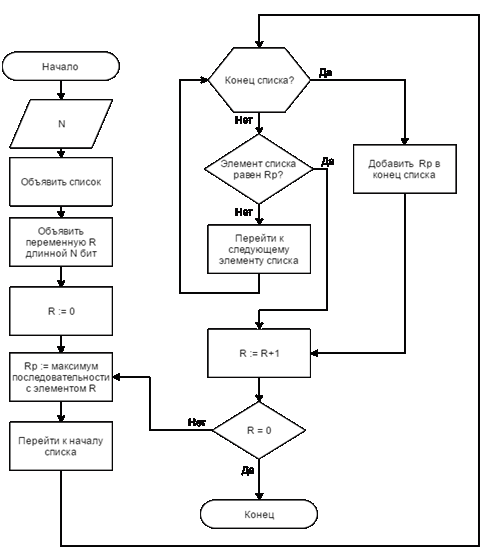
4. Алгоритм простых сравнений
Наиболее простым решением задачи ИСП является использование двунаправленного списка для хранения уже найденных ИСП и поочередное сравнивание с ними каждого следующего начального состояния регистра. Блок-схема алгоритма простых сравнений представлена на рисунке 1. Алгоритмическая сложность поиска – O(N), сложность добавления нового ИСП в список – O(1), используемая память – O(N) [2]. Необходимо перебрать R=2N начальных состояний и сравнить с 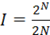 ИСП, в результате получаем сложность алгоритма: ИСП, в результате получаем сложность алгоритма:
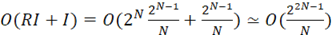 . (6) . (6)
Рисунок 1. Блок-схема алгоритма простых сравнений
5. Алгоритм бинарного поиска
Улучшения асимптотики роста алгоритмической сложности, по сравнению с предыдущим алгоритмом, можно добиться заменой двунаправленного списка на сортированный массив. Блок-схема алгоритма бинарного поиска приведена на рисунке 2. В данном случае улучшение достигается за счет увеличения скорости поиска элементов в массиве – O(log(N)). Вставка в сортированный массив выполняется медленнее – 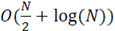 , но вставок в 2N раз меньше, чем операций поиска [3]. Таким образом, алгоритмическая сложность , но вставок в 2N раз меньше, чем операций поиска [3]. Таким образом, алгоритмическая сложность
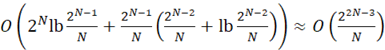 , (7) , (7)
где 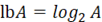 . .
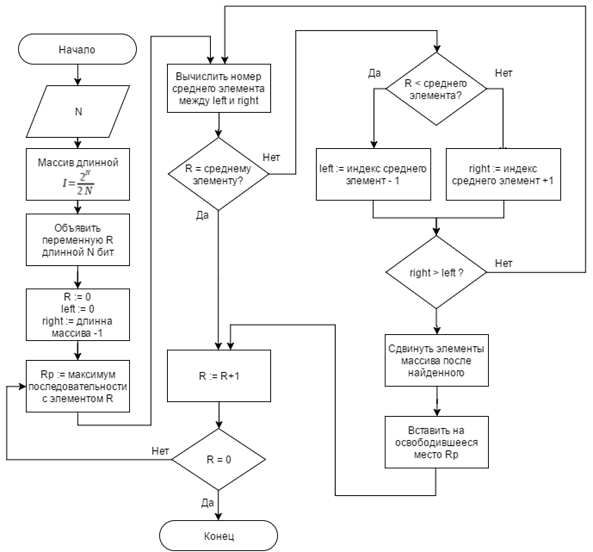
Рисунок 2. Блок-схема алгоритма бинарного поиска
6. Алгоритм поиска на множестве
Поскольку при решении задачи поиска ИСП необходимо выполнять большое количество операций проверки очередной ИСП на принадлежность множеству уже найденных ИСП, имеет смысл использовать специализированную структуру данных для хранения множеств. Данные структуры в своей основе могут иметь красно-черные деревья, либо массив, индекс очередного элемента в котором определяется хеш-функцией [4]. Блок-схема алгоритма множества с красно-черным деревом приведена на рисунке 3.
Рассмотрим множество на основе красно-черного дерева: добавление нового элемента в структуру данных выполняется за O(log(N)), проверка вхождение элемента в множество выполняется за O(log(N)). [4] Таким образом, сложность алгоритма
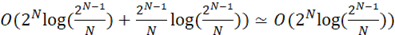 . (8) . (8)
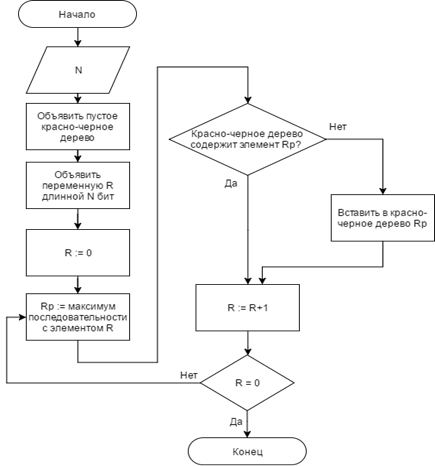
Рисунок 3. Блок-схема алгоритма множества с красно-черным деревом
Следующий вариант реализации множества содержит хеш-функцию, выполняющую проекцию некоторого входного множества в конечное, счетное множество(блок-схема алгоритма множества с хеш-функцией представлена на рисунке 4). Как и все выше представленные структуры данных, множество на основе хеш-функции имеет стандартную реализацию в языке программирования высокого уровня, сложность добавления нового элемента и поиска вхождения элемента в множество выполняется за O(1), но при использовании хеш-функции существует вероятность возникновения коллизий, т.е. различные входные значения проецируются на одно и тоже значение. Для выявления коллизий используются однонаправленные списки, каждый из которых соответствует одному из возможных значений хеш-функции и только ему. Таким образом, при большем количестве коллизий скорость поиска деградирует до O(N), для исключения данной ситуации необходимо выделять в 3-4 раза больший объем памяти, чем требуется для хранения всех возможных ИСП заданной длины [5]. Таким образом, алгоритмическая сложность
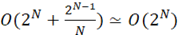 . (9) . (9)
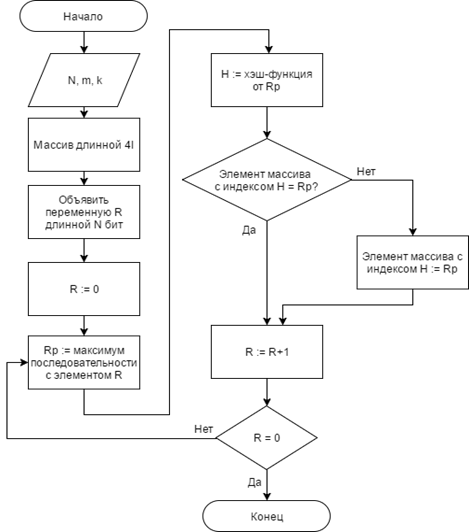
Рисунок 4. Блок-схема алгоритма множества с хеш-функцией
7. Поиск с использованием Фильтра Блума
Особая обособленная группа алгоритмов – это вероятностные алгоритмы, либо вероятностные структуры данных. Особенность этих алгоритмов заключается в том, что присутствует вероятность возникновения ошибок, но благодаря несогласованности данных возрастает скорость работы либо уменьшается потребление памяти. К числу таких алгоритмов относится и Фильтр Блума.
Фильтр Блума был придуман Бертоном Блумом в 1970 году, эта структура данных позволяет сократить потребление памяти. Фильтр Блума предоставляет возможность проверять, встречался ли уже данный элемент, причем существует вероятность ложноположительного ответа, но не ложноотрицательного. Определение объема выделяемой памяти осуществляется в соответствии с требованием к вероятности возникновения ошибок, т.к. она определяется длинной выделяемого битого массива, лежащего в основе Фильтра Блума. На рисунке 5 представлена блок-схема алгоритма поиска с Фильтром Блума.
Выделяемый массив длинной m бит приравнивается нулю, определяется k различных хеш-функций (в большинстве случаев используется линейная комбинация MD5, SHA), проецирующие входное множество в конечное множество значение 1...m [6]. При добавления нового элемента вычисляется k хеш-функций yi=hi(x), где x – очередной член ИСП, i – номер хэш-функции от 1 до k, и выставляются единицы в массиве с номерами yi. При проверке элемента на вхождение в множество, так же вычисляются k хеш-функций, в большинстве случаем используют линейную комбинацию произвольных хеш-функций, и проверяется, проставлены ли единицы в элементах массива с номерами yi. Если существует элемент массива с номерном yi, равный нулю, то проверяемое значение не встречалось ранее, в обратном случае, элемент был встречен ранее, но с вероятностью 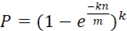 возможен ложный ответ [6]. Сложность алгоритма поиска ИСП с Фильтром Блума возможен ложный ответ [6]. Сложность алгоритма поиска ИСП с Фильтром Блума
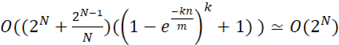 . (10) . (10)
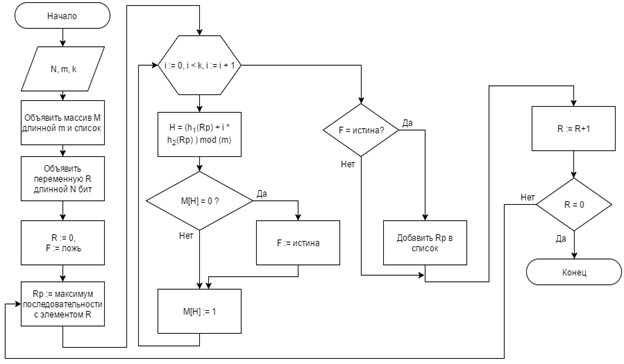
Рисунок 5. Блок-схема алгоритма поиска с Фильтром Блума
8. Сравнение алгоритмов поиска множества инверсно-сегментных последовательностей с заданным периодом
Сравнение рассмотренных алгоритмов приведено в таблице 2.
Таблица 2
Сравнение рассмотренных алгоритмов
|
Алгоритм
|
Сложность
|
Потребление
памяти
|
|
Простые сравнения
|
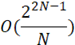
|
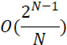
|
|
Бинарный поиск
|
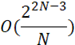
|
|
|
Множество с бинарным деревом
|
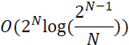
|
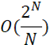
|
|
Множество с хеш-функцией
|
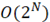
|
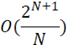
|
|
Фильтр Блума
|
|
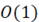
|
Алгоритмы простых сравнений и бинарного поиска серьезно проигрывают остальным алгоритмам: их использование, в сравнение с множествами и Фильтром Блума, связано с высокой скоростью роста функции алгоритмической сложности, но при этом позволяет сократить потребление памяти в два раза. Следовательно, эти алгоритмы подходят только для относительно небольших N.
Выбор между различными реализациями множества связан с приоритетным ресурсом (с временем выполнения, либо с потреблением памяти), использование которого необходимо минимизировать в первую очередь. Множество с бинарным деревом в основе дает преимущество в потреблении памяти, а множество с хеш-функциями в основе дает преимущество в скорости.
Фильтр Блума позволяет значительно уменьшить потребление памяти в тех задачах, где допускается заранее заданная вероятность возникновения ошибок в списке найденных ИСП. Поскольку Фильтр Блума допускает только ложноположительные ответы, конечное множество ИСП будет с вероятностью
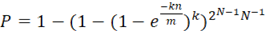 (11) (11)
неполно, в соответствии с формулой Бернулли [7].
Приведем пример проверки некоторой последовательности w в Фильтре Блума с m = 18,k = 3, хранящего некоторое множество найденных последовательностей {x, y, z}. На рисунке 7 приведена проверка вхождения w в множество {x, y, z} Фильтра Блума.
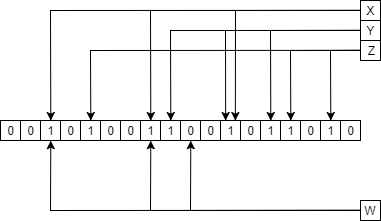
Рисунок 7. Проверка вхождения w в множество {x, y, z} Фильтра Блума.
Стрелками от элементов множества {x, y, z} показаны элементы Фильтра Блума, выставленные по результатам применения k хэш-функций к элементам множества. При проверке элемента вхождения w в множество {x, y, z} так же вычисляются k хэш-функций, в результате получаем набор адресов элементов фильтра, которые должны быть выставлены, если данный элемент находится в множестве. В данном примере один из проверяемых элементов фильтра не выставлен, из чего следует, что результат применения одной из k хэш-функций kiвстречается впервые, из чего следует, что хэш-функций ki к wне применялась и wне является членом множества {x, y, z}.
В свою очередь, если бы все k хэш-функций, примененные к w, указывали на выставленные элементы фильтра, то это могло означать как то, что они были выставлены в результате применения k хэш-функций к w, так и комбинации результатов применения k хэш-функций в элементах множества, хранящихся в Фильтре Блума. В этом и заключается принцип возможности ложноположительных, но не ложноотрицательных ответов.
9. Полученные результаты
Используя алгоритм поиска с Фильтром Блума, была реализована программа на языке программирования Java синтеза множества ИСП с заданным периодом.
Тестирование программы проводилось на аппаратной платформе со следующими характеристиками:
· Центральный процессор: Intel Core i3-3220, 3,30 ГГц;
· Оперативная память: DDR3‑1600, 12 Гб;
· Постоянная память: Samsung MZ-75E, объем 240 Гб, скорость чтения 530 Мб/с, скорость записи 270 Мб/с.
Использовалась следующая программная платформа:
· Операционная система: Windows 10 Pro, версия 1804;
· Язык программирования: Java Development Kit 1.8.
В реализации алгоритма поиска с Фильтром Блума использовались m = 1 800 000,k = 300 000. В процессе работы состояние Фильтра сохранялось в файл, результаты поиска ИСП записывались в файл в формате TXT.
Тестирование реализованной программы проводилось для m0 = 16 и m0 = 32.
Случай m0 = 16. В этом случае многочлен  порождает 2048 равновероятностных ИСП с периодом 32: порождает 2048 равновероятностных ИСП с периодом 32:
1. ,00000000000000001111111111111111,… {16};
2. ,00000000000000101111111111111101,… {14,1,1};
3. ,00000000000001001111111111111011,… {13,1,2};
4. ,00000000000001101111111111111011,… {13,2,1};
5. ,00000000000010001111111111111011,… {12,1,3};
…………………………………………………….
2048. ,10101100110100100101001100101101,… {1,1,1,1,2,2,2,1,1,2,1,1}.
Время выполнения программы составило 9 с. Файл с полученными ИСП занимает 14 Кб.
При m0 = 32 формируются 67 108 864 равновероятностных ИСП с периодом 64:
1. ,0000000000000000000000000000000011111111111111111111111111111111,… {32};
2. ,0000000000000000000000000000001011111111111111111111111111111101,… {30,1,1};
3. ,0000000000000000000000000000010011111111111111111111111111111011,… {29,1,2};
4. ,0000000000000000000000000000011011111111111111111111111111111001,… {29,2,1};
5. ,0000000000000000000000000000100011111111111111111111111111110111,… {28,1,3};
………………………………………………………………………………………
67108864. ,1010110011010010010100110010110110101100110100100101001100101101,… {1,1,1,1,2,2,2,1,1,2,1,1,1,1,1,1,2,2,2,1,1,2,1,1};
Время выполнения программы составило 8 мин. 42 с. Файл с полученными ИСП занимает 693 Мб.
Представляет интерес прогрессивный рост мощности множества ИСП при увеличении n, в особенности для получения ПСП с необходимой автокорреляционной функцией.
10. Заключение
Исследован ряд алгоритмов нахождения ИСП с заданным периодом на основе принципа перебора начальных состояний регистра сдвига. Все рассмотренные алгоритмы применяют сокращенный способ хранения ИСП в различных структурах данных с использованием числа взаимно однозначного данной ИСП. Изучена их алгоритмическая сложность и потребление памяти. Выработаны рекомендации к выбору алгоритма поиска ИСП и синтезу новых алгоритмов. Рост количества ИСП 2N от длины регистра сдвига N означает необходимость применения специализированных алгоритмов поиска, позволяющих обеспечить максимальную эффективность потребления памяти и скорости выполнения поиска. Приведены результаты синтеза алгоритмов поиска множества ИСП при m0 = 16 и m0 = 32.
References
1. Kuznetsov V.M., Pesoshin V.A., Shirshova D.V., Generatory ravnove-royatnostnykh psevdosluchainykh posledovatel'nostei nemaksimal'noi dliny na osnove registra sdviga s lineinymi obratnymi svyazyami, AiT. 2016. № 9. S. 136-149.
2. Skiena S., Algoritmy. Rukovodstvo po razrabotke. SPb.: BKhV-Peterburg, 2014. 720 s.
3. Virt N., Algoritmy i struktury dannykh. M.: Mir, 1989. 274 s.
4. R. Tarjan., Efficiency of a good but not linear set union algorithm. J.: ACM, 1975. S. 215-225.
5. Shnaier B., Prikladnaya kriptografiya. M.: Triumf, 2002. 610 s.
6. Bloom, Burton H., Space/time trade-offs in hash coding with allowable er-rors. T.: ACM, 1970. S. 422-426.
7. Kremer N.Sh., Teoriya veroyatnosti i matematicheskaya statistika. M.: YuNITI-DANA, 2004. 573 s.
|