Cybernetics and programming
Reference:
Filgus, D.I. (2018). The method of forming the load on the arcs of the search graph of the shortest Hamiltonian path in relation to solving the problem of scheduling the implementation of multiple transactions and queries in a network database. Cybernetics and programming, 4, 19–34. https://doi.org/10.25136/2644-5522.2018.4.26624
The method of forming the load on the arcs of the search graph of the shortest Hamiltonian path in relation to solving the problem of scheduling the implementation of multiple transactions and queries in a network database
Filgus Dmitry Igorevich
Postgraduate Student, Department of Tool and Applied Software, MIREA - Russian Technological University
119454, Russia, g. Moscow, ul. Prospekt Vernadskogo, 78

|
dmif42@ya.ru
|
|
 |
|
DOI: 10.25136/2644-5522.2018.4.26624
Received:
17-06-2018
Published:
15-09-2018
Abstract:
The subject of the research is network databases of distributed computing systems. The object of the research is the model and scheduling algorithms for the distribution of workload in network databases. The author considers in detail such aspects of the topic as a model for solving the problem of optimizing the process of managing queries in distributed information systems. It is shown that in order to eliminate the queue of requests, it is necessary to choose the most appropriate way to select queries and the best method for implementing the selected method. Promising options for serving queries are group sampling, as well as group sampling with individual segmentation. Special attention is paid to the application and development of a method for solving problems of Boolean linear and nonlinear programming based on the rank approach, which have a small time complexity and provide the required accuracy for solving these problems, as well as developing a common approach to solving arbitrary problems of boolean programming. The research methodology is the methods and models for planning, optimizing and improving the performance of network databases of distributed computing systems. The scientific novelty lies in the fact that an increase in the number of constraints in problems of nonlinear Boolean programming leads to a decrease in the error of their solution, and the degree of nonlinearity itself does not significantly affect the magnitude of the error. From an experimental study of the developed algorithms for solving the problems considered in the work, it follows that in the case of the formalization of Boolean programming problems in graph formulation, in most cases it is possible to reduce the time complexity of the algorithms for solving them. The proposed model can be used to solve the problem of optimizing the process of managing queries in distributed computing systems.
Keywords:
network database, dissipative structures, request, optimization, ranked approach, branch and bound, transaction, deviation, hamiltonian path, algorithm analysis
Введение
Распределенные системы и вычисления в настоящее время являются одними из основных направлений исследований для повышения эффективности обработки данных. Функционирование таких систем характеризуется наличием многих участников – владельцев вычислительных ресурсов, пользователей, провайдеров, обеспечивающих работу коммуникационных каналов, что требует решения задач координации и управления различными компонентами этих систем. Наличие широкого круга участников приводит к конфликту достижения их целей, которые определяются непосредственно их ролью в инфраструктуре распределенной среды. Необходимость согласования их действий приводит к необходимости решения новых задач: оперативного планирования, эффективного распределения ресурсов и координации решения задач планирования на различных уровнях распределенных вычислительных систем (РВС). Следствием неоптимального планирования процесса обслуживания множества запросов пользователей является уменьшение степени использования информационных ресурсов, а также снижение безопасности и живучести информационной системы [1, 2].
Различные общие вопросы и прикладные аспекты применения РВС исследованы в работах Загороднего А. Г., Згуровского М. З., Мартыненко Е. С., Фостера Я. (Foster I.), Кесельмана К. (Kesselman C.) и других ученых. Вопросам разработки методов и моделей планирования, оптимизации и повышения производительности функционирования РВС, обеспечения качества обслуживания в вычислительных средах с использованием современных технологий распределенных и параллельных вычислений в фундаментальных и прикладных исследованиях посвящены работы Воеводина В. В., Воеводина Вл. В., Гергеля В. П., Горбенко А. В., Дорошенко А. Е., Корнеева В.В., Куссуль Н. Н., Листрового С. В., Мамойленко С. Н., Павлова А. А., Петренко А. И., Погорелого С. Д., Пономаренко В. С., Ролика А. И., Симоненко В. П., Стиренко С. Г., Топоркова В. В., Хорошевского В. Г., Шелестова А. Ю., Шматкова С. И., Буйи Р. (Buyya R.), Ксхафы Ф. (Xhafa F.) и других ученых. Наиболее известными исследованиями в области алгоритмического, математического и программного обеспечения распределения задач по вычислительным узлам гетерогенной вычислительной среды можно считать работы Бершадского А.М., Голубева И.А., Кальпеевой Ж.Б., Селиверстова Е.Ю., Покусина Н.В., Хачкинаева Г.М., Телеснина Б.А., Бычкова И.В., Agrawal D., Zhao H., Sakellariou R., Amar A., Bolze R., Boix E., Amedro B., Bodnartchouk V. и Baduel L. Выбор способа распределения задач (данных) по вычислительным узлам определяет общую эффективность вычислительной среды.
К основным функциональным компонентам РВС относятся системы управления ресурсами, планировщики заданий, ресурсы и информационные службы. Функционирование РВС характеризуется неоднородностью ресурсов, коммуникационных каналов, заданий, ограниченных временем выполнения или бюджетом.
Как показывает анализ режимов функционирования сетевой базы данных (СБД) показал, что разработка и сопровождение информационных систем такого типа производится из расчета среднестатистической нагрузки определяющейся соотношением 80/20 т.е. каждым 80 запросам соответствует 20 транзакций, но такое соотношение не дает реального представления о круглосуточном функционировании информационной системы. В частности, при таком подходе не учитывается почасовая нагрузка в течении суток, когда в периоды реорганизации число транзакций, как правило превосходит число запросов [3-5].
Исследование гистограммы рис. 1 показывает, что автоматизированной информационно-управляющей системе (АИУС) использующей СБД присущи два критических режима функционирования:
1. Область красного цвета – пиковая рабочая нагрузка являющаяся суммой пользовательских запросов и запросов на корректировки (транзакций), и определяемая соотношением:
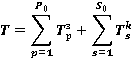
где  - время реализации - время реализации  го запроса пользователя, а го запроса пользователя, а  - время реализации - время реализации  того задания на корректировку. того задания на корректировку.
Она характеризуется возрастанием числа запросов до 96 в минуту и числа транзакций до 18 в минуту. Длительность функционирования информационной системы в режиме пиковой нагрузки около 5 часов с 11.00 часов до 16.00 часов. Соотношение соответственно составляет 96/18.
2. Область зеленого цвета – режим реорганизации базы данных. Она характеризуется возрастанием числа транзакций до 45 в секунду и падением числа запросов до 5 в секунду. Продолжительность функционирования информационной системы в режиме реорганизации составляет около 3 часов соответственно с 00.00 до 03.00 часов. Соотношение составляет 5/45.
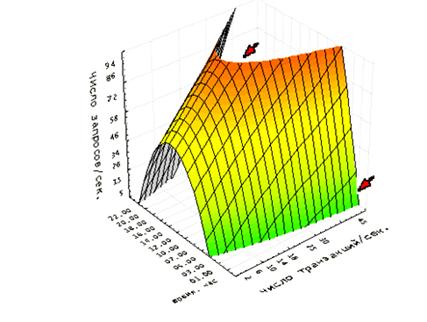
Рисунок 1 - Диаграмма соотношения запросы/транзакции в течении суток
Таким образом соответствие правила 80/20 используемого разработчиками и администраторами для СБД АИУС справедливо для достаточно идеализированной системы и соответствует истинному только на некотором участке времени. Если предположить, что информационная система функционирует в режиме близком к идеальному все оставшееся время, то даже такое предположение, ставит под сомнение правомочность использования данного правила поскольку 8 часов работы информационной системы при критической нагрузке составляет 1/3 суток, при условии, что 5 часов из 8 система функционирует в режиме обслуживания множества запросов пользователей рис. 2.
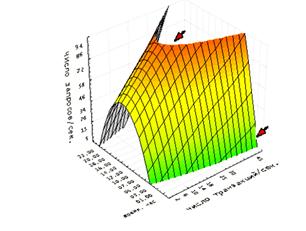
Рисунок 2 - Диаграмма соотношения запросы/транзакции в течении суток с учетом параметра 80/20
Как противопоставление высказанному предположению о идеализированном состоянии информационной системы рассмотрим графики анализа рабочей нагрузки отдельно для транзакций и отдельно для запросов. Как видно из графика рис. 3. рекомендуемое правило не учитывает возрастание пользовательской нагрузки в системе на указанном участке времени. Такое же состояние наблюдается и для реализации транзакций в системе, что и отображено на графике рис 4 соответственно. Исследование поведения рабочей нагрузки возникающей в СБД для более длительных промежутков времени показало, что в целом характер ее поведения не изменяется график рис. 5, и наблюдается только некоторое снижение в конце недели с 56 до 47 запросов в мин., что не является достаточно существенным.
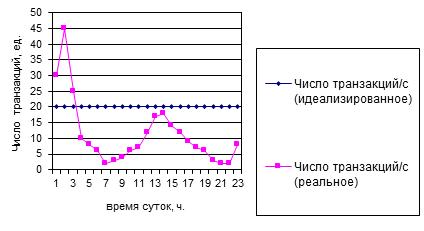
Рисунок 3 График соответствия правила 80/20 расчета динамической нагрузки транзакций реальной нагрузке
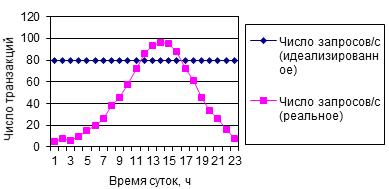
Рисунок 4 График соответствия правила 80/20 расчета динамической нагрузки запросов реальной нагрузке
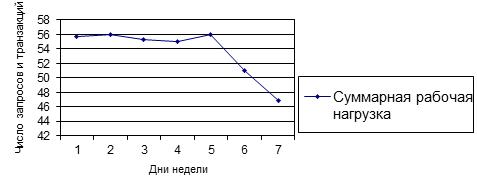
Рисунок 5 График суммарной рабочей нагрузки по дням недели
Также в классических моделях не учитываются такие важные ситуации, как возможность захвата некоторыми запросами одновременно пересекаемых областей данных. И наконец, это уровень требований к качеству обслуживания, предъявляемый различными классами запросов пользователей. Последнее обстоятельство снижает точность получаемых результатов, и соответственно увеличивает число сбоев и конфликтов, возникающих в исследуемых системах.
Оценка и анализ процессов управления реализацией рабочей нагрузкой в сетевых информационных системах позволили выделить в отдельный класс запросы на корректировку на основе их семантики. Такое разделение рабочей нагрузки позволяет рассмотреть запросы и транзакции как две составляющих исключив их влияние друг на друга. В классических же моделях указанное разграничение производится посредством применения различного рода блокировок, не семантических свойств языковых операторов [6].
Основной материал
1. Разработка математической модели выборки запросов в сетевой базе данных
Сетевая база данных состоит из 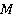 таблиц таблиц 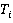 , , 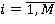 содержащие информацию и системы управления базой данных. К базе данных имеют доступ содержащие информацию и системы управления базой данных. К базе данных имеют доступ 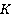 операторов операторов 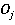 , , 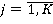 , которые формируют запросы к базе данных. Каждый запрос , которые формируют запросы к базе данных. Каждый запрос 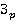 от любого оператора имеет свой приоритет от любого оператора имеет свой приоритет 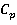 , зависящий от уровня привилегий оператора. Момент времени, в который от оператора поступает запрос – величина случайная. Поэтому на входе системы управления при высокой интенсивности запросов образуются очереди запросов. Схема формирования очереди запросов в сетевой базе данных показана на рис. 6. , зависящий от уровня привилегий оператора. Момент времени, в который от оператора поступает запрос – величина случайная. Поэтому на входе системы управления при высокой интенсивности запросов образуются очереди запросов. Схема формирования очереди запросов в сетевой базе данных показана на рис. 6.
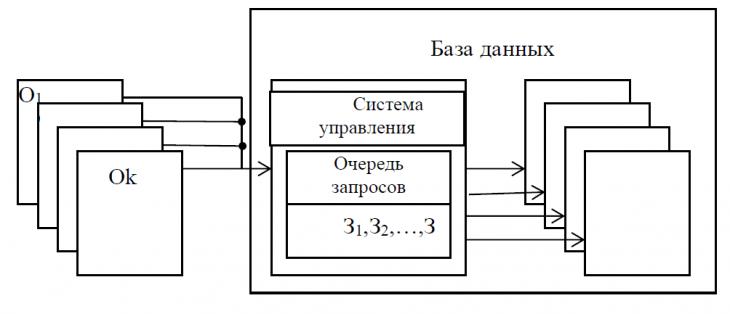
Рисунок 6 Схема управления базой данных
При наличии ограничений на размер хранимой очереди в системе управления может возникнуть ситуация, при которой очередной запрос, поступивший на вход системы управления, не будет принят к обслуживанию, что приведет к его потере или к задержке в обслуживании. Таким образом диссипативные структуры могут перейти из одного стационарного состояния в другое в результате неустойчивости предыдущего неупорядоченного состояния при критическом значении некоторого параметра, отвечающего точке бифуркации. В точке бифуркации невозможно предсказать, в каком направлении будет развиваться система: станет ли состояние хаотическим или система перейдет на новый, более высокий уровень упорядоченности [7,8].
Следует отметить дополнительное требование к управлению сетевой базой данных - система управления должна иметь одновременный доступ к любому количеству таблиц. Определимся, что под разрешением очереди будем понимать процесс поэтапной выборки запросов из очереди запросов, которые необходимо и возможно выполнить на данном этапе. Запросы в очередь поступают в любой момент времени, но состояние очереди определяется только между этапами.
Для разрешения очереди запросов необходимо выбрать наиболее приемлемый способ выборки запросов и наилучший метод реализации выбранного способа.
Для оценки способа выборки запросов будем использовать коэффициент использования ресурсов 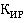 Данный коэффициент показывает, какая часть таблиц, из общего количества таблиц к которым обращаются стоящие в очереди запросы, будет использована. Если КИР = 0, то ни одна таблица не будет использована, а если Данный коэффициент показывает, какая часть таблиц, из общего количества таблиц к которым обращаются стоящие в очереди запросы, будет использована. Если КИР = 0, то ни одна таблица не будет использована, а если 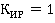 , то используются все таблицы, к которым существуют запросы на данный момент. Но не всегда возможно выбрать такие запросы, чтобы все таблицы были задействованы. Поэтому перед нами стоит задача выбора такого способа разрешения очереди запросов, при котором стремилось к 1. В общем виде КИР определяется следующим образом: , то используются все таблицы, к которым существуют запросы на данный момент. Но не всегда возможно выбрать такие запросы, чтобы все таблицы были задействованы. Поэтому перед нами стоит задача выбора такого способа разрешения очереди запросов, при котором стремилось к 1. В общем виде КИР определяется следующим образом:
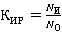 , (1) , (1)
где 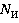 – количество таблиц, которые будут задействованы при реализации определенной выборки; – количество таблиц, которые будут задействованы при реализации определенной выборки; 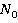 – количество таблиц, к которым существуют запросы из очереди. – количество таблиц, к которым существуют запросы из очереди.
Но в данном виде не учитывает приоритеты запросов, поэтому необходимо изменить коэффициент (1), для учета приоритета запросов. Но если учитывать приоритеты запросов, то представление коэффициента зависит от выбранного способа выборки. От выборки будет зависеть только числитель, а знаменатель будет одинаковым. Определим его: пусть 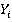 – максимальная величина приоритета запроса из запросов очереди, обращающихся к таблице , тогда знаменатель примет вид: – максимальная величина приоритета запроса из запросов очереди, обращающихся к таблице , тогда знаменатель примет вид:
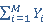 . (2) . (2)
Наиболее перспективными вариантами способа обслуживания запросов являются:
- способ групповой выборки;
- способ групповой выборки с индивидуальным сегментированием.
Способ групповой выборки – это такой способ, при реализации которого из очереди запросов обслуживается несколько запросов одновременно. Выбираются запросы, которые требуют информацию из разных таблиц, и чтобы сумма их приоритетов была максимальной. В случае наличия равнозначных запросов выбирают более «старые».
Пусть 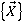 - множество всех вариантов выборки запросов из очереди, - множество всех вариантов выборки запросов из очереди, 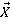 - один из вариантов выборки запросов. Причем - один из вариантов выборки запросов. Причем
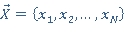 (3) (3)
где 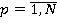 , N ‑ количество запросов в очереди, , N ‑ количество запросов в очереди, 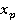 – булева переменная равная 1 если запрос выбран в этом варианте и 0 если нет. – приоритет запроса . Тогда числитель из (1) примет вид: – булева переменная равная 1 если запрос выбран в этом варианте и 0 если нет. – приоритет запроса . Тогда числитель из (1) примет вид:
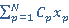 (4) (4)
Получаем КИР следующего вида с учетом (4) и (2):
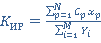 (5) (5)
Для того чтобы 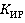 приняло единичное значение необходимо чтобы числитель (4) из (5) был бы равен знаменателю (2) из (5). Но это в лучшем случае, а в общем случае числитель должен стремиться к знаменателю. Так как знаменатель для конкретного момента времени это константа, то необходимо сделать такую выборку запросов из очереди, чтобы числитель принял максимальное значение, причем это значение никогда не превысит знаменатель. приняло единичное значение необходимо чтобы числитель (4) из (5) был бы равен знаменателю (2) из (5). Но это в лучшем случае, а в общем случае числитель должен стремиться к знаменателю. Так как знаменатель для конкретного момента времени это константа, то необходимо сделать такую выборку запросов из очереди, чтобы числитель принял максимальное значение, причем это значение никогда не превысит знаменатель.
Это означает, что необходимо выбрать из очереди как можно большее количество запросов, которые обращаются к разным таблицам, и сумма приоритетов выбранных запросов была бы максимальна. Причем стремление к максимуму суммы приоритетов выбранных запросов является главным критерием при выборе запросов из очереди.
Обозначим числитель (5) переменной F, которая стремится к максимальному значению. Получаем функционал:
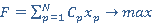 (6) (6)
Пусть 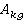 – булева переменная равная 1 если – булева переменная равная 1 если 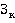 использует таблицу использует таблицу 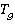 и 0 если нет. и 0 если нет. 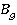 – количество копий таблицы . Тогда исходя из условия, что в любой момент времени любая таблица может быть использована для одного запроса получаем M ограничений вида: – количество копий таблицы . Тогда исходя из условия, что в любой момент времени любая таблица может быть использована для одного запроса получаем M ограничений вида:
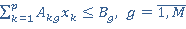 (7) (7)
Следовательно, нам необходимо найти такую выборку из множества для которой функционал (6) примет максимальное значение, при выполнении всех ограничений (7). Мы получили задачу линейного программирования с булевыми переменным.
Способ групповой выборки с индивидуальной сегментацией ‑ это такой способ, при реализации которого запросы, находящиеся в очереди, разбиваются на подзапросы. Из очереди полученных подзапросов выбираются подзапросы, требующие информацию из различных таблиц, и чтобы сумма их приоритетов была максимальной. В случае наличия равнозначных подзапросов выбирают более «старые».
Подзапрос – это часть запроса, которая запрашивает информацию из одной конкретной таблицы. Если запроса требует информацию из 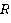 таблиц, то он разбивается на подзапросов. таблиц, то он разбивается на подзапросов.
В этом варианте нам надо выбрать из очереди как можно большее количество подзапросы, которые обращаются к разным таблицам, и сумма приоритетов выбранных подзапросов была бы максимальна. Причем стремление к максимуму суммы приоритетов выбранных подзапросов является главным критерием при выборе подзапросов из очереди.
Пусть 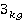 –подзапрос запроса –подзапрос запроса 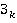 обращающийся к таблице . обращающийся к таблице . 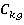 – приоритет запроса . - множество всех вариантов выбора подзапросов из очереди, - один из вариантов выбора подзапросов. Причем – приоритет запроса . - множество всех вариантов выбора подзапросов из очереди, - один из вариантов выбора подзапросов. Причем 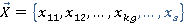 , где , где 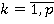 , , 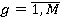 , , 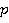 ‑ количество запросов в очереди, – количество таблиц, ‑ количество запросов в очереди, – количество таблиц, 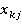 ‑ булева переменная равная 1 если соответствующий подзапрос выбран в этом варианте и 0 если нет, тогда коэффициент (5) примет вид: ‑ булева переменная равная 1 если соответствующий подзапрос выбран в этом варианте и 0 если нет, тогда коэффициент (5) примет вид:
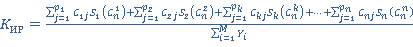 (8) (8)
где 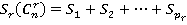 - сумма всех возможных сочетаний произведений переменных содержащих в каждом произведении - сумма всех возможных сочетаний произведений переменных содержащих в каждом произведении 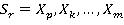 r различных переменных; r различных переменных; 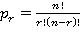 ; ;
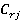 - коэффициенты стоящие в произведениях - коэффициенты стоящие в произведениях 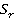 содержащих содержащих 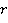 переменных. переменных.
И, соответственно, исходя из (6) получаем функционал:
 (9) (9)
Таким образом, мы получаем задачу нелинейного программирования с булевыми переменными, с ограничениями вида (7).
2. Оценка погрешности алгоритмов решения задач дискретной оптимизации использующих ранговый подход
Дадим формальное описание понятия “оптимизационная задача”. В общем случае комбинаторная оптимизационная задача 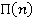 размерности размерности 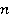 - есть задача либо минимизации либо максимазации некоторой целевой функции и состоит из следующих трех частей. - есть задача либо минимизации либо максимазации некоторой целевой функции и состоит из следующих трех частей.
1.Множества Zп(n) индивидуальных задач размерности n.
2. Множества допустимых решений Wп(I(n)) для каждой индивидуальной задачи I(n) Î Zп(n).
3.Функции fп, сопоставляющей каждой индивидуальной задаче I(n) Î Zп(n) и каждому допустимому решению sп(n) Î Wп(I(n)) число fп(I(n), sп(n)), называемое величиной решения.
Размерность задачи I(n) и соответственно функция размера входа алгоритма А, решающего задачу I, представляется в виде последовательности (или цепочки) символов, необходимых для ее разумного кодирования, при этом размер n входа определяется как число символов в ней. Если П(n) задача максимизации, то оптимальным решением индивидуальной задачи I(n) Î Zп(n) является такое допустимое решение sп*(n) Î Wп(I(n)), что для всех sп(n) Î Wп(П(n)) выполняется неравенство fп(I(n), sп*(n)) ³ fп(I(n), sп(n)). Для обозначения величины fп(I(n), sп*(n)) оптимального решения задачи I(n) будем использовать ОРТ(I(n)). Анализ погрешности проведем на примере задачи (0,1)-рюкзак, поэтому индекс в дальнейшем может опускаться. Через А(I(n)) обозначим величину fп(I(n), sп(n)) того возможного sп(n), которое алгоритм А строит по I(n). Если 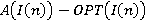 для всех I(n) Î Zп(n), то алгоритм дает точное решение задачи П. для всех I(n) Î Zп(n), то алгоритм дает точное решение задачи П.
Рассмотрим одну из наиболее естественных оценок отклонения от оптимума, а именно для всех индивидуальных задач I(n) имеет место оценка
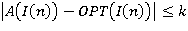 (10) (10)
где k – константа.
Если приближенный алгоритм А решает задачу (0,1)-рюкзак на основе выделения коридора по величине функционала при использовании рангового подхода, то
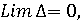 (11) (11)
где
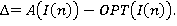
Условно при экспериментальном анализе погрешностей вычислений алгоритмами, можно выделить три зоны. Первая и третья зоны соответствуют тем решениям, при которых алгоритмы дают точные решения. Для второй зоны, лежащей на интервале [от rср = n/3 до rср = 2n/3] наблюдается наибольший рост допустимых решений в самом коридоре. В соответствии с треугольником Паскаля, предельное значение числа различных допустимых решений, попадающих во вторую зону, не может превысить f(r = n/2, n) = Cnr=n/2 , с учетом соотношения Стирлинга
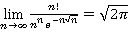 (12) (12)
имеем
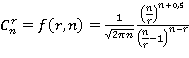 (13) (13)
При 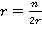 соотношение (13) примет вид соотношение (13) примет вид
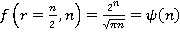 (14) (14)
Введем функцию плотности числа единиц функционала, приходящихся на одно решение, в выделенном на ярусе r коридоре Dfr
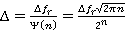 (15) (15)
При переходе от яруса r к ярусу r = r + 1 ширина коридора Dfr не возрастает Dfr+1 £ Dfr. При 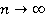 различные решения различные решения 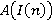 в коридоре будут отличаться друг от друга на величину, не превышающую L.Следовательно, D £ L. Нетрудно видеть, что в коридоре будут отличаться друг от друга на величину, не превышающую L.Следовательно, D £ L. Нетрудно видеть, что
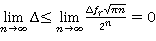 , (16) , (16)
При фиксированном значении 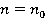 , L = L0 соответственно выполняется неравенство D £ L0 = const. , L = L0 соответственно выполняется неравенство D £ L0 = const.
3. Разработка метода и алгоритмов распределения рабочей нагрузки в сетевых базах данных
Метод основан на комбинированном использовании способа отсечения неперспективных вариантов решения, используя идеи метода «рангового подхода», и способа построения возможных вариантов решений, используя идеи метода «ветвей и границ» [2, 3,9]. Суть разработанного метода заключается в том, что при формировании множества возможных решений на основе «рангового подхода» отсев неперспективных вариантов, внутри множеств, происходит на основе метода «ветвей и границ». При этом для определения верхней и нижней оценки, при реализации метода «ветвей и границ», используются разработанные для алгоритмов метода «рангового подхода» оптимистический (PО) и гарантированный прогнозы (PG) соответственно. Оптимистический прогноз – это такая величина решения задачи основанного на векторе (3), для которого определяется прогноз, которая обязательно не будет превышена. Гарантированный прогноз – это такая величина решения задачи основанного на векторе (3), для которого определяется прогноз, которая обязательно будет получена.
Для корректировки времени решения предлагается использовать величину которую будем называть степенью огрубления (εогр). Данная величина измеряется в процентах и показывает степень приближения верхней оценки к нижней оценке, путем принудительного уменьшения верхней. При изменении εогр время решения задачи обратно пропорционально погрешности решения.
Для формализации метода разрабатываются процедуры П1 и П2. Процедура П1 применяется для построения цепочки векторов и, соответственно, для выбора из нее оптимального решения, а процедура П2 применяется для построения прогнозов и отсечения неперспективных векторов. Необходимо отметить, что для каждого вектора из цепочки полученной с помощью процедуры П1 выполняется процедура П2.
Разработка алгоритма включает в себя реализацию процедур П1 и П2. Для рационального использования памяти построение цепочки векторов производится в «глубину», в этом случае необходимо будет хранить не более N векторов в любой момент времени. Для дальнейшего уменьшения требуемого объема памяти, так как алгоритм является итерационным, реализован рекурсивный вызов функции П1. В теле которой выполняется функция П2. Входными параметрами для обеих процедур является текущий вектор (текущее решение) вида: 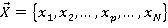 . Причем вторым входным параметром функции П1 является число р. Данное число р сопровождает текущий вектор и говорит о том, что все . Причем вторым входным параметром функции П1 является число р. Данное число р сопровождает текущий вектор и говорит о том, что все 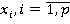 определены и принимают значения 0 либо 1, а определены и принимают значения 0 либо 1, а 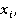 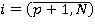 неопределенны. К тому же в очередном вызове процедуры П1 определяется значение именно х(р+1). Процедура П1не зависит от степени нелинейности функционала. Решение задачи начинается с, так называемого нулевого вектора. Нулевой вектор, это вектор (3) у которого все хi неопределенны. Обозначим неопределенны. К тому же в очередном вызове процедуры П1 определяется значение именно х(р+1). Процедура П1не зависит от степени нелинейности функционала. Решение задачи начинается с, так называемого нулевого вектора. Нулевой вектор, это вектор (3) у которого все хi неопределенны. Обозначим 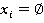 если хi не определён, но при вычислении значений функционала и ограничений считать если хi не определён, но при вычислении значений функционала и ограничений считать 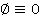 . Поэтому нулевой вектор примет вид: . Поэтому нулевой вектор примет вид:
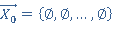 (10) (10)
Причем р нулевого вектора равен 1.
Обозначим: текущий вектор - 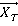 ; значение функционала при подстановке - ; значение функционала при подстановке -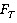 ; текущий максимум - ; текущий максимум - 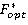 ; текущий оптимальный вектор - ; текущий оптимальный вектор - 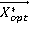 ; некоторый вектор -. ; некоторый вектор -.
Алгоритм имеет вид:
Шаг1. 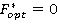
Шаг2. Вызвать процедуру П1 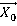 (,1) (,1)
Шаг3. Выдать и как решение задачи.
Шаг1 необходим для инициализации переменной.
Шаг2 процедура П1 запускается однократно с входными переменными равными нулевому вектору и его числу р. В дальнейшем данная процедура рекурсивно запускает сама себя.
Шаг3 после перебора всех векторов на выходе процедуры будем иметь решение задачи.
Процедура П1 имеет вид:
Заголовок П1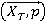
Шаг1. Определяем выполнимость всех ограничения при .
Шаг2. Если хотя бы одно ограничение не выполнено, тогда выход из процедуры.
Шаг3. Если 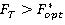 , тогда , тогда 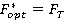 , , 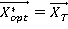 . .
Шаг4. Если 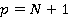 , тогда выход из процедуры. , тогда выход из процедуры.
Шаг5. Присвоить 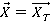 , у изменить хр на 0. , у изменить хр на 0.
Шаг6. Вызвать процедуру П1 (,р+1).
Шаг7. Присвоить , у изменить хр на 1.
Шаг8. Вызвать процедуру П1 (,р+1).
Шаг9. Выход из процедуры.
Шаг1 необходим для проверки является ли одним из решений задачи.
Шаг3 необходим для обновления текущего оптимального решения.
Шаг4 необходим для проверки глубины выборки.
Шаги 5,6 и 7,8 необходимы для формирования следующего текущего вектора и рекурсивного вызова функции.
Если ограничиться реализацией алгоритма и процедуры П1, то получим точный алгоритм. Но так как при большой размерности решаемой задачи время, за которое алгоритм выдаст точное решение, превысит допустимое время. Поэтому есть необходимость в разработке приближенного алгоритма. Для этого была разработана процедура П2.
Для описания процедуры П2 введем следующие переменные:
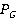 - гарантированный прогноз вектора - гарантированный прогноз вектора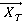 ; ;
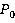 - оптимистический прогноз вектора ; - оптимистический прогноз вектора ;
Процедура П2 интегрируется в процедуру П1 вместо Шага3.
В этом случае процедура П1 с интегрированной процедурой П2 примет вид:
Заголовок П1
Шаг1. Определяем выполнимость всех ограничения при .
Шаг2. Если хотя бы одно ограничение невыполнено, тогда выход из процедуры.
Шаг3. Если 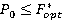 , тогда выход из процедуры. , тогда выход из процедуры.
Шаг4. Если 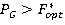 , тогда , тогда 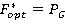 ,. ,.
Шаг5. Присвоить = εогр εогр
Шаг6. Если , тогда выход из процедуры.
Шаг7. Если , тогда выход из процедуры.
Шаг8. Присвоить, у изменить хр на 0.
Шаг9. Вызвать процедуру П1 (,р+1).
Шаг10. Присвоить , у изменить хр на 1.
Шаг11. Вызвать процедуру П1 (,р+1).
Шаг12. Выход из процедуры.
Шаг5 необходим для коррекции оптимистического прогноза с учетом εогр. Необходимо отметить, что если εогр=1, тогда мы получаем точное решение, а при уменьшении εогр к 0 будут получены приближенные решения. Данный алгоритм позволяет, задавая значение εогр, получать решения с заданной погрешностью или за заданное время.
4. Экспериментальное исследование разработанных алгоритмов
Таким образом необходимо выделить 3 алгоритма решения задач булевого программирования, которые необходимо сравнить: 1 - полный перебор, на основе рангового подхода; 2 - комбинированный метод, из метода «ветвей и границ» и на основе рангового подхода; 3 – метод схожий на 2, но вместо переменных использующий их дизъюнкции – слагаемые в базовом уравнении.
Программное обеспечение (далее ПО является не коммерческим, свободно распространяемым ПО. Главные функции данного ПО – исследование предложенных алгоритмов для решения задач булевого программирования. В программе были реализованы три алгоритма, на основе единого шаблона построения программы. Шаблон не является оптимальным, но гарантирует, что все три алгоритма имеют одну скорость работы основного алгоритма прохода по рангам. За счет этого зависимость показателей времени вычисления задачи, а также погрешности, зависит от самого алгоритма, а не от реализации, например прохода по рангам, в данной задаче.
Таким образом полученные показатели позволяют сравнить между собой эффективность алгоритмов, и в то же время не дают точных результатов, например, для быстродействия отдельного алгоритма программы для конкретной системы.
ПО предусматривает следующие функции:
- генерация случайной системы уравнений по заданным условиям;
- решение системы уравнений тремя методами;
- возможность тестирования программы в автоматическом режиме;
- построение графиков зависимостей по файлу отчета, сформированному программой;
- возможность настройки параметров тестирования в автоматическом режиме.
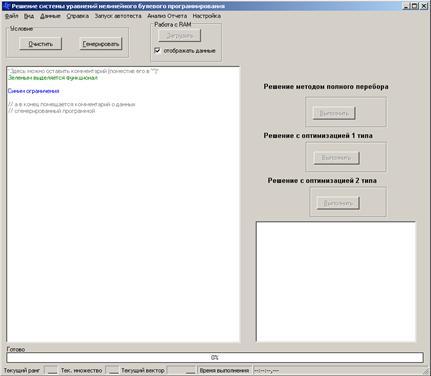
Рисунок 7 – Главное окно ПО РЗБП
Перечисленные выше функции позволяют в полной мере протестировать алгоритмы решения задач, а также с помощью системы анализа и построения графиков, показать наглядно эффективность каждого алгоритма (рис. 8).
Рисунок 8 Результаты экспериментального исследования алгоритмов
Результаты экспериментального исследования показывают, что увеличение числа ограничений в задачах нелинейного булевого программирования приводит к снижению погрешности их решения, при этом сама степень нелинейности несущественно влияет на величину погрешности. Из экспериментального исследования разработанных алгоритмов решения рассмотренных в работе задач следует, что в случае формализации задач булевого программирования в графовой постановке в большинстве случаев удается уменьшить временную сложность алгоритмов их решения.
Заключение
Необходимо ответить, что при использовании способа групповой выборки с индивидуальной сегментацией коэффициент КИР больше, чем при использовании способа групповой выборки без индивидуальной сегментации. Но время, необходимое для решения задачи определения оптимальной выборки при выборе различных способов выборки, различно. И помимо выбора способа выборки с максимальным значением коэффициента KИР, необходимо также учитывать того, что время, необходимое для определения оптимальной выборки, не должно превысить допустимое время ТД. А так как для одной и той же очереди запросов время необходимое для определения оптимальной выборки у способа групповой выборки без индивидуальной сегментации меньше, чем у способа групповой выборки с индивидуальной сегментации, то возможны случаи, когда необходимо для нахождения оптимальной выборки выбирать способ групповой выборки без индивидуальной сегментации.
В различных системах на время обслуживания запросов из очереди накладывается временное ограничение, заключающееся в том, что оно не должно превышать некоторое значение Тд. Поэтому решение задачи обслуживания запросов обеспечивающее максимальное значение коэффициента КИР должно осуществляться с требуемой оперативностью, которую можно оценить вероятностью решения данной задачи за время, не превышающее Тд.
References
1. Bui D. B., Skobelev V. G. Modeli, metody i algoritmy optimizatsii zaprosov v bazakh dannykh // Komp'yuternye sistemy i informatsionnye tekhnologii 2014, № 2 (66) 46 C. 43-58
2. Listrovoy, S.V., Tretjak, V.F. and Listrovaya, A.S. (1999), “Parallel algorithms of calculation process optimization for the Boolean programming problems”,Ibid., Vol. 16, pp. 569-579.
3. Tret'yak V.F., Pashneva A. A. Optimizatsiya struktury khranilishcha dannykh v uzlakh seti infokommunikatsionnoi seti oblachnogo khranilishcha // Sistemy navigatsii i svyazi Poltavskogo natsional'nogo universiteta imeni Yuriya Kondratyuka. №4 (44).-2017-S. 122-128
4. Dubinin V.N., Zinkin S.A. Setevye modeli raspredelennykh sistem obrabotki, khraneniya i peredachi dannykh Monografiya. – Penza: Privolzhskii Dom znanii, 2013. – 452 s.
5. Fedorin A.N. Mnogokriterial'nye zadachi rantsevogo tipa: razrabotka i sravnitel'nyi analiz algoritmov: Dis. ... kand. tekhn. nauk: 05.13.18 / Nizhegorodskii gosudarstvennyi universitet im. N.I. Lobachevskogo. – Nizhnii Novgorod, 2010.-132 s.
6. Informatsionnoe obespechenie sistem organizatsionnogo upravleniya (teoreticheskie osnovy) [Tekst] : v 3-kh ch. / pod red. E. A. Mikrina, V. V. Kul'by.-M. : Fizmatlit, 2011-. Ch. 2 : Metody analiza i proektirovaniya informatsionnykh sistem / E. A. Mikrin [i dr.].-2011.-493 s.
7. Andrianova E.G., Mel'nikov S.V., Raev V.K. Dissipatsiya i entropiya v fizicheskikh i informatsionnykh sistemakh // Fundamental'nye issledovaniya. 2015. № 8–2. C. 233–238.
8. Kveglis L. I.Dissipativnye struktury v tonkikh nanokristallicheskikh plenkakh : monografiya / L. I. Kveglis, V. B. Kashkin ; otv. red. V. F. Shabanov.-Krasnoyarsk: Sib. feder. un-t, 2011.-204 s.
9. Patent na poleznuyu model' № 69487, Ukraina, MPK G06 F15/00. Ustroistvo dlya resheniya zadach na grafakh / V.F. Tret'yak, D.Yu. Golubnichii i dr. – № u201113667; zayav. 21.11.2011; opubl. 25.04.2012; Byul. № 8. – 6 s
| 






