|
Cybernetics and programming
Reference:
Tregubov, A.S. (2017). Development of adaptive context-sensitive interfaces using ontological models. Cybernetics and programming, 6, 50–56. https://doi.org/10.25136/2644-5522.2017.6.24747
Development of adaptive context-sensitive interfaces using ontological models
Tregubov Artem Sergeevich
Master degree student of the Faculty of Information Technologies, Department of General Computer Studies at Novosibirsk State University
630090, Russia, Novosibirskaya oblast', g. Novosibirsk, ul. Pirogova, 2

|
artem.tregubov@mail.ru
|
|
 |
Other publications by this author
|
|
|
DOI: 10.25136/2644-5522.2017.6.24747
Received:
16-11-2017
Published:
11-01-2018
Abstract:
The user interface is an integral part of the software. To make its use easier for the user when working with the current task, it must be constantly optimized and simplified.This article is devoted to the development of adaptive user interfaces. The purpose of which is to facilitate the interaction of the operator with the system. Knowledge of the user, the context of the situation and the capabilities of the device allow such systems to adapt to the needs of each individual in order to make the interaction more simple, convenient, individual for each user. Data on the different characteristics of the user are vital to achieving the main objectives of such systems. To find a suitable solution, methods of system analysis, synthesis and abstraction were applied. As a result of the introduction of an additional meta-level, a new algorithm for constructing adaptive interfaces was synthesized during the operation of the data. In order to gather knowledge, several formal models were developed, which are necessary for organizing and comprehending the collected information. This article analyzes several solutions presented in the literature about user modeling, context and knowledge taking into account different approaches. In the article, their advantages and disadvantages are determined, and at last a proprietary ontological model is proposed that circumvents the described limitations.
Keywords:
stereotypical adaptation, adaptive interface, context definition, ontologies, user properties, building a user model, meta-level data, user laterization, adaptation of hierarchical interfaces, adaptive interfaces
Большой разброс интересов пользователей усложняет разработку интерфейсов и заставляет разработчиков отказаться от статичных страниц в пользу адаптируемых или же настраиваемых интерфейсов.
Число алгоритмов адаптации велико, но каждый из них так или иначе использует математическую модель пользователя. Для построения такой модели применяются статистические методы, использующие данные полученные в процессе взаимодействия пользователя с системой.
Системы моделирования пользователя появились в 1980-х годах, когда исследователи, столкнувшись с требованиями, предъявляемыми к все более сложным приложениям, были вынуждены начать разработку альтернативных подходов к созданию и проектированию интерфейсов.
Существует два подхода к определению понятия пользовательской модели. Первый определяет пользовательское моделирование, как процесс, через который система может собирать информацию и знания о пользователях и их характеристиках. Модель пользователя рассматривается в качестве источника информации, содержащей несколько предположений о соответствующих данных поведения и адаптациях. Второй подход был предложен Вольфгангом Поулом.[1], определяет пользовательское моделирование, отмечая что пользователей можно определить через задачи, которые они способны выполнять и представление о пользователях, которое имеют UX-дизайнеры.
Обзор литературы
Модель пользователя можно представить в разных формах, наиболее простым из которых является представление в виде вектора интересов. Возможные функции нумеруются от 1 до N, и для каждой из них рассчитывается вес на основе статистических данных. Эта модель является достаточно простой в построении, но требует большое количество данных.
Подобные методы применяются в работах Шумкиной[2] и Морозова[3]. Они показывают хорошие результаты. И в данной работе принято решение усовершенствовать данный подход за счет введения дополнительного метауровня.
Текущие тенденции в развитии адаптивных интерфейсов показывают необходимость в дополнительной абстракции. Это просматривается в следующей литературе.
В 2003 году были описаны две работы, рассматривающие системы моделирования пользователей на основе онтологий. Первая посвящена персонализированной навигации для online-ресурсов. Гоуч, Чаффи и Претшер[4] предоставили пользовательскую онтологию для динамического моделирования пользователей во время серфинга (просмотра сайтов). Онтология формируется несколькими весовыми понятиями, показывающими интерес пользователя к соответствующей функции. Другая работа, так же сфокусированная на системе управления знаниями, написана Разморитой, Ангхёрн и Мидч[5], которые представили OntobUM, обобщенную архитектуру для основанных на онтологиях систем пользовательского моделирования. Возможны два разных способа к созданию модели: первый - явно, используя редактор пользовательского профиля, и второй - неявно, когда информация собирается при помощи фоновых сервисов.
В 2007 году Големати, Катифори, Васелакис, Лепурос и Халатсис[6] представили онтологию, которая дополняет решения, описанные ранее с целью сокращения внутренних проблем моделирования пользователя: беспорядочный процесс моделирования, неизвестное количество данных необходимое для моделирования пользователей, а также возможные ошибки при исключении некоторых характеристик пользователя. С этой целью авторы представляют расширяемую, всеобъемлющую и общую онтологию, разработанную по принципу от общего к частному.
Шахзард в 2011 году [7] разделил пользовательский интерфейс на слои по уровням абстракции:
Стратегия → Цель → Структура → Скелет → Представление
В 2012 году Мак Эвой, Чен, и Донелли[8] предложили систему на основе онтологий для управления контекстами в интеллектуальных средах. Один из наиболее значимых вкладов - это работа с информацией высокого уровня, управляемой с помощью метаданных.
Описание модели
Анализ литературы позволил выделить ряд общих тенденций в развитии адаптивных интерфейсов.
Во-первых, невозможно обойтись без четкого описания модели пользователя, а также без механизма сбора и обработки данных для ее заполнения.
Во-вторых, существует тенденция к транслированию данных в знания. Часто это достигается за счет введения очередного «мета уровня», а также ряда правил, по которым данные (в числовом виде) превращаются в знания.
Последняя тенденция указывает на то, что на сегодня невозможно обойтись простой кластеризацией по вектору интересов пользователей. Данные алгоритмы сильно уступают в качестве получаемых результатов современным разработкам.
Опыт введения контекста совместно с применением метода двойной кластеризации позволил значительно улучшить эффективность алгоритма построения адаптивных меню для USSD[9].
По этим причинам было принято решение о расширении последней работы за счет введения дополнительного уровня абстракции.
Было решено использовать онтологии для хранения знаний. Это обусловлено активным развитием данной области, а также подходящей структурой, которая позволяет хранить, получать и анализировать знания.
Одним из простейших вариантов определения онтологии пользовательского интерфейса является описание при помощи списка функций системы.
Будем считать, что прецедент - это пара <Функция, Контекст>, где контекст - это некоторая структура, позволяющая описать состояние окружения пользователя в данный момент времени. Данный термин позволяет ввести дополнительный мета уровень, позволяющий оперировать не функциями системы, а вариантами их использования в зависимости от контекста.
Например, один и тот же человек может использовать ноутбук для ведения официальной переписки на работе, а в вечернее время вести личную переписку. Несмотря на то, что функция здесь используется одна и та же (набор и отправка текстовых сообщений), варианты использования совершенно разные. Это связано со сменой контекста.
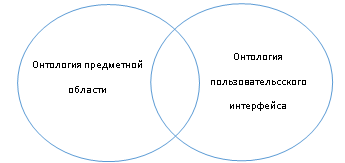
Будем считать, что онтология пользовательского интерфейса — это набор всех возможных прецедентов. Определим онтологию пользовательских задач как пересечение онтологии предметной области и онтологии пользовательского интерфейса программной системы.
Будем считать, что пользовательский интерфейс имеет несколько уровней абстракции [7]:
Стратегия → Цель → Структура → Скелет → Представление
Тогда работа алгоритма оптимизации меню рассчитана на изменение структуры и скелета приложения.
Правила, по которым данные интерпретируются в знания, будем называть правилами вывода.
Много внимания в литературе уделяется транслированию данных в знания. Так, например, данные о яркости монитора, времени суток, истории серфинга в интернете и т.д., позволяют получить знания о пользователе, не выдаваемые им прямо.
Самый простой вариант заключается в эмпирически составленном наборе правил для интерпретации числовых значений. Например, время суток может быть интерпретировано как «рабочее» или «нерабочее» время, плохой сигнал сотовой связи - говорить о нахождении за городом, а ключевые слова при поиске в интернете - сообщать о текущих потребностях пользователя.
В работе [9] говорится об алгоритме, основанном на двухфазной кластеризации. Этот алгоритм показал хорошие результаты. И поэтому за основу было решено взять именно его. Модифицированный алгоритм представлен ниже:
Шаги алгоритма:
1. Получить все возможные контексты
2. Применить к ним правила выводы
3. Кластеризовать все контексты алгоритмом К-средних
4. Получить все возможные прецеденты. Получается, как декартово произведение контекстов на функции системы. В качестве контекстов используются только центры масс из алгоритма К-средних, первого пункта.
5. Для каждого прецедента рассчитывается его вес.
6. Выполнить кластеризацию пользователей, без учета контекстов.
7. Оптимизировать меню, для каждой конкретной группы пользователей используя вместо функций прецеденты.
Алгоритм, предложенный в работе [9], позволяет оптимизировать дерево функций в рамках единственного контекста. Использование прецедентов позволяет обойти это ограничение и создавать оптимальное меню сразу для нескольких категорий.

Таким образом, результат работы алгоритма будет универсальным и может быть использован в ситуациях, когда точная классификация невозможна.
Тестирование:
Для тестирования представленного алгоритма, а также последующего его улучшения и сравнения различных модификаций, было решено создать чат-бота – программу, имитирующую общение с реальными людьми в социальных сетях.
Интерфейс данного бота целенаправленно был сделан таким образом, чтобы быть максимально приближенным к интерфейсу командной строки. Такой интерфейс часто применяется в консольных программах и USSD-сервисах. Меню, описанное в виде графа (или чаще обычного дерева), может быть легко представлено при помощи подобного интерфейса в понятном для пользователя виде. Таким образом, данный алгоритм может быть применен в различных сферах: от меню для выбора услуг посредством USSD, предоставляемых всеми мобильными операторами, до интерфейсов чат-ботов, набирающих все большую популярность за счет своей простоты и отсутствием необходимости в установке дополнительных приложений.
Данная программа была реализована с использованием следующих технологий: C#, NodeJS, RabbitMQ, PostgreSQL. Основная логика обработки данных была реализована на языке программирования C#. Приложение-сервер получает данные из шины синхронизации RabbitMQ, в которую они попадают посредством небольшого сервиса, реализованного на NodeJS. Такой подход позволяет унифицировать получение и обработку данных за счет единой точки входа. Это сделано для последующего расширения поддерживаемых социальных сетей.
На данный момент реализована синхронизация только с одной социальной сетью «ВКонтакте». Но планируется создание бота для таких социальных сетей, как WhatsApp и Telegram. Это позволит охватить большую аудиторию и расширить выборку. Так же для расширения выборки планируется создание чат-ботов различных тематик.
Суть созданного чат-бота – ответы на часто задаваемые вопросы по криптовалютам. За счет столь популярной темы получилось быстро найти достаточную аудиторию для проведения тестирования. На данный момент выборка составила чуть более 1000 человек, что позволяет судить о полученных результатах. На данный момент алгоритм показал эффективность в 16%, к сожалению, алгоритм, описанный в статье [9], показал эффективность в 23%. Но при этом было создано 100 вариаций меню, что для данной выборки неэффективно. Данные алгоритмы могут быть использованы совместно. Например, предложенный в данной статье метод, может быть применен при невозможности определения контекста.
Заключение
Сформулированные принципы позволят перевести разработку в разрез онтологий, а также оперировать понятиями и функциями на более высоком уровне абстракции. Так, например, одна и та же функция может быть представлена в различных прецедентах, то есть пользователь, пользуясь одной и той же функцией, может иметь различные цели в зависимости от контекста. Предложен алгоритм, который позволяет оптимизировать меню, используя механизм прецедентов, при этом не создающий огромное количество вариантов пользовательского интерфейса и сохраняющий эффективность контекстного подхода.
Для тестирования данного алгоритма реализована программа: чат-бот для социальной сети «ВКонтакте». Предложенный алгоритм показал эффективность в 16%, что является неплохим результатом, но и не самым лучшим. Также данный алгоритм является достаточно эффективным при небольших выборках за счет создания малого количества групп пользователей, это снижает количество потребляемых сервером ресурсов.
Данный алгоритм может быть использован совместно с алгоритмом, представленном в работе [9], в ситуациях, когда определение контекста невозможно.
В дальнейшем планируется усовершенствовать алгоритм за счет введения дополнительного мета уровня для пользователей, использования алгоритмов нечеткой кластеризации, формулирования правил для трансляции цифровых чисел в знания, что позволит выполнять кластеризацию по рассчитанным параметрам, взамен неинформативным свойствам, получаемым от программной системы.
References
1. Kobsa, A., & Pohl, W. (1994). The user modeling shell system BGP-MS. User Modeling and User-Adapted Interaction, 4, p 59–106.
2. Shumkina, V. V. ALGORITM AVTOMATIChESKOI ADAPTATsII DREVOVIDNYKh POL''ZOVATEL''SKIKh INTERFEISOV.// Al'manakh sovremennoi nauki i obrazovaniya 2013. № 6 (73). C. 194-196
3. Morozov I. S. Algoritm avtomaticheskoi adaptatsii interfeisa mobil'nykh USSD-servisov // Al'manakh sovremennoi nauki i obrazovaniya. 2015. №8 (98). C. 82-85
4. Gauch, S., Chaffee, J., & Pretschner, A. (2003). Ontology-based personalized search and browsing. Web Intelligence and Agent Systems, 1, p. 219–234.
5. Razmerita, L., Angehrn, A., & Maedche, A. (2003). Ontology-based user modeling for knowledge management systems. In User modeling 2003 (pp. 213–217). Berlin, Germany: Springer.
6. Golemati, M., Katifori, A., Vassilakis, C., Lepouras, G., & Halatsis, C. (2007, April). Creating an ontology for the user profile: Method and applications. Proceedings of the First RCIS Conference, p. 407–412
7. McAvoy, L. M., Chen, L., & Donnelly, M. (2012, September). An ontologybased context management system for smart environments. UBICOMM 2012, the Sixth International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, p. 18–23.
8. Liu B., Chen H., He W.:Deriving User Interface from Ontologies: A Model-based Approach, 17th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’05), Hong Kong China
9. Tregubov A.S. Razrabotka metodov adaptatsii pol'zovatel'skikh interfeisov dlya USSD-servisov // Kibernetika i programmirovanie, 2016-4 DOI: 10.7256/2306-4196.2016.4.19497 c. 1-10
10. Paulheim H., Probst F.: A Framework for Ontologies-based User Interface Integration, The 8th International Semantic Web Conference (ISWC 2009), Northern Virginia, USA, 25-29 October 2009. p. 973-981
11. Shahzad, S., Granitzer, M., Tochtermann K.: Designing User Interfaces through Ontological User Model, Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology ICCIT 2009, Seoul, Korea, 24-26 November 2009. p 99-104
|