|
Historical informatics
Reference:
Shpirko, S., Nesterov, A.Y. (2017). Text Editing Software Application Programma’s Edit within Software Complex PFuzClass of Fuzzy Genealogical Classification to Address Textological Issues. Historical informatics, 4, 67–77. https://doi.org/10.7256/2585-7797.2017.4.24627
Text Editing Software Application Programma’s Edit within Software Complex PFuzClass of Fuzzy Genealogical Classification to Address Textological Issues
Shpirko Sergey
Associate Professor, Moscow State Historical Archives Institute, Russian State University for the Humanities
119313, Russia, g. Moscow, ul. Leninskii Prospekt, 88 korpus 3, kv. 122

|
shpirkos@mail.ru
|
|
 |
Other publications by this author
|
|
|
Nesterov Andrei Yurievich
Bachelor of information science
5 Vorontsovskie Prudy ul., Moscow, Russia, 117630
|
|
andrei.nesterov@gmx.com
|
|
|
|
DOI: 10.7256/2585-7797.2017.4.24627
Received:
06-11-2017
Published:
29-12-2017
Abstract:
The authors demonstrate opportunities and discuss prospects of a new text editing software application of similar origin and general structure. This application is developed to be integrated within a program of fuzzy genealogical classification. The research focus is medieval texts which have long been in use and have been preserved in many variants. The study aims at searching links between different variants of texts that are hidden to experts and their presentation for further expert evaluation. Such an approach adapts and develops fuzzy sets theory means and thus lets us single out close groups within the variants preserved and genealogically link them to any reliability degree desired. The classification proposed bases not only on quantitative data (number of variant readings, texts proximity coefficients), but qualitative parameters as well (weight coefficients of variant readings) accounting for their importance for textological classification that has been ignored in formalized approaches before. Successful work of this software application is sure to provide a researcher with a powerful and handy tool to compare and analyze numerous medieval texts with the help of algorithm based mathematical methods.
Keywords:
weight coefficients, longest common subsequence, typology, contamination , genealogical relations, fuzzy classification, tokenization, lemmatization, collation of manuscripts, text editing
Первые попытки компьютеризации текстологического исследования мы отмечаем с 1960-х гг., на заре эпохи ЭВМ. Это прежде всего касалось задачи сравнения (коллации) [1-3] вариантов изучаемого текста, необходимой для его последующего критического издания. В этой связи необходимо упомянуть такие программы коллации как OCCULT [4] (1970) и COLLATE [5] (1973).
Одновременно с коллацией текстологам приходилось решать следующую задачу – группирование вариантов текста (списков) и установление между ними генеалого-преемственных связей. Для решения этой задачи французским ученым Фроже был предложен метод групп (1968), основанный на применении математической теории множеств [6]. Позже этот метод был развит группой московских ученых во главе с Л.И. Бородкиным и Л.В. Миловым (1977) [7]. Применяя этот метод, удается не только построить стемму, но и восстановить утраченные звенья. Отметим, что для успешного применения метода групп необходимо выполнение довольно жестких требований к модели, в частности отсутствие контаминации (правки текста по нескольким спискам).
Другой подход к реконструкции генеалогического дерева был предложен Ж. Зарри (1973) [8], в основе которого лежит развитие идей французского текстолога Кантена [9]. Идея этого подхода заключается в отыскании среди множества списков линейных структур (“характерных нулей”), формирующих отдельные ветви стеммы. Разработанная на основе предложенного подхода программа Quentin/80 генерирует всевозможные варианты стеммы, учитывая при этом и ситуации контаминации [10].
Иной подход к классификации текстов с большой рукописной традицией связан с привлечением кластерных методов. Первооткрывателями этого направления можно считать американских текстологов Колвелла и Тьюна (1963) [11]. В его основе лежит преобразование т.н. матрицы близости, полученной в результате попарного сравнения текстов списков. В конце 1980-х гг. метод Колвелла-Тьюна был развит в работах советского текстолога А.А. Алексеева [12].
Новый этап в области компьютерной текстологии начинается с конца 1980-х гг., с начала эры персональных компьютеров, и связан с появлением многофункциональных интерактивных программ, доведенных до стадии коммерческих продуктов. В этой связи необходимо упомянуть пакет программ TuStep, разрабатываемый в Тюбингенском университете с 1960-х гг. под руководством В. Отта [13], и программа COLLATE (1989) П. Робинсона из Оксфордского университета [14]. Оба программных продукта охватывают весь “производственный цикл” от ввода текста в электронный формат до его критического издания.
Отметим, что для решения задачи классификации в новой версии программы COLLATE применяется кладистический анализ [15]. Основой его является принцип экономии (парсиномии), согласно которому в процессе эволюции переход из одного состояния в другое должно произойти за минимальное число шагов [16]. Для проведения подобной классификации текстологи могут использовать программу PAUP [17], разработанную специально для биологов. Говоря о парсиномии, отметим, что на схожих принципах строят свои модели и методы такие текстологи как Деес [18] (1973), Гриффит [19] (1970-е), Ваттель [20] (2004).
Разрабатываемый авторами настоящей статьи программный комплекс PFuzClass предназначен для решения задач, связанных с нечеткой формализованной классификацией текстов, и опирается на иные подходы, чем вышеописанные. Суть этого подхода заключается в адаптации и развитии аппарата теории нечетких множеств для задачи массового сопоставления текстов с целью выявления не обнаруживаемых экспертами неявных связей с последующей экспертной оценкой их значимости. Приложение Programma’s Edit является важным элементом разрабатываемого комплекса, призванным максимальным образом облегчить исследователю ввод и обработку исходных текстовых данных и подготовку их для дальнейшей классификации.
При конструировании Programma’s Edit авторы придерживаются следующих базовых принципов: 1) “пошаговость”, переход от “простого” к “сложному”; 2) модульность; 3) наглядность и универсальность; 4) интегрированность; 5) алгоритмичность.
1. Экспорт в программу нечеткой классификации
Важнейшим особенностью приложения Programma’s Edit является его интегрированность с программой PFuzClass. Здесь уместно сказать несколько слов о самой нечеткой классификации. Объектом ее изучения являются тексты средневековых произведений. Такие тексты в процессе своего исторического бытования подвергались многочисленным изменениям, как бессознательного, так и сознательного характера. Это приводило к появлению групп близкородственных вариантов текста (списков). Ситуацию осложняет тот факт, что копиисты при переписывании могли править текст по одному или нескольким спискам, принадлежавшим к разным группам (редакциям). В этом случае говорить об однозначной принадлежности списка той или иной редакции вряд ли приходится.
Все эти соображения, по мнению авторов, весьма естественным образом вписываются и учитываются в рамках теории нечетких множеств, появившейся и интенсивно развивающейся с середины 1960-х гг. [21] На основе идеи привлечения этой теории одним из авторов настоящей статьи была предложена модель и построен формализованный алгоритм [22]. Разработанная на основе этого алгоритма программа нечеткой генеалогической классификации позволяет с заданной степенью надежности выделять из сохранившихся вариантов текста близкородственные группы и устанавливать между ними генеалого-преемственные связи.
В своих вычислениях эта программа использует матрицу нечеткого отношения, построенную в результате попарного сличения списков. Эта матрица представляет собой таблицу, число строк и столбцов которой равно количеству списков. Каждый ее элемент есть число, процент унаследованных ошибочных разночтений из одного списка в другой. Считается, что чем больше это число, тем достовернее выглядит гипотеза о том, что первый текст хронологически предшествует второму. И, наоборот, чем ближе это число к нулю, тем более независимы тексты друг от друга (располагаются на разных ветвях стеммы).
Под разночтениями понимаются не только отдельные слова, но и сочетания слов, перестановки, даже пропуски или вставки целых глав. Понятно, что все они играют неодинаковую роль для классификации: одни разночтения должны учитываться с большим весом, другие – с меньшим. Для решения этой задачи нами (Баранкова Г.С., Шпирко С.В.) была разработана типологизация разночтений [23]. Все разночтения были разбиты на 14 типов и для каждого из них одним формализованным методом вычислен вес.
В качестве ошибочных разночтений мы понимаем как непосредственные ошибки, вызванные описками, пропусками, орфографией, так и сознательное редактирование текста стилистического, идеологического, лексического характера. Таким образом, предварительный этап классификации включает “ручную” работу текстолога. В идеале каждое разночтение должно быть расценено с позиций ошибочности/нормы и отнесено к своему типу. При этом не стоит упускать из вида тот факт, что понятие уклонения от нормы могло меняться в зависимости от времени, места создания рукописи. Например, в каждом скриптории могли быть свои понятия об орфографической норме правописания. Понятно, что подобный исчерпывающий анализ текста мало осуществим. Но следует помнить, что чем детальнее будет анализ, тем актуальнее и “рельефнее” получится дальнейшая классификация.
Возвращаясь обратно к Programma’s Edit, выясним какие элементы должны обязательно присутствовать в этом приложении. Это удобно продемонстировать на примере классификации текстов древнерусского произведения “Предсловие покаянию” (20 списков) [24]. Ниже приведен фрагмент Excel-таблицы, служащей входными данными для программы нечеткой классификации.
Рис. 1
Таблица разночтений списков “Предсловия покаянию” (фрагмент)
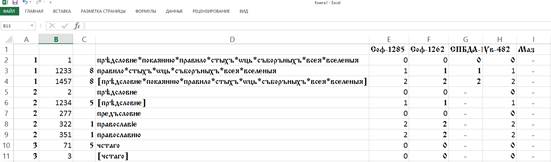
В столбце A указаны номера узлов разночтений (около 1000), в столбце B – номера разночтений (более 4500), в столбце C – их типы, а в столбце D – собственно разночтения. Каждый узел содержит несколько разночтений. Так, в первом узле располагаются три варианта названия произведения, встретившиеся у 20 его списков. Мы видим, что второй встретившийся вариант – усеченный (в нем нет начального словосочетания “предсловие покаянию”). Этому варианту присвоен восьмой тип ошибки (пропуск/изменение названия главы), имеющий высокий вес для дальнейшей классификации. Квадратные скобки третьего варианта означают пропуск, отсутствие разночтения (заглавия в данном случае) в этом узле. Так, среди 20 сохранившихся вариантов текста представлен один, у которого ввиду механической утраты листов отсутствует заглавие (Мазуринский список (РГАДА, ф. 196, оп.I, N 1700)). Этому варианту также ставится в соответствие тип 8.
Во втором узле мы видим 5 вариантов разночтений. Среди них второй – это пропуск слова (тип ошибки 5), а четвертый и пятый варианты являются лексическими изменениями (слово “предсловие” копиист заменяет на “православие”) и имеют максимальный вес (тип ошибки 1).
Каждый из последующих столбцов, начиная с E, соответствует своему списку (Соф-1262, Соф-1285, СПБДА-129 и т.д.). В этих столбцах проставляются коды ошибок: нормальные чтения для соответствующего списка помечены нулем, а ошибочные (уклонения от нормы) – любым натуральным числом, отличным от нуля. Если ошибочные варианты, соответствующие одному узлу, помечены одной цифрой, то для программы нечеткой классификации они неразличимы (например, два варианта “православие” и “православию”). Если по каким-либо причинам мы не хотим, чтобы разночтение участвовало в расчете, то оно помечается знаком тире. Такую ситуацию мы видим в Дубенском сборнике (РНБ, собр. Санкт-Петербургской Духовной Академии, N 129; помечен как СПБДА-129) и Мазуринском списке (Маз).
2. Описание приложения Programma’s Edit
Для построения классификации текстов, которые имеют общее происхождение, и которые сохраняют общую структуру, имеет смысл их хранить таким образом, чтобы связь этих текстов была наглядной. Programma’s Edit решает эту задачу, позволяя параллельно редактировать тексты, создавать новый вариант текста, исходя из уже имеющегося текста, и редактировать уже его, с возможностью сравнивать с другими вариантами текста.
На очереди стоит задача разработки новой программной функции и аналитических средств, призванных обеспечить автоматическую обработку и сравнение (сличение) вариантов текста. Эту задачу можно решать двумя способами: с привлечением заранее созданного словаря лемм или без него.
Напомним, что под леммой понимается слово (точнее, словоформа), приведенное к нормальной, словарной форме. Так, для класса существительных нормальными являются морфологические формы именительного падежа и единственного числа. В словаре лемм должны храниться все встречающиеся в тексте леммы с указанием вариантов ее окончаний и значений категорий. Например, для словоформы “предъсловие” это будет:
-е – единственное число, именительный и винительный падеж; -я – единственное число, родительный падеж и множественное число, именительный и винительный падежи; -ю – единственное число, дательный падеж и двойственной число, родительный и местный падежи и т.д.
Приложение Programma’s Edit сделано таким образом, чтобы можно было вводить данные о каждом слове, относящие его к лемме, классу и к категориям слов. Таким образом, лемматизация позволит приложению определять случаи, когда в двух разных вариантах текста стоит одно и то же слово, но в разных грамматических формах, что делает его непохожим на исходное слово.
Второй вариант сличения текстов предусмотрен в том случае, когда по каким-либо причинам нет возможности поддерживать словарь лемм. В этом случае задача заключается в том, чтобы в разумное время определить какие слова нового текста соответствуют каким словам старого текста. Например, для той же словоформы “предъсловие” равноправным вариантом является “предсловье” и т.д. Эта задача особенно важно при импорте больших кусков текста, в том числе если уже имеется вариант текста. Для ее решения в приложении Programma’s Edit предусмотрено применение одного из вариантов алгоритма поиска наибольшей общей подпоследовательности (Longest Common Subsequence) [25].
Покажем теперь, как с “программистской” точки зрения в приложении реализованы хранение и организация данных. Ниже приведена структура данных Programma’s Edit с кратким описанием основных функций.
Рис. 2
Структура данных приложения Programma’sEdit
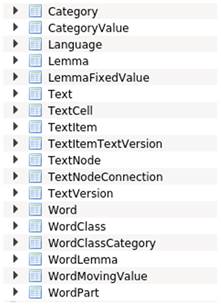
Language. Язык текста (например, древнерусский, старославянский и т.д.). Этот параметр нужен, чтобы для каждого элемента текста имелась информация о его языке. Таким образом, приложение сможет использовать данные даже других текстов для анализа, а также, если два исследователя работают над одним текстом, то есть возможность объединить их словари или тексты.
Text. Текст, то есть множество вариантов одного текста. Каждый текст имеет название (например, «Предсловие покаянию») и привязку к языку.
TextVersion. Вариант текста (список). Также имеет название и привязан к тексту. У каждого варианта есть свойства разделения текста на отдельные узлы (“разделители”). Такие разделители позволяют автоматически определять какие символы относятся к словам, а какие – нет (например, знаки препинания, скобки и т.д.)
TextNode. Узел, из которого состоит текст.
TextNodeConnection. Содержит данные о порядке узлов.
TextItem. Поле, содержащее один вариант слова. Все Text Item, принадлежащие Text Node соответствуют всем вариантам, встретившимся на данном месте. Если у нескольких вариантов текста один вариант данного слова, то это слово не разделяется на отдельные Text Item. Например, из рис.1 следует, что второму узлу (Text Node) соответствуют пять разночтений (Text Item): “предсловие”, “[предсловие]”, “предъсловие”, “православие” и “православию”.
TextItemVersion. Обеспечивает связь между Text Item и Text Version, отношение между которыми “многие-ко-многим”: каждому экземпляру Text Item соответствует несколько экземпляров Text Version и наоборот. Другими словами, каждое разночтение может встречаться в разных списках, а каждый список содержит несколько разночтений.
WordPart. Часть слова в тексте. Один Text Item может содержать несколько частей слова. Дело в том, что не всегда слово стоит слитно в тексте. Например, частица “ся” может стоять перед своим глаголом, как в списке Соф-1262 (РНБ, Софийское собрание, N 1262): “пияньства ся отстати”, “аще ся и каяти”. Возможны еще более трудные случаи, когда части одного слова отделены друг от друга другими словами: “ни ся можеть оукоренити”, “ся ныне проспить” (РНБ, Софийское собрание, N 1285, обозначено как Соф-1285).
Word. Слово в тексте. Части слова объединяются в слова.
Далее в списке данных следует блок, связанный с запланированной в приложении функцией лемматизации.
WordLemma. Привязка конкретного слова к своей лемме. Например, слово “предъсловию” относится к лемме “предъсловие”.
Lemma. Словоформа в нормальной, словарной форме. Например, “предъсловие”.
Category. Соответствует отдельной грамматической категории для данного языка. Например, таковыми в древнерусском языке для существительных являются категории падежа, числа.
CategoryValue. Значение категории. Обычно у категории может быть несколько значений. Например, значениями категории числа в древнерусском являются единственное, множественное и двойственное.
WordClass. Грамматический класс слова. Необходим, поскольку у разных классов разные категории.
WordClassCategory. Привязка категорий к классу слова.
WordMovingValue. Привязка значений категорий конкретному слову.
LemmaFixedValue. Привязка к конкретной лемме неизменяющихся значений категорий. Например, слово “чадо” имеет только одно значение рода – среднее.
3. Описание работы Programma’s Edit
Приложение Programma’s Edit (сокращенно PEdit) разработано на языке C, являющимся одним из безусловных лидеров среди систем современного программирования, позволяющим создавать приложения для работы под управлением операционных систем Microsoft Windows и Linux и, в частности, обеспечивающим интеграцию с визуальной средой обработки Delphi, в которой реализована основная часть программного комплекса. Визуальный дизайн приложения нагляден, удобен для пользователя и удовлетворяет стандартам Windows.
При запуске программы пользователю предлагается создать новый файл или открыть уже существующий.
Рис. 3
Создание файла в Programma’sEdit
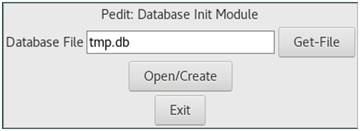
В следующем окне предлагается добавить и редактировать языки и тексты (Language и Text). В этом же окне выводятся в виде таблицы все имеющиеся варианты текста (Text Version). Для каждого из вариантов текста предусмотрена настройка собственных символов-разделителей.
Рис. 4
Создание языка, текста и варианта текста в Programma’sEdit
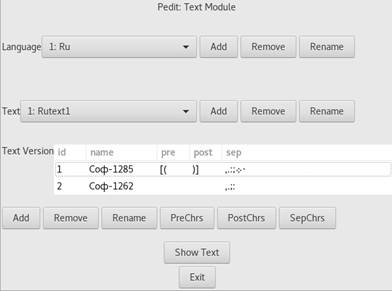
Как видно из рис. 4 такие разделители делятся на три группы: до слова (PreChrs), после слова (PostChrs) и остальные, которые могут быть либо до, либо после слова (SepChrs). Так, например, для варианта текста Соф-1285 разделителями, стоящими до слова, являются “[“, “(“. Напомним, что эти символы используются программой при импорте текста с целью разбиения его на узлы.
Следующий экран предназначен для вывода и редактирования структуры варианта текста.
Рис. 5
Редактирование текста в Programma’sEdit
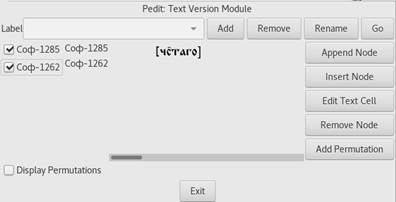
Как видно на рис.5, каждая строка таблицы редактора соответствует своему варианту текста, а столбец – узлу разночтения. Такой “горизонтальный” дизайн удобен при сравнении вариантов текста. Находясь на каком-либо узле (Node), пользователь видит соответствующие разночтения для всех вариантов текста. Например, в третьем узле в Соф-1285 стоит разночтение “[чстаго]”. С помощью кнопок, располагающихся в правой части экрана, пользователь получает возможность осуществлять стандартные операции над узлами: добавлять новые в конец (Append Node); вставлять новые перед существующим (Insert Node); удалять старые (Remove Node); менять местами (Add Permutation).
Наряду с горизонтальным в будущем запланирована разработка и вертикального редактора текстов. Необходимость в нем возникает в том случае, когда пользователю нужно видеть больше текста из каждого варианта. Эта функция будет выполнена в виде менеджера последовательного размещения (Flow Layout). Этот менеджер размещает добавляемые компоненты на экран строго по очереди, строка за строкой. Если какой-либо из элементов не умещается в текущей строке, то он переносится на следующую. При этом будет использоваться способ оперирования элементами интерфейса drag-and-drop, когда слова меняются местами путем захвата и перемещения отображаемого объекта интерфейса манипулятором “мыши”.
Опишем теперь планы на будущее, связанные с разработкой приложения Programma’s Edit. Их можно разбить на четыре группы. Во-первых, необходимо продолжать работу по доработке редактора текста: -добавлять, удалять, менять слова; -предусмотреть метки, чтобы можно было переходить на другое место текста; -вертикальный редактор.
Вторая задача состоит в разработке функции экспорта в программу нечеткой генеалогической классификации. Приложение должно быть в состоянии генерировать входные данные для PFuzClass на основе данных текста и дополнительных данных о взаимосвязи между словами узлов и насколько каждый вариант правилен для каждого узла (см. первую часть настоящей статьи).
Третья задача связана с алгоритмизацией приложения и является на наш взгляд наиболее сложной. Напомним, что речь идет о нахождении текстовых инвариантов и связана с применением алгоритма поиска наибольшей общей подпоследовательности (см. также первую часть настоящей статьи).
Наконец, с третьей тесно связана задача лемматизации, включающая разработку -редактора языков (возможность определять и менять категории, их значения и классы слов); -редактора словаря (добавление лемм и определение их значения категорий); -анализа текста (присвоение словам значения категорий и леммы).
Успешное решение поставленных задач позволит существенно продвинуться не только в направлении по разработке удобного, универсального инструментария по применению алгоритмических методов в текстологии, но и, например, создании качественного электронного корпуса исследуемых текстов, что откроет новые перспективы развития для междисциплинарного подхода в гуманитарной науке.
В заключение авторы приносит большую благодарность за внимание и ценные советы Л.И. Бородкину, чл.-корр., зав. кафедрой исторической информатики исторического факультета МГУ имени М.В. Ломоносова, и Г.С. Баранковой, ведущему научному сотруднику Института русского языка имени В. В. Виноградова.
References
1. Hockey S. A guide to computer applications in the Humanities. Baltimore and London, 1980. 248 P.
2. Oakman R. Computer methods for literary research. 2nd. rev. ed. Athens: University of Georgia Press, 1984. 235 P.
3. Hockey S. Electronic Texts in the Humanities: Principles and Practice. Oxford: Oxford University Press, 2000. 220 P.
4. Petty G. and Gibson M. Project OCCULT: The Oriented Computer Collation of Unprepared Literary Text. New York, 1970. 124 P.
5. Gilbert P. Automatic Collation: A Technique for Medieval Texts// Computers and the Humanities. Springer:1973. N 7. pp.130-147.
6. Froger J. La Critique des Textes et son Automatisation. Paris, 1968. 280 P.
7. Borodkin L.I., Milov L.V. O nekotorykh aspektakh avtomatizatsii tekstologicheskogo issledovaniya (Zakon Sudnyi lyudem)// Matematicheskie metody v istoriko-ekonomicheskikh i istoriko-kul'turnykh issledovaniyakh: sbornik statei. M., 1977. S. 235-280.
8. Zarri G. Algorythms, Stemmata Codicum and the Theories of Dom H. Quentin// The Computer and Literary Stidies/ ed. A. Aitken, R. Bailey and N. Hamilton-Smith. Edinbourgh, 1973. pp.225-237.
9. Quentin H. Essais de critique textuelle. Paris, 1926. 179 P.
10. Zarri G. Some Experiments in Automated Textual Criticism// Association for Literary and Linguistic Computing Bulletin. N 5. 1977. pp. 266-290.
11. Colwell E.C. and Tune E.W. The quantitative relationship between MS text-types// Biblical and patristic studies in memory of R.P. Casey/ Ed. by J.N. Birdsall and P.W. Thomson. Freiburg, 1963. pp. 25-32.
12. Alekseev A.A. Tekstologiya slavyanskoi biblii. Spb., 1999. 190 S.
13. Ott W. Electronic publishing und Editionen, Indizes, Wörterbücher: Anforderungen an Werkzeuge und Produkte// Literary and Linguistic Computing. 1999. N 14 pp. 423-430.
14. Robinson P. The Collation and Textual Criticism of Icelandic Manuscripts (1): Collation// Literary & Linguistic Computing. 1989. N 4(2). pp. 99-105.
15. Robinson P. and O’Hara R. Cladistic analysis of an Old Norse manuscript tradition// Research in Humanities Computing. N 4. 199. pp. 115–137.
16. Prikladnaya i komp'yuternaya lingvistika/ red. I.S. Nikolaev, O.V. Mitrenin, T.M. Lando. M., 2106. 320 S.
17. Salemans B. Building Stemmas with the Computer in a Cladistic, Neo-Lachmanian Way. Nijmegen, 2000. 735 P.
18. Dees A. Sur une constellation de quatre manuscripts// Melanges de linguistique et de literature offertes a Lein Geschiere. Amsterdam, 1975. pp.1-9.
19. Griffith J. A Three-Dimensional Model for Classifying Arrays of Manuscripts by Cluster Analysis// Studia Patristica XV/ ed. E. Livingstone. Berlin, 1984. Part I. pp. 79-83.
20. Wattel E. Constructing Initial Binary Trees in Stemmatology// Studies in Stemmatology II/ ed. P. van Reenen, M. van Mulken. Amsterdam, 2004. pp. 145-166.
21. Zade L. Ponyatie lingvisticheskoi peremennoi i ego primenenie k prinyatiyu priblizhennykh reshenii. M., 1976. 165 C.
22. Shpirko S.V. Primenenie teorii nechetkikh mnozhestv k zadache genealogicheskoi klassifikatsii v tekstologicheskom issledovanii// Istoricheskaya informatika: Informatsionnye tekhnologii i matematicheskie metody v istoricheskikh issledovaniyakh. Barnaul, 2013. № 3. S. 39-51.
23. Shpirko S.V., Barankova G.S. O nekotorykh aspektakh postroeniya formalizovannoi genealogicheskoi klassifikatsii tekstov spiskov srednevekovogo proizvedeniya s primeneniem teorii nechetkikh mnozhestv (na materiale «Zakona Sudnogo lyudem»)// Istoricheskii zhurnal: nauchnye issledovaniya. 2017. № 1. S. 56-64.
24. Barankova G.S. Sborniki didakticheskogo kharaktera, obrashchennye k iereyam i miryanam// Drevnyaya Rus'. Voprosy medievistiki. M., 2013. № 3 (53). S. 10-11.
25. Kormen T., Leizerson Ch., Rivest R., Shtain K. Algoritmy: postroenie i analiz. 2-e izd. M., 2007. 459 C.
|







