|
Cybernetics and programming
Reference:
Glushenko, S.A., Dolzhenko, A.I. (2017). Training of a Neural-Fuzzy Network Using a Genetic Algorithm. Cybernetics and programming, 5, 79–88. https://doi.org/10.25136/2644-5522.2017.5.24309
Training of a Neural-Fuzzy Network Using a Genetic Algorithm
Glushenko Sergey Andreevich
PhD in Economics
associate professor of the Department of Information Systems and Applied Computer Sciences at Rostoc State University of Economics
344002, Russia, Rostov-on-Don, str. Bol'shaya Sadovaya, 69, of. 308

|
gs-gears@yandex.ru
|
|
 |
Other publications by this author
|
|
|
Dolzhenko Aleksei Ivanovich
professor of the Department of Information Systems and Applied Computer Sciences at Rostov State University of Economics
344002, Russia, Rostov Region, Rostov-on-Don, str. B. Sadovaya, 69, of. 308
|
|
doljenkoalex@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2017.5.24309
Received:
29-09-2017
Published:
30-10-2017
Abstract:
The authors of the article describe the features of the use and advantages of the genetic algorithm for learning the neural-fuzzy network. The authors review the literature sources that consider modifications of the genetic algorithm adapted to solve various problems. The authors found that the existing approaches to the implementation of the genetic algorithm contain a number of drawbacks for learning the neural-fuzzy network, so when forming a chromosome, the interval containing the peak of the membership function is encoded with 1, otherwise it is 0. This affects the resolving power when searching for the optimal solutions. The authors of the article also discuss in detail such aspects as the operators of the basic algorithm and give the scheme of the combined method of learning the network. To teach a neural-fuzzy network based on a genetic algorithm, the authors propose an approach for coding membership functions based on the α-level. As a fitness function of the genetic algorithm, the root-mean-square error was used. The novelty of the research is caused by the fact that the authors offer their own approach of coding membership functions based on the α-level which allows to increase the resolution of the algorithm when searching for the optimal solution. The main conclusion of the research is the fact that the approach proposed in the article makes it possible to adjust the parameters of the membership functions of linguistic variables for the neural-fuzzy network and to obtain more adequate values for the parameters of the output layer of the network.
Keywords:
genetic algorithm, neuro-fuzzy network, membership function, chromosome, crossing, mutation, linguistic variable, neuron, fitness function, training
Введение
С 90-х годов ХХ века при разработке интеллектуальных систем для решения различных прикладных задач прослеживается тенденция использования гибридных моделей, представляющих собой совокупность методов имитации интеллектуальной деятельности человека, таких как нейронные сети, экспертные системы, эвристические алгоритмы и нечёткие системы. В процессе обучения нечетких моделей ряд авторов, помимо традиционных методов оптимизации, таких, как итерационные алгоритмы, используют генетический алгоритм [1],[2]. Экспериментальные исследования применения генетических алгоритмов показывают, что использование такого подхода позволяет добиться приемлемых результатов по повышению скорости и точности решаемых задач ввиду высокой скорости работы генетического алгоритма при использовании больших объёмов данных [3],[4],[5].
Генетический алгоритм при обучении нейро-нечеткой сети имеет ряд преимуществ: он обладает достаточно высокой скоростью работы (это связано с тем, что операторы работают непосредственно с двоичным представлением аргументов функции), простотой реализации и достаточной гибкостью, позволяющей создавать модификации, адаптированные для решения конкретных оптимизационных задач и задач моделирования экономических процессов. Главной особенностью генетического алгоритма является применимость его при решении задач большой вычислительной сложности (классов P и NP), причем точность решения задачи оптимизации имеет прямую зависимость от объема входных данных. Таким образом, чем больше будет размер и начальная популяция вариантов решения, тем с большей уверенностью можно говорить о корректности результатов работы. Как правило, генетический алгоритм используется для корректировки числовых значений выходов нейронной сети или настройки параметров функций принадлежности нечеткой модели [1],[6].
В [7] приводится описание реализации ГА для обучения нейро-нечеткой сети (ННС), однако в данной работе был обнаружен ряд серьёзных недостатков, а именно выявлена проблема выбора лучшего хромосомного набора, определяющего параметры соответствующих функций принадлежности (ФП), с точки зрения глобальной оптимизации – минимизации ошибки выхода ННС. Также накладывается ограничение в кодировании информации с использованием хромосом, размерностью более 10 бит, так как это приводит к малой вариабельности параметров, что в дальнейшем может негативно отразиться на результатах обучения нейро-нечеткой сети.
Описание алгоритма
Генетический алгоритм является эвристическим методом оптимизации, основанным на механике естественного отбора и природной генетике [8]. Генетический алгоритм работает с целым набором решений, и использует операторы отбора, скрещивания и мутации, чтобы скомбинировать части родительских хромосом и произвести потомство, которое будет иметь преимущества обоих родителей.
Рассмотрим подробнее операторы базового алгоритма:
1. Инициализация исходной популяции, основывающаяся на кодировании исходных данных.
2. Оценка приспособленности популяции – расчет функции приспособленности для каждой особи текущей популяции. В решаемой задаче функция приспособленности - это функция расчёта среднеквадратической ошибки a по результатам работы ННС.
3. Селекция - форма искусственного отбора, направляемая факторами внешней среды (отбор особей, показавших в ходе оценки приспособленности лучшие результаты).
4. Скрещивание - языковая конструкция, позволяющая на основе преобразования (скрещивания) хромосом родителей (или их частей) создавать хромосомы потомков [8].
5. Мутация - преобразование родительской хромосомы, или ее части для имитации влияния случайных факторов на изменчивость потомков.
6. Формирование новой популяции – группировка получившихся потомков для последующего повторения цикла оптимизации.
Схема работы комбинированного алгоритма представлена на рисунке 1.
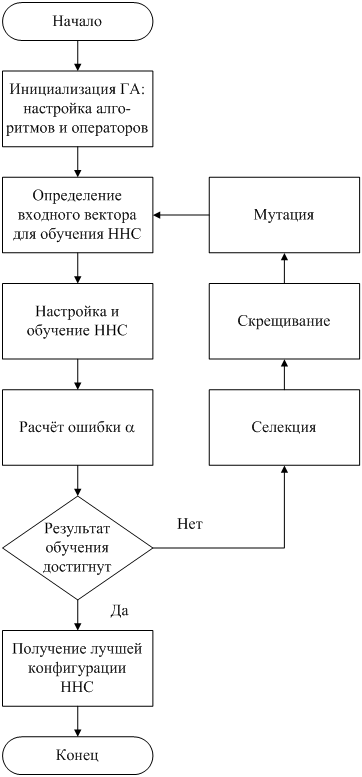
Рисунок 1 – Блок-схема комбинированного метода обучения ННС
В настоящее время существует множество модификаций ГА, адаптированных для решения различных задач. В работе [9], рассматривается модификация и адаптация к условиям конкуренции для последующего процесса моделирования этого экономического процесса. Модификации автора в [9] затронули оператор отбора ГА, используя постоянно уменьшающуюся популяцию, таким образом, была получена естественная точка останова алгоритма. Так же было предложено динамическое изменение количества точек разрыва при скрещивании пары родительских хромосом, хоть и было отмечено, что такое нововведение замедляет скорость работы алгоритма.
П.В. Казаковым была предложена кластерная модификация ГА [10]. Ее суть заключается в разбиении пространства поиска с помощью нишевых механизмов на участки (кластеры) в зависимости от границ значений целевой функции, которое позволяет получить множество оптимальных решений при условии того, что целевая функция имеет несколько локальных экстремумов. Стоит отметить, что идея разделения целевой функции на участки так же рассматривалась в трудах Бака (Bäck) [11] и Чемберса (Chambers) [12]. Кластерная модификация использовалась для автоматизации процесса планирования инвестиционных средств в рамках задачи оптимизации инвестиционного портфеля [13].
Одним из способов организации модификации самоадаптирующегося алгоритма является применение неоднородной мутации Михаэльвицем (Michalewicz) [14], заключающееся в случайной генерации мутирующего отрезка гена, вместо каноничной его перестановки. Существует метод супериндивидуального приближения для отбора особей в новую популяцию, использующийся при стратегии инцеста, разработанной и предложенной Перьяксом (Periaux) в работах [2] [15],[16],[17]. Стратегия инцеста используется как механизм самоадаптации оператора мутации. Она заключается в том, что «плотность мутации» (вероятность мутации каждого гена) определяется для каждого потомка на основании генетической близости его родителей. При супериндивидуальном приближении выбирается наилучшая особь среди числа родителей и их потомков — элитная хромосома. Все хромосомы новой популяции являются копиями этой элитной хромосомы, что повлечет за собой сильные мутации в последующем поколении. Эта модификация, как и модификация с методом неоднородной мутации, пригодны для решения оптимизационных задач различного плана, так как имеет пониженную уязвимость попадания в локальный экстремум целевой функции.
Кодирование в задаче
В контексте генетического алгоритма область значений каждой лингвистической переменной нейро-нечеткой сети рассматривается как пространство, разбитое на конечное число интервалов [18]. Например, если заданный интервал содержит пик функции принадлежности, то он кодируется с помощью 1, в противном случае – 0. Закодированная строка, соответствующая функции принадлежности для одной переменной, называется хромосомой, а элементы 0 или 1 – генами. Увеличение числа генов, составляющих хромосому (т. е. числа интервалов разбиения области значений) приводит к увеличению разрешающей способности поиска оптимального решения. Вместе с тем, чем более высокое разрешение имеет разбиение, тем быстрее происходит рост числа потенциальных решений («комбинаторный взрыв»), что в свою очередь приводит к значительному увеличению трудоёмкости.
Данный подход целесообразно использовать лишь при фиксированном выборе числа нечетких множеств, используемых для оценки всех входных и выходных параметров модели, а также базы правил и остальных элементов модели, так как в этом случае ее точность будет зависеть только от координат пиков отдельных функций принадлежности - от расположения единиц в хромосомах.
Рассмотрим возможность настройки ФП на отдельных отрезках, соответствующих трём неопределённостям («низкий» 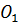 , «средний» , «средний»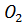 и «высокий» и «высокий» 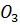 ), описывающим оценку эксперта с уровнем уверенности в своём выводе. Например, «особь» генетического алгоритма, полученная из лингвистической переменной (ЛП) ), описывающим оценку эксперта с уровнем уверенности в своём выводе. Например, «особь» генетического алгоритма, полученная из лингвистической переменной (ЛП) 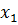 будет иметь набор из 3 хромосом будет иметь набор из 3 хромосом 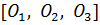 . Такой принцип кодирования подходит для всех ЛП модели. . Такой принцип кодирования подходит для всех ЛП модели.
Обозначим границы для каждого из отрезков 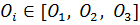 , например, используя α-уровень = 0,5 и получим 2 точки пересечения , например, используя α-уровень = 0,5 и получим 2 точки пересечения 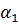 и и 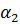 (рисунок 2). Также можно использовать заданные размеры отрезка. Таким образом, отрезок определён на интервале (рисунок 2). Также можно использовать заданные размеры отрезка. Таким образом, отрезок определён на интервале 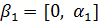 , , 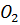 на интервале на интервале 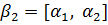 , на интервале , на интервале 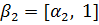 . .
Рисунок 2 – Исходные ФП нейрона 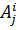 с α-уровнем 0,5 с α-уровнем 0,5
Разобьем отрезок 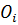 на на 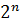 интервалов, с наложением ограничения n ³ 10 для получения приемлемой вариабельности особей для работы операторов генетического алгоритма. Так параметр интервалов, с наложением ограничения n ³ 10 для получения приемлемой вариабельности особей для работы операторов генетического алгоритма. Так параметр 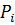 , соответствующий отрезку , будет принимать одно из 1024 значений от минимального значения , соответствующий отрезку , будет принимать одно из 1024 значений от минимального значения 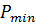 до максимального значения до максимального значения 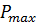 , которые будут являться двоичными представлениями хромосомы вида [0000000000] для и [1111111111] для из хромосомного набора мощностью (рисунок 3). , которые будут являться двоичными представлениями хромосомы вида [0000000000] для и [1111111111] для из хромосомного набора мощностью (рисунок 3).
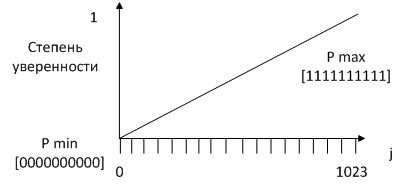
Рисунок 3 – Пример двоичного представления для n=10
Стартовая популяция ГА в задаче обучения ННС задаёт множество прототипов ФП для каждого нейрона. Ввиду большого количества вычислений её размер S сделан варьируемым между 10% и 20% от мощности хромосомного набора (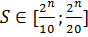 ) и задаётся в начале процесса обучения. В качестве инструмента создания стартовой популяции можно использовать как генератор случайных чисел с соответствующим законом распределения, так и простые алгоритмы заполнения массива – циклическое увеличение или уменьшение с определённым шагом, или их сочетание. ) и задаётся в начале процесса обучения. В качестве инструмента создания стартовой популяции можно использовать как генератор случайных чисел с соответствующим законом распределения, так и простые алгоритмы заполнения массива – циклическое увеличение или уменьшение с определённым шагом, или их сочетание.
Генетические операторы скрещивания, мутации и отбора позволяют получить следующее поколение особей и отбирать наиболее приспособленные особи, которые в большей степени удовлетворяют значению функции приспособленности – фитнесс-функции, производя корректировку функции принадлежности и тем самым обучение ННС (рисунок 4).

Рисунок 4 – Корректировка функции принадлежности
Операторы скрещивания и мутации носят вероятностный характер, параметры которого задаются перед началом работы алгоритма обучения. После одного эволюционного шага популяция увеличивается вдвое, так как двое родителей порождают пару потомков, а оператор отбора удаляет половину наименее приспособленных особей, сохраняя численность популяции на одном уровне.
В качестве фитнесс-функции генетического алгоритма будем использовать среднеквадратичную ошибку выхода i-го нейрона обучаемого слоя ННС для j-го обучающего образа:
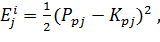
где: 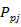 - требуемый выход нейрона , данные из обучающей выборки; - требуемый выход нейрона , данные из обучающей выборки; 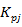 -фактический выход нейрона , согласно текущей функции принадлежности; -фактический выход нейрона , согласно текущей функции принадлежности;
Достижение такой формы ФП, при которых 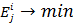 является обучением нечёткой нейронной сети. является обучением нечёткой нейронной сети.
Средняя ошибка обучаемого слоя ННС для j-го обучающего образа вычисляется по формуле:
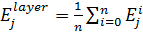 , ,
где n - количество нейронов слоя, а для всей обучающей выборки, содержащей m примеров, ошибка выхода сети будет рассчитываться следующим образом:
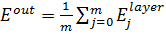 , ,
Ошибка 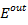 используется для проверки результатов обучения сети целиком и сравнивается с ошибкой используется для проверки результатов обучения сети целиком и сравнивается с ошибкой 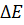 , которая задаётся в ходе выбора параметров обучения в начале работы. При , которая задаётся в ходе выбора параметров обучения в начале работы. При 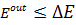 функции принадлежности нейронов настроены на заданном уровне, и процесс обучения останавливается (рисунок 5). функции принадлежности нейронов настроены на заданном уровне, и процесс обучения останавливается (рисунок 5).
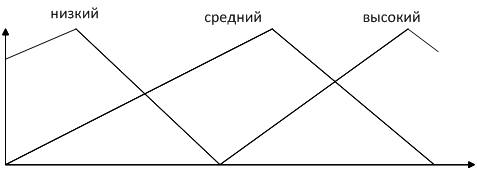
Рисунок 5 – Скорректированные функции принадлежности для трех нечётких множеств
Заключение
Предложенный в статье подход позволяет провести корректировку параметров функций принадлежности лингвистических переменных для нейро–нечеткой сети и получить более адекватные значения выходного слоя.
Можно также выделить дальнейшие направления развития методов обучения ННС: развитие ГА в форме применения различных стратегий и соответствующих модификаций ГА (стратегия «элитизма», инцеста, супер-индивидуального приближения, вариации генетических операторов и другие), и комбинирование ГА с другими методами обучения ННС (методы градиентного спуска, обратного распространения ошибки для сети со скрытыми слоями, «метод отжига» для первичного задания весов). Развитие методов обучения, состоящее в компоновке авторских модификаций с существующими методами, позволит повысить точность модели и уменьшить время обучения сети.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 16-31-00285 мол_а «Методы и модели нечеткой логики в системах принятия решений управления рисками».
References
1. Katasev A.S., Akhatova Ch.F. Neironechetkaya model' formirovaniya baz znanii ekspertnykh sistem s geneticheskim algoritmom obucheniya // Problemy upravleniya i modelirovaniya v slozhnykh sistemakh: Trudy XII Mezhd. konferentsii / Pod red. akad. E.A. Fedosova, akad. N.A. Kuznetsova, prof. V.A. Vittikha. Samara: Samarskii nauchnyi tsentr RAN. 2010. S. 615-621.
2. Periaux J., Sefrioui M., Ganascia J.G. Fast Convergence Thanks to Diversity // Evolutionary computing. — San Diego, 1998. pp. 9-15.
3. Shumkov E.A., Chistik I.K. Ispol'zovanie geneticheskikh algoritmov dlya obucheniya neironnykh setei // Politematicheskii setevoi elektronnyi nauchnyi zhurnal Kubanskogo gosudarstvennogo agrarnogo universiteta, № 91, 2013. S. 455-464.
4. Aydogan E.K., Karaoglan I., Pardalos P.M. Hybrid genetic algorithm in fuzzy rule-based classification systems for high-dimensional problems // Applied Soft Computing, Vol. 12, No. 2, 2012. pp. 800-808.
5. Grafeeva N., Grigorieva L., Kalinina-Shuvalova N. Genetic algorithms and genetic programming // International Journal of Advanced Computer Science and Applications, Vol. 3, No. 9, 2013. pp. 465-480.
6. Katasev A.S. Neironechetkaya model' i programmnyi kompleks formirovaniya baz znanii ekspertnykh sistem. Kazan': Avtoref. diss. na soisk. uch. step. k-ta tekhn. nauk, 2006. 20 s.
7. Klawonn F., Nauck D., Kruse R. Generation Rules from Data by Fuzzy and Neuro-Fuzzy Methods. Darmstadt: Proc. of the Third German GI-Workshop “Fuzzy-Neuro-Systeme’95”, 1995. 335 pp.
8. Gladkov L.A., Kureichik V.V., Kureichik V.M. Geneticheskie algoritmy. Moskva: Fizmatlit, 2004. 250 s.
9. Stepanov L.V. Modelirovanie konkurentsii v usloviyakh rynka. M.: Izdatel'stvo "Akademiya Estestvoznaniya", 2009. 397 s.
10. Kazakov P.V. Klasternoe rasshirenie geneticheskogo algoritma dlya resheniya mnogoekstremal'nykh zadach optimizatsii // Informatsionnye tekhnologii, № 8, 2009. S. 33-38.
11. Bäck T., Fogel D., Michalewicz Z. Evolutionary computations // Advanced algorithms and operators, No. 4, 2000. pp. 23-30.
12. Chambers L. Practical handbook of genetic algorithms: new frontiers // CRC Press, No. 2, 1995. pp. 67-78.
13. Kazakov V.P. Avtomatizatsiya sinteza optimal'nykh investitsionnykh portfelei na osnove klasternogo geneticheskogo algoritma // Informatsionnye tekhnologii, № 12, 2010. S. 38-42.
14. Michalewicz Z. Genetic algorithms + Data Structures = Evolution Programs. New York: Springer-Verlag, 1996. 387 pp.
15. Periaux J., Sefrioui M. Evolutionary computational methods for complex design in aerodynamics. Reno. 1998. 150 pp.
16. Periaux J., Chen H.Q., Mantel B., Sefrioui M., Sui H.T. Combining game theory and genetic algorithms with application to DDM-nozzle optimization problems // Finite Elements in Analysis and Design, Vol. 37, No. 5, 2001. pp. 417-429.
17. Periaux J. Genetic Algorithms for electromagnetic backscattering multiobjective optimization // Genetic algorithms for Electromagnetic Computation, No. 6, 1998. pp. 30-39.
18. Glushenko S.A. An adaptive neuro-fuzzy inference system for assessment of risks to an organization’s information security // Business Informatics. 2017. № 1 (39). P. 39-50
|







