|
Software systems and computational methods
Reference:
Gusenko, M. (2017). The use of regular expressions for decompiling static data. Software systems and computational methods, 2, 1–13. https://doi.org/10.7256/2454-0714.2017.2.22608
The use of regular expressions for decompiling static data
Gusenko Mikhail
PhD in Technical Science
Associate Professor, Department of Applied and Business Informatics, Moscow Technological University
119454, Russia, Moscow, pr-t Vernadskogo, 78, of. 418

|
mikegus@yandex.ru
|
|
 |
Other publications by this author
|
|
|
DOI: 10.7256/2454-0714.2017.2.22608
Received:
07-04-2017
Published:
06-05-2017
Abstract:
The subject of the study is the process of decompiling the source code of programs into high-level languages. The author shows the decompilation point in the program transformation cycle which includes the processes of canonization, compilation, optimization, and decompilation. The object of the study is the compiled equivalent of the static data description on a high level programming language, which in general case is a nontrivial mapping of syntactic constructions on a high level programming language into a byte sequences located in executable program modules and constructed considering various optimization techniques for this microprocessor architecture. The paper reviews the static data decompilation process as reconstruction of the parse tree of the program, which is recovered during the analysis of its executable code and as a binary sequence in the memory of the von Neumann machine, which is analyzed by the regular expression created by the decompiler from the supposed description of the data. Regular expressions are traditionally used to analyze character sequences. The article presents another area of application of this tool – for proving the hypothesis that this byte array of the executable module is the equivalent of compiled static data. The author suggests a variant of the corresponding syntax of the regular expression language. The article shows that the proposed method can be used to further verify the quality of the decompiled code.
Keywords:
translation, reverse translation, decompilation, regular expression, program language, compilation, executable module, object code, program parsing tree, data definition
Применение регулярных выражений в задачах декомпиляции статических данных
Образы исполняемых модулей, являющихся результатом трансляции с языков высокого уровня, содержат семантически различные бинарные фрагменты следующего вида:
1. бинарные образы машинного кода команд процессора;
2. бинарные образы данных программы;
3. бинарные образы служебных структур данных, используемых, например, загрузчиком исполняемых модулей операционной системы для формирования образа процесса.
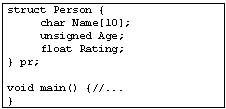
При трансляции программы с языка С (листинг 1) будет построен исполняемый модуль, содержащий транслированный образ статической переменной pr и функции main. Служебные структуры данных не имеют непосредственного прообраза в программе на исходном языке (хотя могут косвенно указывать, например, на структуры поддержки динамической компоновки, что уже может выражаться в тексте программы некоторым образом), поэтому далее они, как и образы машинного кода, не рассматриваются. Хотя декомпиляция машинного кода представляет существенный интерес наряду с декомпиляцией статических данных, но это не предмет данной статьи и будет рассмотрена отдельно.
Листинг 1. Программа с явно инициализированными данными на языке С

Список сокращений, используемых в статье.
|
Сокращение
|
Описание
|
|
UCS-индекс
|
Индекс символа в унифицированной кодовой последовательности (Universal Coded Character Set) в UNICODE (ISO/IEC 10646 [3])
|
|
UTF
|
Формат преобразования (Unicode Transformation Format) UNICODE (ISO/IEC 10646 [3])
|
|
ECMAScript
|
Язык программирования JavaScript в версии, изложенной в стандарте ECMA-262, выпущенном ассоциацией European Computer Manufacturers Association [7]
|
|
ПО
|
Программное обеспечение
|
|
ЯВУ
|
Язык высокого уровня
|
1 Постановка задачи
Статические данные в исходной программе на языке высокого уровня (ЯВУ) транслируются в семантически эквивалентные фрагменты объектного кода, из которых, вместе с транслированными фрагментами объектного кода команд, на этапе компоновки формируется исполняемый модуль.
При трансляции теряется часть информации, присутствующей в исходном коде. Например, это касается имен данных, процедур, меток, констант, комментариев т.п., и, таким образом, производится информационное сжатие программы до состояния, когда она содержит только сущностно необходимое для исполнения. При декомпиляции производится восстановление исходного кода, который из-за потери информации при компиляции лишь частично напоминает исходный код программы, хотя семантически может быть эквивалентен.
На рис. 1,а представлен программный цикл [8]. Циклическая трансформация программы представляется в виде последовательно исполняемых процессов: компиляции, оптимизации, декомпиляции, канонизации. Указанные четыре процесса образуют идеализированный программный цикл, напоминающий цикл Карно (Carnot) в термодинамике, который, как и в случае тепловых процессов, не реализуем в действительности из-за потери информации при выполнении каждого процесса трансформации. Упрощенный вариант цикла представлен на рис. 1,б.
Канонизация - это процесс перевода программы в каноническую форму раскрытием циклов, заменой вызовов процедур самими процедурами и обращением процесса оптимизации, что увеличивает энтропию, но сохраняет уровень представления программы. Оптимизация - процесс уменьшения энтропии с сохранением низкоуровневого представления программы. Компиляция (трансляция) программы с языка высокого уровня (из исходного кода) на язык низкого уровня (в объектный код) - это прямое преобразование, уменьшающее уровень представления программы. Декомпиляция программы с языка низкого уровня (из объектного кода) на язык высокого уровня (в исходный код) - обратное преобразование, увеличивающее уровень представления программы.
Аналогия с тепловыми процессами позволяет обосновать итеративность процесса декомпиляции с участием внешнего источника информации (энергии в случае цикла Карно). Многократное выполнение программного цикла с добавлением информации на каждом его витке позволит получать все более точное воспроизведение конструкций исходного кода, который минимально отличается (с учетом семантически эквивалентных трансформаций) от кода на ЯВУ изначально скомпилированной программы, при условии, конечно, что целевой язык декомпиляции и исходный язык программы один и тот же. Если исходный язык в A' (рис. 1,б) при переходе A'®B - исходный язык программы - отличается от языка в A' при переходе B®A' - целевого языка декомпиляции, то сравнение исходного и декомпилируемого текста синтаксически будет невозможно, но семантически вполне допустимо.
Внешняя информация может собираться и сообщаться декомпилятору автоматизированным способом или вручную, но в любом случае неизбежно участие человека - аналитика, который занят восстановлением исходного кода программы. Работа аналитика может включать, например, восстановление идентификаторов, передающих семантику языковых конструкций, исключение неоднозначностей в эквивалентных конструкциях на ЯВУ, построенных для фрагментов объектного кода и т.д. Восстановление идентификаторов аналитик может осуществлять на основе понимания предметной области программы, понимания, пусть и постепенного, алгоритмов, реализованных в программе и т.д.
|
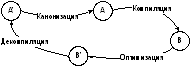
|
|
|
а
|
б
|
Рис. 1. Идеализированный программный цикл
Итерации декомпиляции иллюстрирует рис. 2. При первой итерации получается текст на ЯВУ в некотором начальном качестве. На его основе и с учетом приобретенного знания об устройстве работы программы создаются спецификации для выполнения второй итерации декомпиляции. Далее, поскольку, например, в получаемом исходном коде уже расставляются семантические имена, логика работы программы становиться еще более четкой, это ведет к пониманию работы остальных ее частей, что выражается в спецификациях для третьей итерации декомпиляции и т.д. Вся работа останавливается, когда исходный код достигает приемлемого качества.

Рис. 2. Итерации декомпиляции
Результатом декомпиляции статических данных может быть такое представление информации, которое либо непосредственно выразимо на целевом языке декомпиляции, либо обеспечивает семантически-эквивалентное описание. Описание на ЯВУ минимизирует необходимую правку входных спецификаций вручную и согласуется со всем потоком работ по восстановлению исходного кода. Однако декомпиляция не всегда может преследовать цель получения именно повторно компилируемого исходного кода программы. Целью может быть изучение алгоритмов, реализованных в программе, которые обрабатывают некоторым образом представленные данные. В этом случае результатом декомпиляции может быть спецификация данных на некотором другом языке, отличном от компилируемых ЯВУ, например, в виде XML-скрипта (листинг 2).
Листинг 2 XML-скрипт описания структуры данных листинга 1
2 Итерационная декомпиляция типов данных
Исходя из того, что тип данных в ЯВУ определяется, в том числе, и набором операций, выполняемых с элементом данных этого типа, то определение, какие же участки образа исполняемого модуля являются образами статических данных, производится при анализе операндов команд в дизассемблированном коде программы. Анализ операндов позволяет вычислить пространственные (адресные) атрибуты элементов данных. Операционная семантика же команд, выполняющих вычисления с этими элементами, позволяет определить семантику типов данных. В листинге 3 показан дизассемблированный код программы для листинга 1.
Листинг 3. Дизассемблированный код программы листинга 1
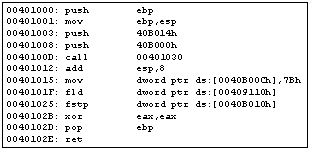
Далее будем вести анализ, предполагая, что исходный код программы неизвестен. Применяя метод поиска паттернов библиотечных функций, реализованный, например, в дизассемблере IDA, можно определить, что команды с адресами 0x401003 до 0x401012 реализуют вызов библиотечной CRT-функции strcpy, что по ее интерфейсу позволяет определить типы данных по адресам 0x40B014 и 0x40B000. Команда по адресу 0x401015 позволяет судить об использовании ячейки памяти с адресом 0x40B00C для хранения 32-битного значения, предположительно, целого. Команды по адресам 0x40101F и 0x401025 позволяют судить о записи 32-разрядного значения с плавающей точкой из ячейки с адресом 0x409110 в ячейку с адресом 0x40B010. В результате декомпилятором может формироваться абстрактное описание, представляющее дерево разбора программы (рис. 3), и которое аналогично тому, что строится компилятором при прямом преобразовании. Только при компиляции дерево разбора строится на основании грамматических конструкций языка программирования, а при декомпиляции оно строится на основе вычисляемых по объектному коду атрибутов.

Рис. 3. Фрагмент дерева разбора программы для данных листинга 3
Для прочих данных также формируются вершины дерева разбора. Результирующее дерево позволяет на первой итерации декомпиляции программы представить следующее описание кода на С:

Аналитик, получив данное описание, с учетом возможного изучения других фрагментов программы, где эти данные также используются, может предположить, что по адресу 0x40B000 размещается структура данных вида:

Формирование такого описания типа и будет являться спецификацией информации для следующей итерации декомпиляции, что позволит во вновь полученном декомпилированном исходном коде получить выражения не с отдельными данными, а с данными в структуре - с полями структуры. Дерево разбора программы в этом случае уже изменит свой вид (рис. 4).
Использование структуры как семантического контейнера позволит детальнее понять семантику кода, вновь уточнить описание, записав вместо малоинформативного идентификатора s_0x40B000 идентификатор Name, вновь выполнить итерацию декомпиляции и т.д.
Описанный процесс декомпиляции данных можно назвать построением описаний данных на основе анализа команд. Это довольно трудоемкий процесс, требующей высокой квалификации аналитика. Сложность его в том, что он в изрядной степени основан на анализе команд, которые напрямую обращаются к данным. Использование в коде на исходном ЯВУ косвенной адресации, особенно, когда это производится через параметры в вызовах подпрограмм, существенно увеличивает трудоемкость процесса. Дополнительную трудность привносит слабая типизация, используемая в таких языках программирования как С/С++, в которых, кроме того, еще и разрешена операция явного приведения типа, которая в объектном коде вообще может не выражаться ни в каких дополнительных командах.
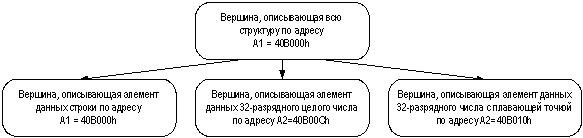
Рис. 4. Фрагмент дерева разбора программы для данных листинга 3 с размещением данных в структуре
Перечисленные трудности существенны, приводят к трудоемкому процессу декомпиляции, и позволяют предложить несколько иной подход к декомпиляции статических данных.
3 Использование регулярных выражений
В исходном коде программ на компилируемых языках могут определяться статические инициализированные данные, пример которых представлен в листинге 1. Образы статических неинициализованных данных, точнее говоря, инициализируемых по умолчанию, обычно не содержатся в исполняемых модулях и формируются загрузчиком программ в ОС. Для языка С/С++ принято все явно неинициализированные статические данные (листинг 4) инициализировать нулевым значением. Бинарные образы таких данных не могут быть типизированы без анализа исполняемого кода, что возвращает к процессу, описанному в п. 2.
Листинг 4. Программа с неявно инициализированными данными на языке С
При трансляции же явно инициализированных данных в исполняемом файле формируются эквивалентные последовательности байтов. Для данных листинга 1 формируется бинарный образ, представленный на рис. 5.
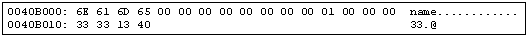
Рис. 5. Дамп транслированных статических данных листинга 1
Синтаксическое представление структур данных в исходном коде на ЯВУ, вообще говоря, не тождественно их представлению в объектном коде, на построение которого влияют следующие особенности:
― необходимость выравнивания фрагментов структур данных на некоторую границу. Это зависит от требований аппаратной платформы: для 32-разрядной платформы поля структур данных обычно выравниваются на 4-х-байтовую границу, для 64-разрядной платформы - на 8-ми-байтовую и т.д.;
― реализация типов языка в данной исполняемой среде. При реализации языка для простых типов данных разработчики могут использовать различные модели. Например, для компиляторов с С/С++ под VAX Unix применялась модель ILP32, в которой тип long long не поддерживался, а все целые типы были не более, чем 32-разрядными. В модели целочисленных данных IPL32LL тип long long уже поддерживается. В модели IPL64 большинство целых типов 64-разрядные и т.д. Модели целочисленных типов данных для реализации языков С/C++ показаны в табл. 1;
― использование конкретных кодовых страниц для представления символьных данных. Стандарт языка C (С99 [1]) как и стандарты языка С++ (C++98 [4], C++03 [5]) для представления символьных данных допускали два типа char и wchar_t. Реализация первого предполагала использование некоторой кодовой страницы, которая либо указывается для транслятора как параметр настройки, либо в нем используется только конкретная кодовая страница. Второй тип реализовывался выбранной UTF-системой кодирования. Стандарт С++14 ([6]) значительно разнообразил систему кодирования строковых литералов в исходном коде программы. Использование расширенного набора префиксов в дополнение к ранее использованному префиксу L (табл. 2) придало новой версии языка С++ большую гибкость, но и, естественно, увеличило вариативность представления объектного кода;
― синтаксическими и семантическими ограничениями исходного языка или предполагаемого транслятора. Например, какие-то типы не могут являться типами элементов массива в реализации языка на данной платформе.
Табл. 1. Модели данных для реализаций языков С/С++
|
Тип систем
|
short
|
int
|
long
|
ptr
|
long long
|
Обозначение
|
Примеры компьютерных платформ
|
|
16-разрядные
|
…
|
16
|
…
|
16
|
…
|
IP16
|
PDP-11 Unix (1973)
|
|
16
|
16
|
32
|
16
|
…
|
IP16L32
|
PDP-11 Unix (1977): реализация типа long производилась двумя машинными словами
|
|
16/32-разрядные
|
16
|
16
|
32
|
32
|
…
|
I16LP32
|
MC680x0 (1982): Apple Macintosh 68K; Операционные системы Microsoft (с расширением для 32-разрядных сегментов x86)
|
|
32-разрядные
|
16
|
32
|
32
|
32
|
…
|
ILP32
|
IBM 370; VAX Unix; большая часть рабочих станций
|
|
16
|
32
|
32
|
32
|
64
|
ILP32LL или ILP32LL64
|
Microsoft Win32; Unix-системы 1990-х Модель подобна модели IP16L32, к которой добавлены тип long long и операции c ним
|
|
64-разрядные
|
16
|
32
|
32
|
64
|
64
|
LLP64 или IL32LLP64 или P64
|
Microsoft Win64 (X64/IA64)
|
|
16
|
32
|
64
|
64
|
64
|
LP64 или I32LP64
|
Большинство Unix-систем (Linux. Solaris, DEC OSF/1 Alpha, SGI Irix. HP UX 11)
|
|
16
|
64
|
64
|
64
|
64
|
ILP64
|
HAL; логический аналог модели ILP32
|
|
64
|
64
|
64
|
64
|
64
|
SILP64
|
UNICOS
|
PDP-11 – серия 16-разрядных мини-ЭВМ компании DEC, серийно производившихся и продававшихся в 1970-80-х годах. Перенос кода операционной системы UNIX на платформу PDP-11 был как раз был решен за счет разработки языка С и переписывания кода ядра UNIX на вновь разработанном языке.
MC680x0 — семейство CISC-микропроцессоров компании Motorola, основной конкурент процессоров семейства Intel x86 в персональных компьютерах 1980-х и начале 90-х. На базе этих процессоров было построено множество платформ персональных компьютеров, самыми известными из которых является Apple Macintosh. Язык ассемблера процессора схож с ассемблером PDP-11. Архитектура M680x0 во многом – это 32-битовая версия PDP-11.
x86 – обозначение семейства процессоров как Intel, так и других производителей, в частности, AMD, совместимых на уровне программного интерфейса.
Системы, выпускаемые HAL Computer Systems, Inc на 64-разрядных RISC-процессорах SPARC V9. Эти процессоры, известные как SPARC64, поддерживали внеочередное исполнение (out-of-order execution) команд - исполнение команд не в порядке следования в машинном коде (как делается при выполнении инструкций по порядку - in-order execution), а в порядке готовности к выполнению. Реализуется с целью повышения производительности вычислительных устройств.
UNICOS – название нескольких вариантов операционной системы Unix, созданных компанией Cray для своих суперкомпьютеров. В суперкомпьютере достижение производительности достигается за счет ущерба в экономии памяти, поэтому реализация типов данных производится одним машинным словом постоянной длины.
Табл. 2. Префиксы и реализация строковых литералов языка C++ [6]
|
Префикс
|
Пример использования
|
Описание
|
|
нулевой
|
"..."
|
Символы строки реализуются однобайтовым типом char с применением некоторой таблицы кодировки.
|
|
u8
|
u8"..."
|
Символы строки реализуются в кодировке UTF-8 ([6], п. 2.14.5.8), следовательно, число байтов представления строки будет варьироваться в зависимости от позиции соответствующего символа в UCS-последовательности Unicode (стандарт ISO 10646).
|
|
u
|
u"..."
|
Символы строки реализуются на основе типа char16_t, используемого для каждого символа ([6],п. 2.14.5.8). Тип char16_t - новый базовый тип С++. Для кодирования символов может применяться UTF‑16LE или UTF-16BE в зависимости от требований целевой операционной среды
|
|
U
|
U"..."
|
Символы строки реализуются на основе типа char32_t, используемого для каждого символа ([6], п. 2.14.5.10). Тип char32_t - новый базовый тип С++. Для кодирования символов может применяться UTF‑32LE или UTF-32BE в зависимости от требований целевой операционной среды.
|
|
L
|
L"..."
|
Символы строки реализуются на основе типа wchar_t, который совпадает либо с char16_t, либо с char32_t, что определяется разработчиками компилятора ([6], п. 3.9.1.5).
|
Перечисленные выше особенности реализации статических данных ведут к необходимости применения специального метода анализа последовательностей байтов объектного кода для оценки того, что они являются бинарным образом структур данных, описанных на ЯВУ. Проводя аналогию с ранее описанным процессом (п. 2) его можно назвать процессом проверки описаний данных ЯВУ по их реализации.
Этот подход основывается гипотезе, что по некоторому смещению в исполняемом файле (или адресу в образе процесса) размещаются последовательности байтов, составляющих транслированный эквивалент определения данных на исходном языке. Для принятия или опровержения гипотезы необходимо, во-первых, сформировать описание того образа, который может быть получен при трансляции представленного описания данных на ЯВУ; во-вторых, провести собственно сравнение описания образа с фактическим фрагментом данных в объектном коде.
Для формирования описания образа удобно использовать регулярные выражения, основанные, например, на ECMAScript-грамматике ([6], п. 28.13).
Для иллюстрации применения подхода рассмотрим структуры данных листинга 5.
Листинг 5. Примеры определения статических данных на языках С и Pascal
|
на C
|
на Pascal
|
|

|

|
Тогда структурное описание образов для примеров листинга 5 имеет вид:
― для каждого элемента массива T в программе на C:
<последовательность символов, завершаемая - реализация char Name[10]>
<байты выравнивания 1>
<реализация float Raiting>
<байты выравнивания 2>
<реализация ZODIAС Sign>
<байты выравнивания 3>
<реализация Birthday>
― для каждого элемента массива T в программе на Pascal:
<фактическая длина строки Name>
<реализация Raiting : Real>
<реализация Sign : ZODIAC>
Для описания образов этих данных сформируем регулярное выражение, в котором в отличие от традиционного выражения, предназначенного для обработки символьных последовательностей, используется свое оригинальное множество специальных символов (табл. 3). Каждый из этих символов выражает позиционную ссылку на соответствующий бинарный паттерн данных в объектном коде. Естественно, что этот паттерн должен удовлетворять специфике реализации соответствующего типа данных. Например, символ uc32 может соответствовать последовательности байтов в объектном коде, которая имеет либо LE (little-endian), либо BE (big-endian) размещение. Кроме того, численное значение этой последовательности байтов должно быть в диапазоне 0x0 - 0x10FFFF, т.е. удовлетворять диапазону UCS-индексов ISO 10646 [3]. Аналогично, если dp соответствует последовательности байтов представимого на ЯВУ числа с плавающей точкой, то следует проверять описание далее, иначе, если байты представляют бесконечность или NaN, то описание не соответствует реальным данным. Если байты кода анализируются на равенство c - представлению символов в однобайтовой кодировке, то также рассматриваются допустимые ("печатаемые") и недопустимые ("непечатаемые") символы. Например, только часть из значений 0-0x1F таблицы ASCII представляются в строковых литерах языка С в виде escape-последовательностей. Остальные могут считаться недопустимыми.
Если последовательность байтов не удовлетворяет таким ограничениям, то образ данных, описанный регулярным выражением, не соответствует типу данных, для которого это выражение сформировано, и гипотеза о соответствии типа данных данному адресу в памяти отвергается.
На обозначения специальных символов регулярного выражения (табл. 3) налагаются ограничения автоматной грамматики, т.е. для любой пары констант одна из них не может совпадать с началом другой.
Обозначения квантификаторов, групп и утверждений регулярного выражения (возможно, с некоторым добавлением) могут быть такими же, как и у ECMAScript-выражения.
Табл. 3. Константы регулярного выражения для анализа статических данных
|
Константы
|
Назначение
|
|
sb, ub
|
знаковое/беззнаковое 8-разрядное целое
|
|
sw, uw
|
знаковое/беззнаковое 16-разрядное целое
|
|
sd, ud
|
знаковое/беззнаковое 32-разрядное целое
|
|
sq, uq
|
знаковое/беззнаковое 64-разрядное целое
|
|
c
|
однобайтовый ненулевой символ в кодировке, которая определяется реализацией интерпретатора конечного автомата
|
|
uc8
|
многобайтовый широкий ненулевой символ в кодировке UTF-8
|
|
uc16
|
многобайтовый широкий ненулевой символ в кодировке UTF-16, вид которой (LE или BE) определяется реализацией интерпретатора конечного автомата, реализующего регулярное выражение
|
|
uc32
|
многобайтовый широкий ненулевой символ в кодировке UTF-32, вид которой (LE или BE) определяется реализацией интерпретатора конечного автомата, реализующего регулярное выражение
|
|
sp, dp, ldp
|
32-разрядное, 64-разрядное, 80-разрядное вещественное
|
|
e[ descriptor ]
|
константа перечислимого типа, со значениями, перечисляемыми в descriptor в виде, как это принято, например, в ECMAScript-грамматике регулярных выражений, поддерживаемых стандартной библиотекой C++
|
| |
нулевой байт
|
|
pn
|
байты выравнивания полей структур данных (padding bytes) на некоторую кратную в байтах границу n=1,2,4,8
|
Регулярное выражение для проверки элемента массива T на языке C (листинг 5) имеет вид:
"^c{,n-21}p4spp4e[0, 1, 2]p4ududud"
где 21 - число байтов реализации части полей структуры, считая 1 (под символ ) + 4 (реализация real) + 4 (реализация enum ZODIAC) + 12 (реализация Birthdate); [0, 1, 2] - множество констант перечислимого типа enum ZODIAC; n - длина фрагмента анализируемого объектного кода.
Для проверки элемента массива T на языке Pascal (листинг 5) регулярное выражение имеет вид:
"^ubc{255}spe[0, 1, 2]"
Общий ход анализа статических данных с использованием регулярных выражений иллюстрирует рис. 6.

Рис. 6. Иллюстрация применения регулярных выражений для распознавания статических данных
Вполне естественно ожидать, что декомпилятор осуществляет не только анализ объектного кода, но также и проверяет допустимость спецификаций той информации, что на очередной итерации указал аналитик (п. 2). Из этого следует, что, во-первых, на n-1-ой итерации (рис. 2) представление описания данных должно по возможности минимизировать или исключать ошибки аналитика при создании спецификаций для n-ой итерации; во-вторых, декомпилятор должен осуществлять проверку этих спецификаций на приемлемость для описания конкретного фрагмента объектного кода. Именно достижению этой цели может служить предлагаемый метод, который совместно с построением описаний данных на основе анализа команд обеспечит двойную проверку адекватности описания данных на ЯВУ фрагментам статических данных в декомпилируемом модуле.
Выводы
Декомпиляция имеет две основные сферы применения: сопровождение программного обеспечения и проверка программ. Архитектура машин фон-Неймана предполагает начальное размещение команд и данных программы в оперативной памяти компьютера еще до начала исполнения программы - до начала исполнения процесса в вычислительной системе. Данные, формирующие начальный образ памяти, копируются в нее из исполняемого модуля, в котором они создаются транслятором с ЯВУ. Следовательно, декомпилируя образы данных в исполняемом модуле, т.е. производя статическую декопиляцию, появляется возможность восстановить описания этих данных на целевом языке декомпиляции. Производить декомпиляцию типов статических данных отдельно от декомпиляции команд, скорее всего, малоценно, но использовать методы декомпиляции данных (п. 3) параллельно с декопиляцией команд (п. 2) позволит анализировать один и тот же объектный код двумя независимыми методами, тем самым повышая достоверность получаемого результата.
References
1. ISO/IEC 9899:1999 (E) Programming languages – C. URL: https://www.iso.org/standard/29237.html (data obrashcheniya 01.04.2017)
2. ISO/IEC 9899:2011 (E) Programming languages – C. URL: https://www.iso.org/standard/57853.html (data obrashcheniya 01.04.2017)
3. ISO/IEC 10646:2014 Information technology – Universal Coded Character Set (UCS) URL: https://www.iso.org/standard/63182.html (data obrashcheniya 01.04.2017)
4. ISO/IEC 14882:1998 (E) Programming languages – C++ URL: https://www.iso.org/standard/25845.html (data obrashcheniya 01.04.2017)
5. ISO/IEC 14882:2003 (E) Programming languages – C++ URL: https://www.iso.org/standard/38110.html (data obrashcheniya 01.04.2017)
6. ISO/IEC 14882:2014 (E) Programming languages – C++ URL: https://www.iso.org/standard/64029.html (data obrashcheniya 01.04.2017)
7. Standard ECMA-262 ECMAScript® 2016 Language Specification URL: http://www.ecma-international.org/publications/standards/Ecma-262.htm (data obrashcheniya 01.04.2017)
8. Kholsted M.Kh. Nachala nauki o programmakh / Per. s angl.-M.: Finansy i statistika, 1981.-128 s.
9. Gusenko M.Yu., Gusenko Yu.M. Voprosy obratnoi translyatsii programmnogo obespecheniya spetsial'nogo naznacheniya // Informatsionnye tekhnologii. – M., 2002. – № 4, – S. 8–19.
|







