|
Security Issues
Reference:
Pleshakova E.S., Filimonov A.V., Osipov A.V., Gataullin S.T.
Identification of cyberbullying by neural network methods
// Security Issues.
2022. ą 3.
P. 28-38.
DOI: 10.25136/2409-7543.2022.3.38488 EDN: BEINMG URL: https://en.nbpublish.com/library_read_article.php?id=38488
Identification of cyberbullying by neural network methods
Pleshakova Ekaterina Sergeevna
ORCID: 0000-0002-8806-1478
PhD in Technical Science
Associate Professor, Department of Information Security, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th Veshnyakovsky Ave., 12k2, building 2

|
espleshakova@fa.ru
|
|
 |
Other publications by this author
|
|
Filimonov Andrei Viktorovich
PhD in Physics and Mathematics
Associate Professor, Department of Information Security, Federal State Educational Budgetary Institution of Higher Education "Financial University under the Government of the Russian Federation"
125167, Russia, g. Moscow, pr-d 4-I veshnyakovskii, 4, of. korpus 2
|
|
remueur@yandex.ru
|
|
|
Osipov Aleksei Viktorovich
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th veshnyakovsky str., 4, building 2
|
|
avosipov@fa.ru
|
|
|
Other publications by this author
|
|
|
Gataullin Sergei Timurovich
PhD in Economics
Dean of "Digital Economy and Mass Communications" Department of the Moscow Technical University of Communications and Informatics; Leading Researcher of the Department of Information Security of the Financial University under the Government of the Russian Federation
8A Aviamotornaya str., Moscow, 111024, Russia
|
|
stgataullin@fa.ru
|
|
|
Other publications by this author
|
|
|
DOI: 10.25136/2409-7543.2022.3.38488
EDN: BEINMG
Received:
20-07-2022
Published:
29-07-2022
Abstract:
The authors consider in detail the identification of cyberbullying, which is carried out by fraudsters with the illegal use of the victim's personal data. Basically, the source of this information is social networks, e-mails. The use of social networks in society is growing exponentially on a daily basis. The use of social networks, in addition to numerous advantages, also has a negative character, namely, users face numerous cyber threats. Such threats include the use of personal data for criminal purposes, cyberbullying, cybercrime, phishing and cyberbullying. In this article, we will focus on the task of identifying trolls. Identifying trolls on social networks is a difficult task because they are dynamic in nature and are collected in several billion records. One of the possible solutions to identify trolls is the use of machine learning algorithms. The main contribution of the authors to the study of the topic is the use of the method of identifying trolls in social networks, which is based on the analysis of the emotional state of network users and behavioral activity. In this article, in order to identify trolls, users are grouped together, this association is carried out by identifying a similar way of communication. The distribution of users is carried out automatically through the use of a special type of neural networks, namely self-organizing Kohonen maps. The group number is also determined automatically. To determine the characteristics of users, on the basis of which the distribution into groups takes place, the number of comments, the average length of the comment and the indicator responsible for the emotional state of the user are used.
Keywords:
artificial intelligence, cyberbullying, machine learning, kohonen map, neural networks, personal data, computer crime, cybercrimes, social network, bullying
Introduction
The influence of the mass media on the formation of national, political and religious views of the population is undeniable. Limited volumes, author's responsibility allows you to strictly control all the information material that is printed in newspapers, voiced on radio and television. In recent years, social networks have become very widespread. Now their degree of influence on the views of people is comparable to the degree of influence of television [1-3]. The conversational style of communication, the limited liability of authors and the huge number of publications do not allow the use of standard media tools and methods of control. Currently, social networks are actively used for malicious influence [4-5].
This paper deals with the problem of identifying cyberbullying in social networks. Cyberbullying is the users of social networks, forums and other discussion platforms on the Internet who escalate anger, conflict through covert or overt bullying, belittling, insulting another participant or participants in communication. Cyberbullying is expressed in the form of aggressive, mocking and offensive behavior [6-9].
Online cyberbullying causes great harm, since such users can incite conflicts based on religious hostility, ethnic hatred, etc. [10-13]. Even just the participation of cyberbullying in a discussion makes the rest of the participants nervous and wastes their time responding to such a user. It turns out that the discussion on any topic is littered with unnecessary messages. The problem of regulation of cyberbullying comments is getting bigger. One of the possible solutions is the use of machine learning to recognize cyberbullying.
Thus, the task of identifying and blocking cyberbullying is relevant.
Models and Methods
There are various methods to find cyberbullying users. The simplest and most reliable approach is manual moderation of discussions [14-15]. However, given that millions of users communicate on social networks, manual search becomes too costly. In this case, it is necessary to use methods of automated search for cyberbullying.
In 2011, a group of researchers from Canada developed an interesting method for identifying users who engaged in cyberbullying for money [1]. The method is based on the analysis of comments left by attackers and their behavior on the network. It is assumed that such users have similar behavior patterns, which makes it possible to identify them.
Table 1 lists the characteristics of user comments that were analyzed.
Table 1. List of characteristics of user comments
|
Characteristic
|
Meaning
|
|
Report ID
|
The ID of the new post, which will then be commented by users.
|
|
Sequence No.
|
Sequence number of the comment to the message.
|
|
Post Time
|
Comment posting time.
|
|
Post Location
|
The geographic location of the user who posted the comment.
|
|
User ID
|
The ID of the user who left the comment.
|
|
Content
|
Comment content.
|
|
Response Indicator
|
The reply indicator shows whether the comment is a new comment or a reply to another comment.
|
The researchers used a classification based on semantic and non-semantic analysis. The maximum detection accuracy was 88.79%. As the researchers themselves note, in earlier studies based only on the analysis of the content of messages, the accuracy did not exceed 50% [2-4].
At the same time, a significant drawback is the dependence of the proposed algorithm on easily changed indicators, such as Post Time or Post Location. Sequence No is also an unreliable parameter.
In our opinion, the most accurate way to determine whether a user is an attacker or not is only by analyzing the text of his comments and the frequency of posting.
Moreover, given the fact that attackers can write with errors, use formulaic phrases or disguise themselves as normal users, it is better to analyze not the semantic part of their comments, but the emotional component, since it is much more difficult to forge.
In addition, it should be taken into account that attackers do not just write comments, but try to manipulate other participants in the discussion, which should also manifest itself in the emotional component.
Let's try to qualitatively imagine typical models of user behavior in a social network when posting comments.
Most of the users practically do not leave comments on the message they like. Usually put "like" or "class". At best, they will write something like “super!”, “Cool”, or the like. Those. we are dealing with single comments, which are usually very short.
The next category of users writes longer comments, which, as a rule, reflect their emotional attitude to the message.
Another category of participants in the discussion is the “victims” of cyberbullying. As a rule, they try to prove something and at the same time write very detailed comments with an abundance of emotions.
And finally, cyberbullying attackers. These are people who constantly participate in the discussion, try to provoke other participants, and, therefore, cannot unsubscribe with short phrases.
To identify the emotional state of the discussion participant, we used the fact that the structure of the informational text is fundamentally different from the structure of the inspiring (manipulating) text and is characterized by the absence of intentional rhythmization of its lexical and phonetic units [16-17].
In practice, this means that some sound combinations can not only evoke certain emotions, but can also be perceived as certain images [5]. For example, in combinations, the letter “and” with an indication of the subject has the property of “reducing” the object, in front of which (or in which) it is clearly dominant. Also, the sound "o" gives the impression of softness and relaxation. The predominance of the sounds "a" and "e", as a rule, is associated with an emotional upsurge.
Based on the prerequisites listed above, we proposed the fields listed in Table 2 for analysis.
Table 2. List of fields for analysis
|
Field
|
Comment
|
Field
|
Comment
|
|
Mp
|
Mp- number of messages for p-th user
|
fó,p
|
The frequency of occurrence of the symbol "y" for the p-th user
|
|
Lp
|
Average message length for p-th user
|
fý,p
|
The frequency of occurrence of the symbol "ý" for the p-th user
|
|
fŕ,p
|
The frequency of occurrence of the symbol "a" for the p-th user
|
fţ,p
|
The frequency of occurrence of the character "ţ" for the p-th user
|
|
fĺ,p
|
The frequency of occurrence of the character "e" for the p-th user
|
f˙,p
|
The frequency of occurrence of the character "˙" for the p-th user
|
|
fč,p
|
The frequency of occurrence of the symbol "č" for the p-th user
|
f!,p
|
The frequency of occurrence of the character "!" for p-th user
|
|
fî,p
|
The frequency of occurrence of the symbol "o" for the p-th user
|
f?,p
|
The frequency of occurrence of the symbol "?" for p-th user
|
The values of these fields are calculated using the following formulas:

where p - is the user's serial number, i - is the message serial number for the p-th user, Mp - is the number of messages for the p-th user, x - is the symbol for which the calculation is made; Ni,x,p - is the number of characters x in the i-th message of the p-th user; Ni,p - is the total number of characters in the i-th message.

To train the classifier, we prepared a statistical sample of more than 1200 comments on a message on a political topic. There were 145 active participants in the discussion. In this sample, 2 intruders were manually identified.
In addition, another sample on religious topics was prepared for testing, consisting of 61 comments and 30 active participants. There were no perpetrators in this sample.
Table 3 shows an example of a training set.
Table 3. An example of a training set
|
p
|
Mp
|
Lp
|
fŕ,p
|
fĺ,p
|
fč,p
|
fî,p
|
fó,p
|
fý,p
|
f!,p
|
fţ,p
|
f˙,p
|
f?,p
|
|
1
|
1
|
44
|
0,045
|
0,136
|
0,023
|
0,045
|
0,023
|
0,000
|
0,000
|
0,000
|
0,000
|
0,000
|
|
2
|
1
|
64
|
0,109
|
0,063
|
0,078
|
0,078
|
0,031
|
0,016
|
0,000
|
0,000
|
0,000
|
0,000
|
|
3
|
1
|
246
|
0,081
|
0,069
|
0,089
|
0,057
|
0,016
|
0,000
|
0,000
|
0,000
|
0,004
|
0,000
|
|
4
|
2
|
176
|
0,057
|
0,068
|
0,054
|
0,094
|
0,034
|
0,000
|
0,006
|
0,000
|
0,014
|
0,000
|
|
5
|
7
|
392
|
0,065
|
0,070
|
0,062
|
0,077
|
0,019
|
0,003
|
0,018
|
0,005
|
0,014
|
0,033
|
|
6
|
7
|
71
|
0,085
|
0,071
|
0,049
|
0,065
|
0,028
|
0,000
|
0,000
|
0,004
|
0,028
|
0,000
|
|
7
|
33
|
188
|
0,055
|
0,061
|
0,052
|
0,068
|
0,017
|
0,002
|
0,015
|
0,004
|
0,010
|
0,004
|
|
8
|
1
|
12
|
0,083
|
0,000
|
0,083
|
0,083
|
0,083
|
0,000
|
0,000
|
0,000
|
0,000
|
0,000
|
|
9
|
1
|
54
|
0,074
|
0,111
|
0,019
|
0,019
|
0,056
|
0,000
|
0,000
|
0,000
|
0,000
|
0,000
|
|
10
|
2
|
38
|
0,133
|
0,080
|
0,013
|
0,040
|
0,027
|
0,000
|
0,000
|
0,027
|
0,027
|
0,000
|
|
11
|
1
|
61
|
0,082
|
0,033
|
0,082
|
0,066
|
0,033
|
0,016
|
0,000
|
0,000
|
0,000
|
0,000
|
|
12
|
1
|
20
|
0,100
|
0,050
|
0,050
|
0,100
|
0,000
|
0,000
|
0,000
|
0,000
|
0,000
|
0,000
|
|
13
|
1
|
102
|
0,029
|
0,078
|
0,078
|
0,088
|
0,010
|
0,000
|
0,186
|
0,000
|
0,000
|
0,000
|
|
14
|
1
|
52
|
0,096
|
0,058
|
0,019
|
0,058
|
0,019
|
0,000
|
0,058
|
0,000
|
0,000
|
0,000
|
Kohonen's self-organizing maps [3], implemented on the basis of the analytical package Deductor, were used as a classifier.
The following settings were used for training:
1. Determining the number of clusters is automatic;
2. The learning rate is 0.3 at the beginning and 0.005 at the end;
3. The learning radius at the beginning is 4, and at the end 0.1;
4. The maximum number of training epochs is 1000.
As a result of the training, the Kohonen map was obtained, shown in Figure

Picture. 1. Map of Kohonen
This figure shows the results of constructing the Kohonen map in projections on the input parameters. A total of 7 clusters were identified.
The cluster containing intruders is most clearly visible in the projection on the Mp parameter.
To test the correct operation of the neural network, we “manually” identified two typical attackers, and many participants in the discussion described these users in the same way. Both users ended up in cluster number 0 (in the figure it is marked with a dot). In the same group, there were two more users who, after additional analysis of their messages, were also characterized by us as malefactors.
There were no erroneous detections of intruders in the test sample.
As a result of the training, a table of the significance of the fields was also compiled to classify users as intruders.
Table 4. Table of significance of fields
|
Parameter
|
Significance (%)
|
Parameter
|
Significance (%)
|
|
f˙,p
|
24,7
|
f!,p
|
37,1
|
|
fč,p
|
81,0
|
fî,p
|
25,4
|
|
fĺ,p
|
39,2
|
fó,p
|
5,9
|
|
fŕ,p
|
0,0
|
f?,p
|
93,3
|
|
Lp
|
78,3
|
fý,p
|
6,3
|
|
Mp
|
100,0
|
fţ,p
|
7,2
|
This table shows that, although the number of comments is of the greatest importance, the frequency characteristics of individual characters that determine the emotional state of the user also affect the decision to classify a discussion participant as cyberbullying.
Figure 2 shows a generalized scheme of the proposed algorithm for detecting intruders.
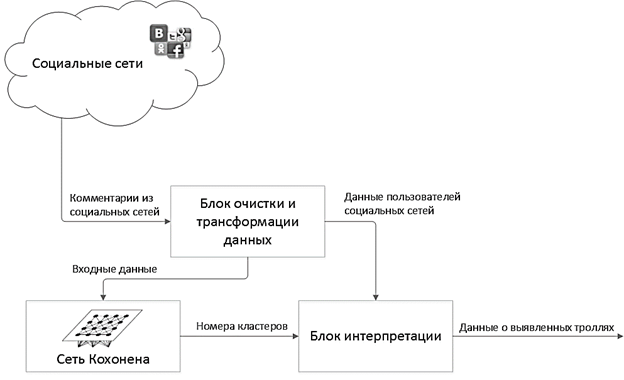
Picture. 2. Generalized scheme of the algorithm
The proposed algorithm for detecting intruders consists of the following steps:
1. All comments are selected from the selected discussion in the social network;
2. Comments enter the data cleaning and transformation block, where, according to formulas 1 and 2, they are converted to the form presented in table 3;
3. This data is passed through the Kohonen network;
4. At the output of the network, we get for each participant in the discussion the number of the cluster to which he belongs;
5. Correlating the numbers of clusters with the initial user data in the interpretation block, we get a list of intruders identified in this discussion.
The proposed algorithm has a number of advantages compared to the one described at the beginning of the article:
1. For analysis, we do not use user IDs that are easily changed;
2. We do not need to take into account the geography of the participants in the discussion;
3. The discussion can be extended indefinitely in time, but this will not affect the quality of the algorithm in any way;
4. For analysis, we use the emotional component of comments, and we identify this component not by words, as in other authors, but by the frequencies of occurrence of certain characters. This gives the algorithm stability in case of text distortion or intruder masking.
Of the shortcomings, the following should be noted:
1. The algorithm works effectively only when the discussion already contains several hundred comments;
2. The proposed method does not work if attackers write single comments from different accounts or use special software bots.
Conclusion
This article proposed a method for detecting cyberbullying in social networks, which is based on an analysis of the emotional state of network users and behavioral activity. Testing has shown the effectiveness of the proposed method. Using the proposed method for detecting cyberbullying in social networks, it is possible to process large amounts of data without using user identifiers that are easily changed. For analysis, the emotional component of comments is used, and we identify this component not by words, as in other authors, but by the frequencies of occurrence of certain characters. This gives the algorithm stability in case of text distortion or intruder masking. The results obtained are not highly accurate. Such methods will greatly facilitate the search for cyberbullying and reduce processing costs for post moderators in order to improve the quality of communication and comfortable viewing of content for users of social networks.
References
1. C. Chen, K. Wu, V. Srinivasan, X. Zhang. Battling the Internet Water Army: Detection of Hidden Paid Posters. http://arxiv.org/pdf/1111.4297v1.pdf, 18 Nov 2011
2. D. Yin, Z. Xue, L. Hong, B. Davison, A. Kontostathis, and L. Edwards. Detection of harassment on web 2.0. Proceedings of the Content analysis in the Web, 2, 2009
3. T. Kohonen. Self-organization and associative memory. 2d ed. New York, Springer Verlag, 1988
4. Y. Niu, Y. min Wang, H. Chen, M. Ma, and F. Hsu. A quantitative study of forum spamming using context-based analysis. In In Proc. Network and Distributed System Security (NDSS) Symposium, 2007
5. V.V. Kiselev. Automatic detection of emotions by speech. Educational technologies. No. 3, 2012, pp. 85-89
6. R.A. Extramarital. Trolling as a form of social aggression in virtual communities. Bulletin of the Udmurt University, 2012, Issue 1, pp. 48-51
7. S.V. Boltaeva, T.V. Matveev. Lexical rhythms in the text of suggestion. Russian word in language, text and cultural environment. Yekaterinburg, 1997, pp. 175-185
8. Gamova, A. A., Horoshiy, A. A., & Ivanenko, V. G. (2020, January). Detection of fake and provocative comments in social network using machine learning. In 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus) (pp. 309-311). IEEE.
9. Mei, B., Xiao, Y., Li, H., Cheng, X., & Sun, Y. (2017, October). Inference attacks based on neural networks in social networks. In Proceedings of the fifth ACM/IEEE Workshop on Hot Topics in Web Systems and Technologies (pp. 1-6).
10. Cable, J., & Hugh, G. (2019). Bots in the Net: Applying Machine Learning to Identify Social Media Trolls.
11. Machová K., Porezaný M., Hreškova M. Algorithms of Machine Learning in Recognition of Trolls in Online Space //2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). – IEEE, 2021. – P. 000349-000354.
12. Τσανταρλιώτης Π. Identification of troll vulnerable tergets in online social networks. – 2016.
13. Mihaylov, T., Mihaylova, T., Nakov, P., Marquez, L., Georgiev, G. D., & Koychev, I. K. (2018). The dark side of news community forums: Opinion manipulation trolls. internet research.
14. Zhukov D., Perova J. A Model for Analyzing User Moods of Self-organizing Social Network Structures Based on Graph Theory and the Use of Neural Networks //2021 3rd International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency ( SUMMA).-IEEE, 2021.-P. 319-322.
15. Alsmadi I., O'Brien M. J. How many bots in Russian troll tweets? //Information Processing & Management.-2020.-T. 57.-No. 6.-S. 102303.
16. Islam, M. M., Uddin, M. A., Islam, L., Akter, A., Sharmin, S., & Acharjee, U. K. (2020, December). Cyberbullying detection on social networks using machine learning approaches. In 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE) (pp. 1-6). IEEE.
17. Cartwright, B., Frank, R., Weir, G., & Padda, K. (2022). Detecting and responding to hostile disinformation activities on social media using machine learning and deep neural networks. Neural Computing and Applications, 1-23
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The subject of the study is an algorithm for detecting cyberbullying in social networks based on the analysis of data on the behavioral activity and emotional reactions of intruders. The research methodology is based on a combination of theoretical and empirical approaches using methods of analysis, machine learning, generalization, comparison, synthesis. The relevance of the study is determined by the widespread use of social networks, their significant impact on individual and mass consciousness in modern conditions of the population and, accordingly, the importance of studying and preventing malicious actions, including the identification of cyberbullying based on the analysis of data on behavioral activity and emotional reactions of users. The scientific novelty is associated with the algorithm proposed by the author to identify cyberbullying in social networks, which is based on the analysis of behavioral activity and emotional reactions, which will reduce the time spent on data processing by moderators, which in general will improve the quality of communication and the comfort of viewing content for users. The article is written in English literary language. The style of presentation is scientific. The structure of the manuscript includes the following sections: Introduction (the influence of mass media on the formation of public views, social networks, conversational style of communication, limited responsibility of authors, a huge number of publications, malicious influence, the problem of detecting cyberbullying in social networks, the use of machine learning to recognize cyberbullying), Models and methods (methods of searching for users exposed to cyberbullying, manual moderation, analysis of malicious comments and their behavior on the network, a list of characteristics of user comments, the emotional component of comments, the structure of informational and manipulative text, sound combinations, a list of fields for analysis, a sample of more than 1,200 comments on a political message, 145 participants, identification of 2 intruders, a sample of 61 comments on religious topics, 30 active participants, attackers were absent, an example of a training dataset, self-organizing Kohonen maps, the Deductor analytical package, training parameters, results of constructing a Kohonen map, identification of 7 clusters, checking the correctness of the neural network, manually identifying two intruders, a table of field significance, a generalized scheme of the proposed algorithm for detecting intruders, advantages and disadvantages proposed algorithm), Conclusion (conclusions), Bibliography. The section "Results and discussion" should be highlighted in the structure of the manuscript. The text includes four tables and two figures. The contents of Figure 3 should be given in English (or translated). The content generally corresponds to the title. At the same time, the title is more suitable for a scientific monograph than for a separate article. The wording of the title should specify the subject of the study, which is related to the development of a method for detecting cyberbullying in social networks based on the analysis of data on behavioral activity and emotional reactions of users. There is practically no discussion of the results, which makes it difficult to determine their scientific novelty. The bibliography includes 17 sources of domestic and foreign authors – monographs, scientific articles, materials of scientific events. Bibliographic descriptions of some sources require adjustments in accordance with GOST and editorial requirements, for example: 1. Chen C., Wu K., Srinivasan V., Zhang X.. Battling the Internet Water Army: Detection of Hidden Paid Posters (18.11.2011). URL: http://arxiv.org/pdf/1111.4297v1.pdf. 3. Kohonen T. Self-organization and associative memory. New York : Springer Verlag, 1988. ??? p. 5. Kiselyov V. V. Automatic detection of emotions by speech // Educational technologies. 2012. No.3. pp. 85-89. 12. ????????????? ?. Identification of troll vulnerable tergets in online social networks. The place of publication ??? : Publisher's name, 2016. ??? p. 17. Cartwright B., Frank R., Weir G., Padda K. Detecting and responding to hostile disinformation activities on social media using machine learning and deep neural networks // Neural Computing and Applications. 2022. Vol. ???. No. ??? P. 1-23. Appeal to opponents (V.V. Kiselyov, R. A. Extramarital, S.V. Boltayeva, T.V. Matveeva, C. Chen, K. Wu, V. Srinivasan, X. Zhang, D. Yin, Z. Xue, L. Hong, B. Davison, A. Kontostathis, L. Edwards, T. Kohonen, Y. Niu, Y. min Wang, H. Chen, M. Ma, F. Hsu, Gamova A. A., Horoshiy A. A., Ivanenko V. G., Mei B., Xiao Y., Li H., Cheng X., Sun, Y., Cable J., Hugh G., Machova K., Porezan? M., Hre?kova M., ????????????? ?., Mihaylov T., Mihaylova T., Nakov P., M?rquez L., Georgiev G. D., Koychev I. K., Zhukov D., Perova J., Alsmadi I., O'Brien M. J., Islam M. M., Uddin M. A., Islam L., Akter A., Sharmin S., Acharjee U.K., Cartwright B., Frank R., Weir G., Padda K. et al.) takes place mainly in the literature review. There is practically no discussion of the results obtained, their comparison with the data of other authors, which needs to be corrected. In general, the material is of interest to the readership, and after revision, the manuscript can be published in the journal "Security Issues".
|








