|
Litera
Reference:
Temirova D.A.
SYNTACTIC COMPRESSION IN SINGLISH SMS (BASED ON THE CORPUS NUS SMS)
// Litera.
2022. ą 6.
P. 239-246.
DOI: 10.25136/2409-8698.2022.6.38066 EDN: RMXTWU URL: https://en.nbpublish.com/library_read_article.php?id=38066
SYNTACTIC COMPRESSION IN SINGLISH SMS (BASED ON THE CORPUS NUS SMS)
Temirova Dzhannet Alibulatovna
ORCID: 0000-0003-1724-9809
Specialist for Teaching and Studies at the Department of the English Language for Natural Science Faculties, Lomonosov Moscow State University
119991, Russia, Moscow, 1 Leninskie Gory Street, bld. 13

|
djeka0890@mail.ru
|
|
 |
|
DOI: 10.25136/2409-8698.2022.6.38066
EDN: RMXTWU
Received:
14-05-2022
Published:
04-07-2022
Abstract:
Traditionally, the compression of language is considered as a result of the linguistic economy law and attracts more and more attention of linguists as the opposite of the expansion of language phenomenon. The article provides an overview of the syntactic compression in Singlish SMS. SMS of 2004 and 2012 from the National University of Singapore corpus NUS SMS were taken as the basic material for the analysis. English plays a key role in Singapore, and therefore possible changes at the syntactic language level become worthy of study due to the impact of the economy principle in conditions of a limited communication channel. The methods of corpus and statistical data analysis were used in the study. The novelty of this study lies in the fact that for the first time an attempt to analyze the methods of syntactic compression is made on the examples of Singapore English through the SMS communication. As a result, various types of syntactic compression were identified, typical for messages of 2004 (omission of superscript non-letter characters) and messages of 2012 (omission of a space), as well as compression inherent for SMS of both years from the corpus NUS SMS corpus (lack of punctuation). Such methods of syntactic compression allow the addressees to save time and electronic space in terms of technical character limitations without distorting the semantic meaning of sentences or the entire message.
Keywords:
SMS, corpus, English language, Singapore English, spoken language, language levels, language compression, syntactic compression, national identity, absence of elements
This article is automatically translated.
Language compression, being the result of the law of linguistic economy, has been the subject of many scientific studies since the middle of the XX century (A.A. Malchenko, A.I. Kiselevsky, R.A. Budagov, V. P. Kobkov, etc.) and currently, due to its disparate understanding among linguists, continues to attract increasing attention. In a broad sense, compression is recognized as a determining factor in the functioning of the language, implemented in functional styles in varying degrees of intensity. Compression or compression opposes another trend in the form of language expansion, which in the work of the authoritative linguist R.A. Budagov, devoted to the multidimensional study of the "principle of economy", is understood as linguistic differentiation [1, p. 19]. Compression in the narrow sense is the functioning of various linguistic means that contribute to its implementation at all levels of the language. E.A. Shaglanova classifies the following types of compression: "1) at the phonetic level — assimilation, adaptation (accommodation), reduction, loss, fusion and intonation means (timbre, tempo, tone movement), etc.; 2) at the lexical level — omission, combination, substitution, use of abbreviations, abbreviations, borrowings, translation into another sign system; 3) at the syntactic level — ellipsis, incomplete sentences, non-union, nominalization, etc." [5, URL: https://science-education.ru/ru/article/view?id=9931]. The article by M.V. Umerova, devoted to the study of the types and levels of implementation of language compression, presents a wider range of the functioning of compression, which: — at the phonetic level, it manifests itself "in violation of the phonetic norm" [4, p. 2]; — at the morphological level, it is implemented through the use of "special morphemes when creating truncated colloquial forms of words and utterances" [Ibid.]; — at the lexical level, "it is marked by the use of short, often single-morphemic words, words of broad semantics, interjections, pronouns, etc." [Ibid., p. 4]; — at the level of word formation "is associated with such phenomena as abbreviation, universalization, word composition, telescoping, fusion, truncation, substantiation" [Ibid., p. 5]; — at the syntactic level, "provides for the compression of the sign structure by ellipsis, grammatical incompleteness, non-union" [Ibid., p. 6]. In the same work, one can find a clearly formulated definition of language compression, covering all aspects that determine speech action, compared with other formulations that have so far remained vague and incomplete: "Language compression is traditionally considered as simplification due to the law of speech economy, the requirements of the genre, the peculiarities of the information carrier in the process of processing or generating the text of its surface structure - by increasing the informativeness of language units and eliminating those elements that can be restored from the nonverbal part of the text, without changing its informational side compared to the original text or a neutral stylistic norm. [Ibid., p. 5]. In modern linguistics, there are a number of works devoted to the study of language compression, in particular in SMS messages, at various levels of language, among which, according to the volume of the study, the following stand out: — analysis of 1000 messages in German, conducted by N. Doring, as a result of which various types of acronyms and abbreviations were identified [7]; — research by I. Hard af Segerstad based on 1152 messages in Swedish. According to I. Hard af Segerstad, text messages differ in the specifics of writing words, with missing vowel letters and consisting only of consonants, and are also characterized by excessive omission of spaces [9]; — analysis of 8000 messages in Finnish, conducted by researchers E.-L. Kasesniemi and P. Rutyanen [10], noting the absence of traditional grammar or punctuation in text messages, where words are shortened or joined together, and inflectional endings are omitted. Within the framework of this study, syntactic compression, implemented in short text messages (SMS) in the Singaporean version of the English language, is interesting to study in connection with the role that the English language plays in Singapore, as well as transformations at the syntactic level in youth communication.
English in Singapore serves as a lingua franca, providing interethnic communication of the ethnolinguistic diversity of the country: the population of Singapore is divided into four ethnic groups (Chinese, Malays, Indians and "others"). On the territory of Singapore, there is a diglossia, which manifests itself in the functioning of the standard Singaporean version of English (Standard Singapore English – close to the British version) and the spoken Singaporean version of English (Colloquial Singapore English – Singlish, functioning in the speech of young people, marked by inclusions from native languages). In the conducted by J. Leimgruber's study on the Singapore version of English found that its grammar corresponds to the Colloquial Singapore English (Singlish): “It is of course the grammar of CSE that is of more central concern here, as it differsfromitsstandardquitemarkedly. It is also relatively localised, in that this combination of features is restricted to CSE. …, but in their combination, these and other features form the unique grammar of CSE” — The singlish grammar is most interesting here, as it differs significantly from the standard version. It is also relatively limited, since in such a combination of functions, it boils down to a singlishness. ..., but the combination of these and other features form a unique Singlish grammar (hereafter our translation. — J. T.) [12, p. 51]. Moreover, as L. Lim and other researchers note [13, pp. 72-73], Singaporeans, as a rule, do not identify themselves with the English language and insist on using their specific language, which is a mixture of English speech with inclusions from native languages: "Language is something that no one has a monopoly on. <...> Let's not get hung up on the English spoken by our youth. And let's not experience an inferiority complex — our English is not so bad" [8, p. 77]; "Language reflects identity. <...> The beauty of singlish is that it is so concise. Its ability to convey meaning so economically makes it too practical a tool for eradication" [Ibid., p. 78]; "I love Singlish so much that I speak it at every opportunity. <...> It is a language that defines our identity and connects us with our community. Speaking Singlish is a means of survival here, a way to communicate effectively with the people around you" [Ibid.]. The material for this analysis was 2000 SMS messages from the NUS SMS corpus developed by linguists of the National University of Singapore Tao Chen and Min-Yen Kang. The case contains collections of SMS messages in English and Chinese received from teenagers aged 18 to 25 years. As of September 2014, the corpus consisted of 55,835 SMS in English and 31,205 Chinese SMS [15, URL: https://scholarbank.nus.edu.sg/handle/10635/137343] (figure 1). 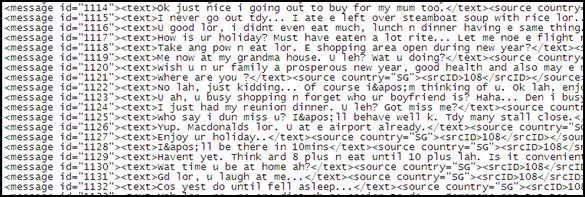
Figure 1. Format for saving SMS messages in the case of NUS SMS 2004 and 2012 .
Based on the parameters of saving SMS messages in the corpus of NUS SMS, which, in addition to texts, contain metadata (message serial number, collection method, year of dispatch, sender's digital code, phone model, sender's user number, age, gender, language proficiency, city, service experience, frequency of sending messages and method input) [6, URL: https://scholarbank.nus.edu.sg/handle/10635/137343], during the analysis, it was decided to separate the main text of SMS messages from additional information. Based on a text editor and source code for use with Microsoft Windows, Notepad++ [14, URL: https://notepad-plus-plus.org /] we removed additional information about respondents and their mobile devices that could interfere with the statistical analysis of messages, which could lead to erroneous indicators as a result. Next, for statistical analysis, we turned to the AntConc program developed by Lawrence Anthony, a professor at the Faculty of Natural Sciences and Engineering at Waseda University in Japan. This software is a "free multiplatform tool for conducting corpus linguistic research, implementing corpus methods and learning a language based on data" [11, URL: https://www.laurenceanthony.net/software]. So, with the help of the AntConc program, we identified the most frequent cases of syntactic compression. Of course, syntactic compression, which involves the compression of the sign structure in such ways as text division, ellipsis and omission, takes place in SMS communication, reflecting the features of colloquial speech, which, however, have already been studied by the author in previous studies [2, pp. 191-194; 3, pp. 685-687]. Focusing on the words of linguist I. Hard af Segerstad that "syntactic compression in text messages can be implemented by omitting punctuation marks, non-traditional punctuation, omitting spaces between words and other ways" [9, pp. 218-219], the subject of this work is the implementation of the law of linguistic economy at the syntactic level in such manifestations as the absence of an apostrophe, the omission of a space between words and punctuation features in SMS messages. Thus, the absence of an apostrophe is observed in SMS messages of 2004, which leads to the combination of two words or parts of them into one structure in order to save time on keystrokes, which may be important when the message size has technical limitations. Note that the strategy of omitting the apostrophe in the messages of the NUS SMS corpus is mainly (in 671 messages) used in negative constructions: Haha... dont be angry with yourself... Take it as a practice for the real thing. =) () Huh but i cant go 2 ur house empty handed right? () My supervisor find 4 me one lor i thk his students. I havent ask her yet. Tell u aft i ask her. () Such syntactic compression can be explained by the absence of ambiguity in constructions of this type, since omitting an apostrophe does not lead to a misunderstanding of the word or the entire message. Another type of language compression at the syntactic level in the messages of the NUS SMS corpus is the omission of a space between words, which is observed in the messages of 2012 (Fig. 2). Dar dar,, thanks for coming down and talking to me and accompanyingme today! Next time we go eat botak Jones k? :* love you!! Reach homealready? () I was also a little late but she seemed to be only showing a videobefore that.. () 
Figure 2. Sample of missing a space between words in the messages of the NUS SMS corps 2012 The strategy of skipping the space, due to the principle of brevity and speed of typing, similar to the strategies of skipping punctuation marks and superscript non-letter characters (apostrophe), allows the sender to save time and effort spent on keystrokes.
Note that in the messages of the NUS SMS corpus of 2004 and 2012, punctuation rules are violated, since they lack punctuation marks (commas and dots), which causes the problem of determining the beginning-end of a sentence from the point of view of syntax.: Orh chey is they upload next week I tot ask us upload next week -.- () Oh cos I creating a group for our sat group next time communicate usewhatsapp easier lol... nvm I try again later () The absence of punctuation marks in the messages of the NUS SMS corpus creates a situation where two words are at the intersection of the end of one sentence and the beginning of another (in 174 messages): Lol sia.baaaaa then I stay in xinrou house hibernate.outside wet wet not gd for shopping.haha. () Hmmmmm.nvm I find find later.haha.all reach le ah? () In the messages of the NUS SMS corpus, multi-frequency (in 1372 messages) is the use of ellipsis, which, as is known, expresses the understatement or raggedness of speech and allows senders to transmit only important information in the message, making it clear to the addressee that the other part of it remains for discussion offline. The pragmatic meaning of the ellipsis in the messages of the NUS SMS corpus is to express a pause, the beginning or the end of a phrase, and also acts as a "space": No wonder... Cos i dun rem seeing a silver car... But i thk i saw a black one... () Wah lucky man... Then can save money... Hee... () Really... I tot ur paper ended long ago... But wat u copied jus now got use? U happy lar... I still haf 2 study :-( () Thus, as a result of the conducted research, it can be concluded that syntactic compression in the messages of the NUS SMS corpus is the omission of the least significant secondary elements in semantic, structural and communicative relations, the omission of which does not cause misunderstanding of the entire sentence or a short text message. The law of linguistic economy or compression at the syntactic language level in such manifestations as the omission of apostrophes and spaces between words allows users to save time on keystrokes and save space under technical constraints for other more important elements of electronic communication. Thus, it can be concluded that compression as a whole is an effective way to remove unnecessary parts while preserving their value.
References
1. Budagov R.A. Does the principle of economy determine the development and functioning of language?// Questions of Linguistics. No. 1.-1972., pp.17-36.
2. Temirova D. A. Functioning of elliptical constructions in English SMS messages. Philological sciences. Questions of theory and practice. Tambov: Diploma, 2015. No. 12(54): in 4 hours. IV. pp. 191-194.
3. Temirova D. A. The specifics of SMS messages in the Singapore version of the English language. Collection of the International interdisciplinary scientific and practical conference "Language. Culture. Translation. Communication", 2015. pp.685-687.
4. Umerova M.V. Language compression: types and levels of implementation. – M.: National Research University. HSE. – 2001.
5. Shaglanova E.A. STRATEGIES AND TACTICS OF TEXT COMPRESSION IN TV ADVERTISING // Modern problems of science and education. – 2013. – ą 4. URL: https://science-education.ru/ru/article/view?id=9931 (accessed: 04.05.2022).
6. Chen T., Kan M.-Y. Creating a Live, Public Short Message Service Corpus: The NUS SMS Corpus URL: https://scholarbank.nus.edu.sg/handle/10635/137343 (accessed 20.02.2022).
7. Doring, N. 2002. "1 bread, sausage, 5 bags of apples I.L.Y"-communicative functions of text messages (SMS)‘ Zeitschrift für Medienpsychologie 3, 14(3). pp. 118-128.
8. Harada, Sh. The Roles of Singapore Standard English and Singlish. Information and Communication Studies 40. 69-81, 2009. Print. Joo, Mary Tay Wan.
9. Hard af Segerstag, Y. 2002. Use and Adaptation of the Written Language to the Conditions of Computer-Mediated Communication‘, PhD thesis, University of Goteborg.
10. Kasesniemi, E.-L., P. Rautiainen (2002) ‗Mobile culture of children and teenagers in Finland‘ in Katz, J. and M. Aakhus (eds), pp. 10-192.
11. Laurence A. AntConc (Version 3.5. 9) [Computer Software]. Tokyo, Japan: Waseda University. URL: https://www.laurenceanthony.net/software (accessed 20.02.2022).
12. Leimgruber J. Singapore English. Language and Linguistics Compass 5.1 (2011), pp. 47–62.
13. Lim L., Pakir A., Wee L. English in Singapore: Policies and prospects published in English in Singapore: Modernity and Management. Hong Kong University Press 2010. – 305p.
14. Source Code Editor Notepad++. URL: https://notepad-plus-plus.org/ (accessed: 20.02.2022).
15. The National University of Singapore SMS Corpus. URL: https://scholarbank.nus.edu.sg/handle/10635/137343 (accessed 20.02.2022).
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The article "Syntactic compression in SMS messages in the Singaporean version of English (based on the material of the NUS SMS corpus)" submitted for publication in the journal "Litera" is undoubtedly relevant, since language compression, being the result of the law of linguistic economy, has been the subject of many scientific studies since the middle of the XX century and currently, due to the disparate understanding of it among linguists, it continues to attract more and more attention. Within the framework of this study, syntactic compression, which is implemented in short text messages (SMS) in the Singaporean version of the English language, is interesting to study in connection with the role that the English language plays in Singapore, as well as transformations at the syntactic level in youth communication. Given the prevalence of English in the world as a language of interethnic communication, local features acquired by the language under the influence of the national language of the country are interesting. So in Singapore, English performs the function of a lingua franca, providing interethnic communication of the ethnolinguistic diversity of the country, having two options: the standard Singaporean version of English and the spoken Singaporean version of English (Singlish), functioning in the speech of young people, marked by inclusions from their native languages. The practical material of the study was 2000 SMS messages from the NUS SMS corpus, developed by linguists at the National University of Singapore Tao Chen and Min-Yen Kang. The research methodology is quite adequate to the goals and objectives of the study. The research was carried out in line with modern scientific approaches, the work consists of an introduction containing the formulation of the problem, the main part, traditionally beginning with a review of theoretical sources and scientific directions, a research and final one, which presents the conclusions obtained by the author. Structurally, the article consists of several semantic parts, namely: introduction, literature review, methodology, research progress, conclusions. I would like to note the great and scrupulous work of the author in the analysis of theoretical sources and the thorough interpretation of practical material. We emphasize that in the study the author considers both the theoretical basis of the problem field concerned and the practical problems. The bibliography of the article contains 15 sources, including both domestic and foreign works. The disadvantages of the bibliographic list include the lack of references to fundamental works, which include PhD and doctoral dissertations on the subject under consideration. A greater number of references to authoritative works, such as monographs, doctoral and/or PhD dissertations on related topics, which could strengthen the theoretical component of the work in line with the national scientific school. In general, it should be noted that the article was written in a simple, understandable language for the reader, typos, spelling and syntactic errors, inaccuracies were not found. The article will undoubtedly be useful to a wide range of people, philologists, undergraduates and graduate students of specialized universities. The overall impression after reading the reviewed article is positive, it can be recommended for publication in a scientific journal from the list of the Higher Attestation Commission.
|








