|
Software systems and computational methods
Reference:
Naikhanova L.V., Naikhanov N.V.
Calculating the measures of semantic connectivity based on wiki projects
// Software systems and computational methods.
2018. ą 3.
P. 71-80.
DOI: 10.7256/2454-0714.2018.3.26473 URL: https://en.nbpublish.com/library_read_article.php?id=26473
Calculating the measures of semantic connectivity based on wiki projects
Naikhanova Larisa Vladimirovna
Doctor of Technical Science
Professor, Department of Informatics Systems, East-Siberian State University of Technology and Management
670013, Russia, respublika Buryatiya, g. Ulan-Ude, ul. Klyuchevskaya, 40V

|
obeka_nlv@mail.ru
|
|
 |
Other publications by this author
|
|
|
Naikhanov Nikolai Vladimirovich
graduate student, Department of Informatics Systems of the East-Siberian State University of Technology and Management
670013, Russia, Buryatiya, g. Ulan-Ude, ul. Klyuchevskaya, 40V
|
|
naikhan2021@gmail.com
|
|
|
Other publications by this author
|
|
|
DOI: 10.7256/2454-0714.2018.3.26473
Received:
31-05-2018
Published:
11-10-2018
Abstract:
The object of study of this work is a measure of semantic connectivity of texts, the subject of study is an algorithm for calculating the measure of semantic connectivity of texts. The article focuses on the method for determining the hybrid measure of the semantic connectivity of two concepts. This method underlies the algorithm for computing the similarity of two texts. Wiki projects (Wikipedia and Wiktionary) are used as sources of knowledge. Sharing them allows covering a much larger number of words as compared to using one of the wiki projects. The method uses the well-known Wikisim measure. This measure is simple, but has good performance. In the classic Wikisim method, only Wikipedia is used, so it is adapted for Wiktionary. The methodology of the work is based on modeling the process of extracting high-quality knowledge from Wiki projects - the individual work of independent volunteers. The novelty of the research lies in combining the two sources of knowledge of Wikipedia and Wiktionary and creating on their basis a new hybrid measure of semantic relatedness of concepts. The main conclusion of the work is that the combination of formal (Wiktionary) and informal (Wikipedia) sources of knowledge can lead to a better assessment of semantic connectivity between text units. The described method can be applied in economics, sociology and politics to clarify people's opinions on issues of interest.
Keywords:
semantic relatedness, relatedness hybrid, knowledge source, WikiProject, Wikipedia, Wiktionary, text, word, concept, frequency response
Âű÷čńëĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč íŕ îńíîâĺ âčęč ďđîĺęňîâ
Ââĺäĺíčĺ
Ńĺěŕíňč÷ĺńęčĺ ěĺđű čńďîëüçóţňń˙ â ęŕ÷ĺńňâĺ îńíîâíűő ęîěďîíĺíňîâ â áîëüřîě ęîëč÷ĺńňâĺ ďđčëîćĺíčé, ęîňîđűĺ î÷ĺíü ńčëüíî çŕâčń˙ň îň îöĺíîę ńĺěŕíňč÷ĺńęčő ŕńńîöčŕöčé. Ńôĺđŕ ďđčěĺíĺíč˙ ńĺěŕíňč÷ĺńęčő ěĺđ ěíîăîďđîôčëüíŕ, íŕ÷číŕ˙ îň ęîěďüţňĺđíîé ëčíăâčńňčęč äî čńęóńńňâĺííîăî číňĺëëĺęňŕ č îň ęîăíčňčâíîé ďńčőîëîăčč äî âîńńňŕíîâëĺíč˙ číôîđěŕöčč.
 îáëŕńňč îáđŕáîňęč ĺńňĺńňâĺííî-˙çűęîâîé číôîđěŕöčč áîëĺĺ řčđîęî đŕńďđîńňđŕíĺí ňĺđěčí «ńĺěŕíňč÷ĺńęŕ˙ áëčçîńňü», ÷ĺě «ńĺěŕíňč÷ĺńęŕ˙ ńâ˙çíîńňü». Ńĺěŕíňč÷ĺńęŕ˙ áëčçîńňü ńîńňîčň čç ńĺěŕíňč÷ĺńęčő ńâ˙çĺé ěĺćäó äâóě˙ ňĺđěčíŕěč, ęîňîđűĺ čěĺţň ŕíŕëîăč÷íóţ ďđčđîäó, ńîńňŕâ č ŕňđčáóňű. Ďđčěĺđŕěč ńĺěŕíňč÷ĺńęîé áëčçîńňč ˙âë˙ţňń˙ îňíîřĺíč˙ ńčíîíčěčč, ăčďĺđîíčěčč č ăčďîíčěčč.  đŕáîňĺ [6] ńĺěŕíňč÷ĺńęŕ˙ áëčçîńňü îďđĺäĺëĺíŕ ęŕę ňŕęńîíîěč÷ĺńęŕ˙ áëčçîńňü äâóő ńëîâ. Ńĺěŕíňč÷ĺńęŕ˙ ńâ˙çíîńňü ňĺńíî ńâ˙çŕíŕ ń ńĺěŕíňč÷ĺńęîé áëčçîńňüţ, íî ˙âë˙ĺňń˙ áîëĺĺ îáůčě ňĺđěčíîě, âęëţ÷ŕ˙ ěíîćĺńňâî ęëŕńńč÷ĺńęčő č íĺęëŕńńč÷ĺńęčő îňíîřĺíčé [5]. Îíŕ îőâŕňűâŕĺň íĺ ňîëüęî ńĺěŕíňč÷ĺńęóţ áëčçîńňü, íî ňŕęćĺ ęîíöĺďňű, íĺ čěĺţůčĺ ˙âíóţ ńőîćóţ ďđčđîäó, ńîńňŕâ č ŕňđčáóňű, íî ňĺńíî ńâ˙çŕííűĺ.
Ěíîćĺńňâî ďđčëîćĺíčé čńęóńńňâĺííîăî číňĺëëĺęňŕ, ďî ńóňč, îńíîâŕíű íŕ ěĺđŕő ńĺěŕíňč÷ĺńęčő ŕńńîöčŕöčé. Äîáű÷ŕ ěíĺíč˙, ňŕęćĺ čçâĺńňíŕ ęŕę ŕíŕëčç íŕńňđîĺíčé, ˙âë˙ĺňń˙ çŕäŕ÷ĺé ŕâňîěŕňč÷ĺńęîăî îďđĺäĺëĺíč˙ îňíîřĺíč˙ (ěíĺíč˙, îöĺíęč, ýěîöčé) ëţäĺé â îňíîřĺíčč îáúĺęňîâ č čő ŕňđčáóňîâ [7]. Ńňđĺěčňĺëüíűé đîńň ńîöčŕëüíűő ěĺäčŕ âűçűâŕţň áîëüřîé číňĺđĺń ę ďđčëîćĺíč˙ě, âűďîëí˙ţůčě ŕíŕëčç áëîăîńôĺđű. Áëîă-ďîńňŕě őŕđŕęňĺđíű ňĺęńňű íĺáîëüřîăî îáúĺěŕ. Ďîýňîěó ńňŕíäŕđňíűĺ ěĺňîäű îďđĺäĺëĺíč˙ ńĺěŕíňč÷ĺńęîé ŕńńîöčŕöčč ňĺęńňîâ áëîă-ďîńňîâ íĺ ńîâńĺě ďîäőîä˙ň, ň.ę. ňŕęčě ňĺęńňŕě ńâîéńňâĺííű íĺńňđîăčĺ ăđŕěěŕňč÷ĺńęčĺ ńňđóęňóđű.
Äŕííŕ˙ đŕáîňŕ ďîńâ˙ůĺíŕ ěĺňîäó îďđĺäĺëĺíč˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ňĺęńňîâ íŕ îńíîâĺ âčęč ďđîĺęňîâ, ďîçâîë˙ţůĺěó ýôôĺęňčâíî îďđĺäĺë˙ňü ěĺđó ńőîäńňâŕ äâóő ňĺęńňîâ íĺáîëüřîăî îáúĺěŕ. Ďđĺäëŕăŕĺěűé ěĺňîä îńíîâŕí íŕ ěĺňîäĺ Wikisim [3]. Ýňîň ěĺňîä čńďîëüçóĺň â ęŕ÷ĺńňâĺ čńňî÷íčęŕ çíŕíčé "Âčęčďĺäčţ".  đŕáîňĺ ďđĺäëŕăŕĺňń˙ äîáŕâčňü íîâűé čńňî÷íčę çíŕíčé "Âčęčńëîâŕđü".
Îáîńíîâŕíčĺ âűáîđŕ čńňî÷íčęîâ çíŕíčé
Âčęčďĺäč˙ ˙âë˙ĺňń˙ ńîâěĺńňíî ďîńňđîĺííîé, ěíîăî˙çű÷íîé č ńâîáîäíî äîńňóďíîé îíëŕéí-ýíöčęëîďĺäčĺé [1, 2]. Âčęčďĺäč˙ čěĺĺň ďđĺčěóůĺńňâŕ ďî ńđŕâíĺíčţ ń äđóăčěč čńňî÷íčęŕěč çíŕíčé, ňŕęčěč ęŕę WordNet č Wiktionary. Íŕčáîëĺĺ âŕćíűě čç âńĺő ˙âë˙ĺňń˙ ĺĺ ďđĺâîńőîäíîĺ îńâĺůĺíčĺ ęîíöĺďňîâ, îńîáĺííî čěĺí ńîáńňâĺííűő.  íĺé îďčńŕíî îăđîěíîĺ ęîëč÷ĺńňâî çíŕíčé, ńâ˙çŕííűő ń ęîíęđĺňíîé ďđĺäěĺňíîé îáëŕńňüţ, ÷ňî äĺëŕĺň ĺ¸ ďđčâëĺęŕňĺëüíűě đĺńóđńîě.  đŕáîňĺ [9] áűëî ďđîâĺäĺíî čńńëĺäîâŕíčĺ ń öĺëüţ čçó÷ĺíč˙ îőâŕňŕ Âčęčďĺäčč â îáëŕńňč ďđîäîâîëüńňâč˙ č ńĺëüńęîăî őîç˙éńňâŕ. Îíč ďîęŕçŕëč, ÷ňî Âčęčďĺäč˙ îáĺńďĺ÷čâŕĺň őîđîřčé îőâŕň ńĺëüńęîőîç˙éńňâĺííűő ňĺě, ďđčáëčćŕţůčéń˙ ę îőâŕňó ďđîôĺńńčîíŕëüíîăî ňĺçŕóđóńŕ.
 ďđîňčâîďîëîćíîńňü ýňîěó, îőâŕň WordNet îăđŕíč÷ĺí č ďî÷ňč íĺ ďîęđűâŕĺň ęîíęđĺňíóţ ďđĺäěĺňíóţ îáëŕńňü č îáëŕäŕĺň ńęóäíűě îőâŕňîě čěĺí ńîáńňâĺííűő [10]. Âčęčńëîâŕ́đü (ŕíăë. Wiktionary) – ńâîáîäíî ďîďîëí˙ĺěűé ěíîăîôóíęöčîíŕëüíűé ěíîăî˙çű÷íűé ńëîâŕđü č ňĺçŕóđóń. Ńëîâŕđü Wiktionary ˙âë˙ĺňń˙ ńîâěĺńňíî ďîńňđîĺííűě č äîńňóďíűě îíëŕéí ńëîâŕđĺě. Ýňî ěíîăî˙çű÷íűé, č ńîńňî˙ůčé ďđčěĺđíî čç 3,5 ěëí çŕďčńĺé. Ďî ńđŕâíĺíčţ ńî ńňŕíäŕđňíűě ńëîâŕđĺě, ňŕęčě ęŕę Oxford English Dictionary, Wiktionary ďđĺäëŕăŕĺň řčđîęčé ńďĺęňđ ńĺěŕíňč÷ĺńęčő č ëĺęńč÷ĺńęčő îňíîřĺíčé, ńëĺäîâŕňĺëüíî, ĺăî ěîćíî íŕçâŕňü ňĺçŕóđóńîě [11].
Wiktionary čěĺĺň ěíîăî îáůčő ÷ĺđň ń WordNet. Äë˙ ęŕćäîăî ńëîâŕ îí čěĺĺň ńňđŕíčöó ńňŕňüč, â ęîňîđîé ďĺđĺ÷čńë˙ţňń˙ đŕçëč÷íűĺ ęëŕńńű ńëîâ. Ęŕćäűé ęëŕńń ńëîâŕ ńîîňâĺňńňâóĺň ęîíöĺďňó. Ńëĺäó˙ WordNet, Wiktionary ňŕęćĺ îďđĺäĺë˙ĺň ëĺęńč÷ĺńęčĺ, ńĺěŕíňč÷ĺńęčĺ îňíîřĺíč˙, ňŕęčĺ ęŕę ÷ŕńňč đĺ÷č, ďđîčçíîřĺíčĺ, ńčíîíčěű, ăčďĺđîíčěű, ăčďîíčěű, ďĺđĺâîä íŕ äđóăčĺ ˙çűęč.
Ďđč čçó÷ĺíčč đŕáîň ďî äŕííîé ňĺěĺ, áűëî âű˙ńíĺíî, ÷ňî ěĺňîäű, îńíîâŕííűĺ čńďîëüçîâŕíčč Âčęčďĺäčč, őîđîřî âű÷čńë˙ţň ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč â ďđĺäěĺňíűő îáëŕńň˙ő č čěĺí ńîáńňâĺííűő. Íî áűëî ňŕęćĺ óńňŕíîâëĺíî, ÷ňî Âčęčďĺäčţ íĺâîçěîćíî ďđčěĺíčňü äë˙ ŕíŕëčçŕ ńâ˙çíîńňč ăëŕăîëîâ, ďđčëŕăŕňĺëüíűő č îńňŕëüíűő ÷ŕńňĺé đĺ÷č, ęđîěĺ ńóůĺńňâčňĺëüíűő, â ńâ˙çč ń ňĺě, ÷ňî Âčęčďĺäč˙ äĺëŕĺň ŕęöĺíň íŕ ýíöčęëîďĺäč÷ĺńęčĺ ňĺđěčíű [4].
 ýňčő ńëó÷ŕ˙ő óäîáíî ďđčěĺí˙ňü Âčęčńëîâŕđü, â ęîňîđîě ěű ěîćĺě óńňŕíîâčňü ˙âíűĺ ěîđôîëîăč÷ĺńęčĺ, ńčíňŕęńč÷ĺńęčĺ č ńĺěŕíňč÷ĺńęčĺ ńâîéńňâŕ. Íî â íĺě îňńóňńňâóţň ňĺđěčíű ďđĺäěĺňíűő îáëŕńňĺé č čěĺí ńîáńňâĺííűő.
Ďëţńű îäíîăî âčęč ďđîĺęňŕ âçŕčěíî ďîęđűâŕţň ěčíóńű äđóăîăî, ÷ňî ăîâîđčň îá ýôôĺęňčâíîńňč ěĺđű, áŕçčđóţůĺéń˙ íŕ äâóő čńňî÷íčęîâ çíŕíčé. Čěĺííî ýňîň ôŕęň ďđčâĺë ę đĺřĺíčţ ńîçäŕíč˙ ăčáđčäíîé ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ.
Ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ
Ěĺđŕ îńíîâŕíŕ íŕ ęîěáčíčđîâŕíčč ŕńďĺęňîâ ďđîĺęňîâ Âčęčďĺäčč č Âčęčńëîâŕđ˙, ęŕę čńňî÷íčęîâ çíŕíčé. Ńóůĺńňâóţůčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč čńďîëüçóţň îńíîâíóţ ńňđóęňóđó Âčęčďĺäčč ęŕę íĺôîđěŕëüíîăî čńňî÷íčęŕ çíŕíčé äë˙ âű÷čńëĺíč˙ ńĺěŕíňč÷ĺńęčő ŕńńîöčŕöčé, ŕ čěĺííî ńĺňü ăčďĺđńńűëîę. Ăčďĺđńńűëęč Âčęčďĺäčč ˙âë˙ţňń˙ ńâ˙çüţ ěĺćäó äâóě˙ ńňŕňü˙ěč, đŕçäĺë˙ţůčěč íĺęîňîđűé ęîíňĺęńň. Ńňŕňüč, čěĺţůčĺ ńńűëęč íŕ ęîíęđĺňíóţ ńňŕňüţ íŕçűâŕţňń˙ ńňŕňü˙ěč in-links. Ŕíŕëîăč÷íűě îáđŕçîě, ńňŕňüč, ęîňîđűĺ óďîěčíŕţňń˙ â ŕíŕëčçčđóĺěîé ńňŕňüĺ íŕçűâŕţňń˙ ńňŕňü˙ěč out-links.
Îďčńűâŕĺěŕ˙ ěĺđŕ îńíîâŕíŕ íŕ ěĺňîäĺ WikiSim, ęîňîđűé ďîęŕçűâŕĺň ëó÷řčĺ đĺçóëüňŕňű ďî ńđŕâíĺíčţ ń äđóăčěč čçâĺńňíűěč ěĺňîäŕěč [4]. WikiSim ó÷čňűâŕĺň äîëţ îáůčő ńńűëîę äâóő ńňŕňĺé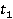 č č 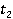 , äâóő ŕíŕëčçčđóĺěűő ęîíöĺďňîâ , äâóő ŕíŕëčçčđóĺěűő ęîíöĺďňîâ 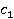 č č 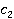 . .
Ďîäőîä íŕ÷číŕĺňń˙ ń ńîăëŕńîâŕíč˙ âőîäíűő ďîí˙ňčé č ę čő ńîîňâĺňńňâóţůčě ńňŕňü˙ě Âčęčďĺäčč 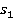 č č 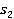 ńîîňâĺňńňâĺííî. ńîîňâĺňńňâĺííî.
Óńňŕíîâëĺííîĺ äë˙ , ěíîćĺńňâî ńńűëîę (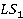 ), ńîńňî˙ůĺĺ čç ĺĺ îňäĺëüíűő ńňŕňĺé in-link č out-link, ńđŕâíčâŕĺňń˙ ń ěíîćĺńňâîě ńńűëîę ( ), ńîńňî˙ůĺĺ čç ĺĺ îňäĺëüíűő ńňŕňĺé in-link č out-link, ńđŕâíčâŕĺňń˙ ń ěíîćĺńňâîě ńńűëîę (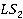 ) ńňŕňüč .  đĺçóëüňŕňĺ ńđŕâíĺíč˙ îďđĺäĺë˙ĺňń˙ ěíîćĺńňâî ńîâďŕâřčő ńńűëîę. Çŕňĺě ěíîćĺńňâî ńîâďŕâřčő ńńűëîę čńďîëüçóĺňń˙ äë˙ âű÷čńëĺíč˙ ěĺđű ńâ˙çíîńňč. ) ńňŕňüč .  đĺçóëüňŕňĺ ńđŕâíĺíč˙ îďđĺäĺë˙ĺňń˙ ěíîćĺńňâî ńîâďŕâřčő ńńűëîę. Çŕňĺě ěíîćĺńňâî ńîâďŕâřčő ńńűëîę čńďîëüçóĺňń˙ äë˙ âű÷čńëĺíč˙ ěĺđű ńâ˙çíîńňč.
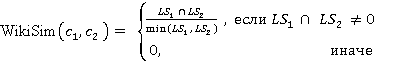 (1) (1)
 đŕáîňĺ ďđĺäëîćĺí ńëĺäóţůčé ŕëăîđčňě âű÷čńëĺíč˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ:
1) íŕőîćäĺíčĺ ÷ŕńňîňíűő őŕđŕęňĺđčńňčę;
2) íŕőîćäĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ęîíöĺďňîâ:
- âű÷čńëĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ęîíöĺďňîâ ń čńďîëüçîâŕíčĺě ěĺňîäŕ WikiSim č čńňî÷íčęŕ çíŕíčé Wikipedia, óńëîâíî îáîçíŕ÷čě ĺăî ęŕę «WikiSim on Wikipedia»;
- âű÷čńëĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ęîíöĺďňîâ ń čńďîëüçîâŕíčĺě ěĺňîäŕ WikiSim č čńňî÷íčęŕ çíŕíčé Wiktionary, óńëîâíî îáîçíŕ÷čě ĺăî ęŕę «WikiSim on Wiktionary»;
- âű÷čńëĺíčĺ ăčáđčäíîé ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ęîíöĺďňîâ (hybrid measure).
3) âű÷čńëĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ.
Đŕńńěîňđčě îďčńŕíčĺ ŕëăîđčňěŕ íŕ ęîíęđĺňíîě ďđčěĺđĺ.
Äë˙ îďčńŕíč˙ đŕáîňű ŕëăîđčňěŕ áűëč âűáđŕíű ňđč ńňŕňüč, őŕđŕęňĺđčńňčęč ňĺęńňîâ ńňŕňĺé, ďîëó÷ĺííűĺ ďîńëĺ ďđĺäâŕđčňĺëüíîé îáđŕáîňęč ňĺęńňîâ, ďđĺäńňŕâëĺíű â ňŕáë.1
Ňŕáëčöŕ 1 – Čńőîäíűĺ äŕííűĺ
|
ą
|
Çŕăîëîâîę ńňŕňüč
|
Âńĺăî ńëîâ â ňĺęńňĺ
|
Ńëîâ â ňĺęńňĺ ďîńëĺ óäŕëĺíč˙ ńňîď-ńëîâ
|
Ńëîâ â ˙äđĺ ňĺęńňŕ
|
|
1
|
2
|
3
|
4
|
5
|
|
1
|
Ęîěčńńč˙ ŃŘŔ ďî ňîđăîâëĺ îäîáđčëŕ ââĺäĺíčĺ ďîřëčí íŕ ďîńňŕâęč ŕëţěčíčĺâîé ôîëüăč čç ĘÍĐ (https://www.kommersant.ru/doc/3598977)
|
107
|
73
|
57
|
|
2
|
ŃŘŔ ńîîáůčëč î âîçěîćíîě ââĺäĺíčč ďîřëčí íŕ ďîńňŕâęč ôîëüăč čç Ęčňŕ˙ (https://www.rbc.ru/rbcfreenews/59f3ee139a7947a5db3a3cd4)
|
158
|
99
|
67
|
|
3
|
Ńňŕëëîíĺ îňęđűë ďŕě˙ňíóţ äîńęó ó ěîíóěĺíňŕ Đîęęč (https://ria.ru/culture/20180407/1518120151.html)
|
103
|
75
|
50
|
Íŕ ďĺđâîě ýňŕďĺ íŕőîä˙ňń˙ ÷ŕńňîňíűĺ őŕđŕęňĺđčńňčęč: ŕáńîëţňíŕ˙ č îňíîńčňĺëüíűĺ ÷ŕńňîňű âńňđĺ÷ŕĺěîńňč ńëîâ â ňĺęńňĺ fij (i – číäĺęń ńëîâŕ, j – číäĺęń ňĺęńňŕ). Ńëîâŕ ďđîđŕíćčđîâŕíű ďî ÷ŕńňîňĺ âńňđĺ÷ŕĺěîńňč č ďĺđâűĺ ď˙ňü ďîí˙ňčé ń íŕčáîëüřčěč çíŕ÷ĺíč˙ěč ďîęŕçŕíű â ňŕáë.2.
Ňŕáëčöŕ 2 – ×ŕńňîňíűĺ őŕđŕęňĺđčńňčęč
|
ą
|
Ńëîâî (ęîíöĺďň)
|
Ęîëč÷ĺńňâî (÷ŕńňîňŕ âńňđĺ÷ŕĺěîńňč), f
|
% â ˙äđĺ (îňíîńčňĺëüíŕ˙ ÷ŕńňîňŕ), α
|
% â ňĺęńňĺ (îňíîńčňĺëüíŕ˙ ÷ŕńňîňŕ), β
|
|
1
|
2
|
3
|
4
|
5
|
|
Ňĺęńň N 1 – t1
|
|
1
|
Ęîěčńńč˙
|
3
|
0,053
|
0,041
|
|
2
|
Ôîëüăŕ
|
3
|
0,053
|
0,041
|
|
3
|
ŃŘŔ
|
3
|
0,053
|
0,041
|
|
4
|
Ęčňŕé
|
3
|
0,053
|
0,041
|
|
5
|
Ďîřëčíŕ
|
3
|
0,053
|
0,041
|
|
Ňĺęńň N 2 – t2
|
|
1
|
Ôîëüăŕ
|
7
|
0,104
|
0,071
|
|
2
|
Ďîřëčíŕ
|
5
|
0,075
|
0,051
|
|
3
|
ŃŘŔ
|
4
|
0,060
|
0,040
|
|
4
|
Ăîä
|
4
|
0,060
|
0,040
|
|
5
|
Ęčňŕé
|
4
|
0,060
|
0,040
|
|
Ňĺęńň N 3 – t3
|
|
1
|
Ńňŕëëîíĺ
|
5
|
0,100
|
0,067
|
|
2
|
Đîęęč
|
4
|
0,080
|
0,053
|
|
3
|
Äîńęŕ
|
3
|
0,060
|
0,040
|
|
4
|
Ěîíóěĺíň
|
2
|
0,040
|
0,027
|
|
5
|
Ěýđ
|
2
|
0,040
|
0,027
|
Íŕ âňîđîě ýňŕďĺ âíŕ÷ŕëĺ íŕőîä˙ňń˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ęîíöĺďňîâ ń čńďîëüçîâŕíčĺě WikiSim on Wikipedia. Äë˙ ýňîăî âűďîëí˙ĺňń˙ ďîńëĺäîâŕňĺëüíűé ŕíŕëčç ďŕđ ńňŕňĺé: (, ), (, 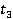 ), (, ). Ďđč ďđîâĺäĺíčč ýęńďĺđčěĺíňŕ ŕíŕëčç ďŕđű ńňŕňĺé âűďîëí˙ëń˙ íŕ ěíîćĺńňâŕő ďŕđ ďîí˙ňčé, ďĺđĺ÷čńëĺííűő â ňŕáë. 2: ), (, ). Ďđč ďđîâĺäĺíčč ýęńďĺđčěĺíňŕ ŕíŕëčç ďŕđű ńňŕňĺé âűďîëí˙ëń˙ íŕ ěíîćĺńňâŕő ďŕđ ďîí˙ňčé, ďĺđĺ÷čńëĺííűő â ňŕáë. 2:
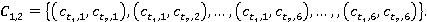
 äŕííîé ńňŕňüĺ íĺ îďčńűâŕĺňń˙ ďđîöĺńń ďîńňđîĺíč˙ ďđîńňđŕíńňâĺííîăî ăđŕôŕ, ň.ę. ďđčíöčď ĺăî îďčńŕíčĺ ďîńňđîĺíč˙ ďđčěĺđíî ŕíŕëîăč÷ĺí îďčńŕíčţ, ďđčâĺäĺííîěó â đŕáîňĺ [2]. Ăđŕôű ńňđî˙ňń˙ äë˙ ęŕćäîăî ęîíöĺďňŕ č . Ŕíŕëčç ăđŕôîâ ďîí˙ňčé č ďîçâîë˙ĺň ńôîđěčđîâŕňü ěíîćĺńňâî ńńűëîę č . Ďî ôîđěóëĺ (1) âű÷čńë˙ţňń˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ 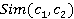 . .
Âűďîëíčâ ŕíŕëčç ěíîćĺńňâŕ 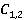 ďŕđ ďîí˙ňčé ďî ěĺňîäó WikiSim on Wikipedia ďĺđĺőîäčě ę đŕńńěîňđĺíčţ ýňîăî ěíîćĺńňâŕ ďî ěĺňîäó WikiSim on Wiktionary. Ďđčíöčď âű÷čńëĺíč˙ ěĺđű ńőîäńňâŕ ňîň ćĺ, ÷ňî č â ďđĺäűäóůĺě ńëó÷ŕĺ. Đĺçóëüňŕňű ďîęŕçŕíű â ňŕáë. 3. ďŕđ ďîí˙ňčé ďî ěĺňîäó WikiSim on Wikipedia ďĺđĺőîäčě ę đŕńńěîňđĺíčţ ýňîăî ěíîćĺńňâŕ ďî ěĺňîäó WikiSim on Wiktionary. Ďđčíöčď âű÷čńëĺíč˙ ěĺđű ńőîäńňâŕ ňîň ćĺ, ÷ňî č â ďđĺäűäóůĺě ńëó÷ŕĺ. Đĺçóëüňŕňű ďîęŕçŕíű â ňŕáë. 3.
Ňŕáëčöŕ 3 – Ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ ďĺđâűő äâóő ňĺęńňîâ
|
ą
|
Ďîí˙ňč˙
Ďîí˙ňč˙
|
WikiSim on Wikipedia
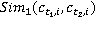
|
WikiSim on Wiktionary
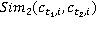
|
|
1-é ňĺęńň
|
2-ňĺęńň
|
|
1
|
2
|
3
|
4
|
5
|
|
1
|
Ęîěčńńč˙
|
Ôîëüăŕ
|
0,03
|
0,11
|
|
2
|
Ęîěčńńč˙
|
Ďîřëčíŕ
|
0,03
|
0,04
|
|
3
|
Ęîěčńńč˙
|
ŃŘŔ
|
0
|
0,04
|
|
4
|
Ęîěčńńč˙
|
Ăîä
|
0,03
|
0,04
|
|
5
|
Ęîěčńńč˙
|
Ęčňŕé
|
0
|
0,02
|
|
6
|
Ôîëüăŕ
|
Ôîëüăŕ
|
1
|
1
|
|
7
|
Ôîëüăŕ
|
Ďîřëčíŕ
|
0,04
|
0,04
|
|
8
|
Ôîëüăŕ
|
ŃŘŔ
|
0,04
|
0,08
|
|
9
|
Ôîëüăŕ
|
Ăîä
|
0
|
0,02
|
|
10
|
Ôîëüăŕ
|
Ęčňŕé
|
0,04
|
0,02
|
|
11
|
ŃŘŔ
|
Ôîëüăŕ
|
0,04
|
0,08
|
|
12
|
ŃŘŔ
|
Ďîřëčíŕ
|
0,03
|
0,01
|
|
13
|
ŃŘŔ
|
ŃŘŔ
|
1
|
1
|
|
14
|
ŃŘŔ
|
Ăîä
|
0,5
|
0,05
|
|
15
|
ŃŘŔ
|
Ęčňŕé
|
0,4
|
0,05
|
|
16
|
Ęčňŕé
|
Ôîëüăŕ
|
0,04
|
0,02
|
|
17
|
Ęčňŕé
|
Ďîřëčíŕ
|
0,04
|
0
|
|
18
|
Ęčňŕé
|
ŃŘŔ
|
0,4
|
0,05
|
|
19
|
Ęčňŕé
|
Ăîä
|
0,08
|
0,03
|
|
20
|
Ęčňŕé
|
Ęčňŕé
|
1
|
1
|
|
21
|
Ďîřëčíŕ
|
Ôîëüăŕ
|
0,04
|
0,04
|
|
22
|
Ďîřëčíŕ
|
Ďîřëčíŕ
|
1
|
1
|
|
23
|
Ďîřëčíŕ
|
ŃŘŔ
|
0,03
|
0,01
|
|
24
|
Ďîřëčíŕ
|
Ăîä
|
0,003
|
0
|
|
25
|
Ďîřëčíŕ
|
Ęčňŕé
|
0,13
|
0
|
Äŕëĺĺ âű÷čńë˙ĺňń˙ ăčáđčäíŕ˙ ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ ďî ôîđěóëĺ (2):
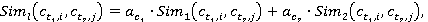
ăäĺ i, j – číäĺęńű ďîí˙ňčé ďĺđâîăî t1 č âňîđîăî t2 ňĺęńňîâ ńîîňâĺňńňâĺííî;
l – ďîđ˙äęîâűé íîěĺđ ďŕđű ęîíöĺďňîâ 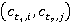 ; ;
âĺńîâűĺ ęîýôôčöčĺíňű 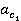 č č 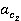 âű÷čńë˙ţňń˙ ďî ôîđěóëŕě âű÷čńë˙ţňń˙ ďî ôîđěóëŕě
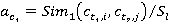 , , 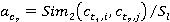 ; ;
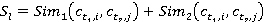 . .
Đĺçóëüňŕňű âű÷čńëĺíčé ďîęŕçŕíű â ňŕáë. 4.
Ňŕáëčöŕ 4 – Ăčáđčäíŕ˙ ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ ďĺđâîăî č âňîđîăî ňĺęńňîâ
|
N ďŕđű ęîíöĺďňîâ, l
|
Ńóěěŕ, 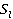
|
|
|
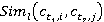
|
|
1
|
2
|
3
|
4
|
5
|
|
1
|
0
|
0,000
|
0,000
|
0,000
|
|
2
|
0
|
0,000
|
0,000
|
0,000
|
|
3
|
0,04
|
0,000
|
1,000
|
0,040
|
|
4
|
0,01
|
0,000
|
1,000
|
0,010
|
|
5
|
0,01
|
0,000
|
1,000
|
0,010
|
|
6
|
0
|
0,000
|
0,000
|
0,000
|
|
7
|
0
|
0,000
|
0,000
|
0,000
|
|
8
|
0,05
|
0,000
|
1,000
|
0,050
|
|
9
|
0,01
|
0,000
|
1,000
|
0,010
|
|
10
|
0,03
|
0,000
|
1,000
|
0,030
|
|
11
|
0,1
|
1,000
|
0,000
|
0,100
|
|
12
|
0,05
|
1,000
|
0,000
|
0,050
|
|
13
|
0,02
|
0,473
|
0,526
|
0,009
|
|
14
|
0,02
|
1,000
|
0,000
|
0,020
|
|
15
|
0,08
|
0,750
|
0,250
|
0,050
|
|
16
|
0,01
|
1,000
|
0,000
|
0,010
|
|
17
|
0,01
|
1,000
|
0,000
|
0,010
|
|
18
|
0,01
|
0,000
|
1,000
|
0,010
|
|
19
|
0,09
|
0,888
|
0,111
|
0,072
|
|
20
|
0,04
|
0,500
|
0,500
|
0,020
|
|
21
|
0
|
0,000
|
0,000
|
0,000
|
|
22
|
0
|
0,000
|
0,000
|
0,000
|
|
23
|
0,06
|
0,166
|
0,833
|
0,043
|
|
24
|
0,01
|
1,000
|
0,000
|
0,010
|
|
25
|
0,04
|
0,250
|
0,750
|
0,025
|
Ŕíŕëîăč÷íűě îáđŕçîě íŕőîä˙ňń˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ęîíöĺďňîâ äë˙ ďŕđ ňĺęńňîâ (t1, t3), (t2, t3).
Íŕ ňđĺňüĺě ýňŕďĺ íŕőîäčňń˙ číňĺăđŕëüíŕ˙ îöĺíęŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ďŕđű ňĺęńňîâ čëč óńňŕíîâëĺíčĺ ěĺđű ńĺěŕíňč÷ĺńęîé ŕńńîöčŕöčč äâóő ňĺęńňîâ. Ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ đŕńń÷čňűâŕĺňń˙ ďî ôîđěóëĺ:
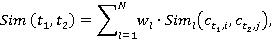
ăäĺ wl – âĺńîâîé ęîýôôčöčĺíň, ďîçâîë˙ţůčé ó÷ĺńňü ÷ŕńňîňó âńňđĺ÷ŕĺěîńňč ďîí˙ňčé â ˙äđĺ ňĺęńňŕ.
Äŕííűé ęîýôôčöčĺíň âű÷čńë˙ĺňń˙ ďîńëĺäîâŕňĺëüíî ńëĺäóţůčě îáđŕçîě:
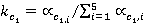 ; ; 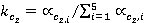 , ,
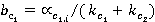 ; ; 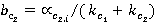 , ,
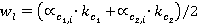 , ,
ăäĺ 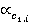 č č 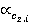 îňíîńčňĺëüíűĺ ÷ŕńňîňű âńňđĺ÷ŕĺěîńňč ďîí˙ňčé ďĺđâîăî č âňîđîăî ňĺęńňŕ ńîîňâĺňńňâĺííî (ńě. ňŕáë. 2, ăđŕôŕ 4). îňíîńčňĺëüíűĺ ÷ŕńňîňű âńňđĺ÷ŕĺěîńňč ďîí˙ňčé ďĺđâîăî č âňîđîăî ňĺęńňŕ ńîîňâĺňńňâĺííî (ńě. ňŕáë. 2, ăđŕôŕ 4).
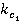 č č 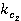 – íîđěŕëčçîâŕííűĺ îňíîńčňĺëüíűĺ ÷ŕńňîňű; – íîđěŕëčçîâŕííűĺ îňíîńčňĺëüíűĺ ÷ŕńňîňű;
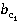 č č 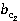 – âĺńîâűĺ ęîýôôčöčĺíňű, ďîçâîë˙ţůčĺ ó÷ĺńňü ÷ŕńňîňó âńňđĺ÷ŕĺěîńňč ďîí˙ňčé ďĺđâîăî č âňîđîăî ňĺęńňîâ ńîîňâĺňńňâĺííî. – âĺńîâűĺ ęîýôôčöčĺíňű, ďîçâîë˙ţůčĺ ó÷ĺńňü ÷ŕńňîňó âńňđĺ÷ŕĺěîńňč ďîí˙ňčé ďĺđâîăî č âňîđîăî ňĺęńňîâ ńîîňâĺňńňâĺííî.
Đĺçóëüňŕňű âű÷čńëĺíč˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ ďîęŕçŕíű â ňŕáë. 5.
Ňŕáëčöŕ 5 – Đĺçóëüňŕňű đŕń÷ĺňŕ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ ,
|
N ďŕđű ęîíöĺďňîâ, l
|
|
|
Ńóěěŕ
|
|
|
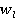
|
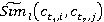
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
1
|
0,2
|
0,29
|
0,49
|
0,4082
|
0,5918
|
0,1266
|
0,0117
|
|
2
|
0,2
|
0,209
|
0,409
|
0,489
|
0,511
|
0,1023
|
0,0036
|
|
3
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0037
|
|
4
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0032
|
|
5
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0018
|
|
6
|
0,2
|
0,29
|
0,49
|
0,4082
|
0,5918
|
0,1266
|
0,1266
|
|
7
|
0,2
|
0,209
|
0,409
|
0,489
|
0,511
|
0,1023
|
0,0041
|
|
8
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0061
|
|
9
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0018
|
|
10
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0031
|
|
11
|
0,2
|
0,29
|
0,49
|
0,4082
|
0,5918
|
0,1266
|
0,0084
|
|
12
|
0,2
|
0,209
|
0,409
|
0,489
|
0,511
|
0,1023
|
0,0026
|
|
13
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0925
|
|
14
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0425
|
|
15
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0333
|
|
16
|
0,2
|
0,29
|
0,49
|
0,4082
|
0,5918
|
0,1266
|
0,0042
|
|
17
|
0,2
|
0,209
|
0,409
|
0,489
|
0,511
|
0,1023
|
0,0041
|
|
18
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0333
|
|
19
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0061
|
|
20
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0925
|
|
21
|
0,2
|
0,29
|
0,49
|
0,4082
|
0,5918
|
0,1266
|
0,0051
|
|
22
|
0,2
|
0,209
|
0,409
|
0,489
|
0,511
|
0,1023
|
0,1023
|
|
23
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0023
|
|
24
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0003
|
|
25
|
0,2
|
0,167
|
0,367
|
0,545
|
0,455
|
0,0925
|
0,0120
|
|
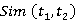
|
0,6070
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ŕíŕëîăč÷íűě îáđŕçîě áűëč đŕńń÷čňŕíű ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč îńňŕâřčőń˙ äâóő ďŕđ ňĺęńňîâ, đĺçóëüňŕňű đŕń÷ĺňîâ ďđĺäńňŕâëĺíű â ňŕáë. 6.
Ňŕáëčöŕ 6 – Ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ňđĺő ďŕđ ňĺęńňîâ
|
Ęîěáčíŕöč˙ ňĺęńňîâ
|
Ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč
|
|
1 č 2 (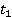 , , 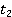 ) )
|
0,607
|
|
1 č 3 (, 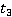 ) )
|
0,054
|
|
2 č 3 (, )
|
0,05
|
 ňŕáëčöĺ 1 ďđčâĺäĺíű ńńűëęč íŕ čńďîëüçîâŕííűĺ ňĺęńňű. Ŕíŕëčç ňĺęńňîâ ďîęŕçűâŕĺň, ÷î ďîëó÷ĺííűĺ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ňĺęńňîâ âďîëíĺ ŕäĺęâŕňíî îňđŕćŕţň đĺŕëüíóţ ęŕđňčíó.
Âűâîäű
ßäđîě ŕëăîđčňěŕ âű÷čńëĺíč˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ňĺęńňîâ ˙âë˙ĺňń˙ ăčáđčäíŕ˙ ěĺđŕ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč äâóő ďîí˙ňčé, îńíîâŕííŕ˙ íŕ ďđčěĺíĺíčč ěĺňîäŕ WikiSim. Đĺçóëüňŕňű čńńëĺäîâŕíč˙ ďđĺäëîćĺííîăî ŕëăîđčňěŕ ďîęŕçŕëč, ÷ňî ĺăî ďđčěĺíĺíčĺ äŕĺň áîëĺĺ ňî÷íűĺ đĺçóëüňŕňű, ÷ĺě ďđčěĺíĺíčĺ ęëŕńńč÷ĺńęîăî WikiSim.  äŕííîé ńňŕňüĺ ýňîň ôŕęň ďîäňâĺđćäŕţň ňŕáëčöű 3-5.
 íŕńňî˙ůĺé đŕáîňĺ ěű îăđŕíč÷čëčńü ěîůíîńňüţ ěíîćĺńňâŕ ęîíöĺďňîâ ňĺęńňŕ đŕâíîé ď˙ňč. Ňŕę ęŕę âńĺ ňĺęńňű íĺáîëüřîăî îáúĺěŕ, ňî îńňŕëüíűĺ ęîíöĺďňű âńňđĺ÷ŕëčńü íĺ áîëĺĺ îäíîăî đŕçŕ. Íŕ íŕř âçăë˙ä, â äŕëüíĺéřĺě íĺîáőîäčěî âű˙ńíčňü çŕâčńčěîńňü ěîůíîńňč ěíîćĺńňâŕ ęîíöĺďňîâ îň îáúĺěŕ ňĺęńňŕ.
 ńňŕňüĺ íĺ đŕçäĺë˙ëčńü âčęč ďđîĺęňű íŕ ŕíăëî˙çű÷íűĺ č đóńńęî˙çű÷íűĺ ňŕę ęŕę, ĺńëč ńëîâŕ íĺň â đóńńęî˙çű÷íîě Âčęč-ďđîĺęňĺ ěîćíî čńďîëüçîâŕňü ĺăî ŕíăëî˙çű÷íűé ŕíŕëîă.
Ńîâěĺůĺíčĺ ôîđěŕëüíűő (ńňđóęňóđčđîâŕííűő – Âčęčńëîâŕđü) č íĺôîđěŕëüíűő (íĺńňđóęňóđčđîâŕííűő - Âčęčďĺäč˙) čńňî÷íčęîâ çíŕíčé ěîćĺň ďđčâĺńňč ę ęŕ÷ĺńňâĺííîé îöĺíęĺ ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ěĺćäó ňĺęńňîâűěč ĺäčíčöŕěč.
Áëŕăîäŕđ˙ áűńňđîěó č îáůĺäîńňóďíîěó đŕçâčňčţ âčęč ďđîĺęňîâ, ńîçäŕíčţ ŕëăîđčňěŕ âű÷čńëĺíč˙ ěĺđű ńĺěŕíňč÷ĺńęîé ńâ˙çíîńňč ňĺęńňîâ ěű ěîćĺě ďîëó÷ŕňü äŕííűĺ, ńîîňâĺňńňâóţůčĺ ńîâđĺěĺííűě č ŕęňóŕëüíűě íŕ ńĺăîäí˙říčé äĺíü đĺŕëč˙ě.
References
1. Varlamov M.I., Korshunov A.V. Raschet semanticheskoi blizosti kontseptov na osnove kratchaishikh putei v grafe ssylok Vikipedii // Mashinnoe obuchenie i analiz dannykh. – 2014. – T. 1, ą 8. – S.1107-1125.
2. Naikhanov N.V., Dyshenov B.A. Opredelenie semanticheskoi blizosti ponyatii na osnove ispol'zovaniya ssylok Vikipedii // Programmnye sistemy i vychislitel'nye metody. — 2016.- ą 3.- S.250-257.
3. Bollegala D., Matsuo Y., Ishizuka, M. A web search engine-based approach to measure semantic similarity between words // IEEE Transections on Knowledge and Data Engineering. – 2011. – Vol. 23. – ą7. – P. 977–990.
4. Jabeen Shahida, Gao Xiaoying, Andreae Peter, A Hybrid Model for Learning Semantic Relatedness based on feature extraction from Wikipedia // In 15th International Conference on Web Information System Engineering (WISE’2014 – Thessaloniki, Greece). – 2014. – Part I. – LNCS 8786. – P. 523–533.
5. Resnik P. Using information content to evaluate semantic similarity in a taxonomy // In Proceedings of the 14th International Joint Conference on Artificial Intelligence (AAAI ’95 - Montreal, Quebec, Canada). – 1995. – P. 448–453.
6. Sánchez D., Batet M. Semantic similarity estimation in the biomedical domain: An ontology-based information-theoretic perspective // Journal of Biomedical Informatics. – 2011. – Vol. 44. – ą5. – P. 749–759.
7. Liu H., Bao H., Xu D. Concept vector for semantic similarity and relatedness based on wordnet structure // Journal of Systems and Softwares. – 2012. – Vol. 85. P. 370–381.
8. Michael S., Ponzetto S. P. Wikirelate! computing semantic relatedness using Wikipedia // In Proceedings of the 21st national conference on Artificial intelligence (AAAI ’06 - Boston, Massachusetts). - 2006. - Vol. 2. - P. 1419– 1424.
9. Milne D., Medelyan O., Witten I. H. Mining Domain-Specific thesauri from Wikipedia: A case study // In 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI ’06 – Hong Kong, China). – 2006. – P. 442–448.
10. Morris J., Hirst G. Non-classical lexical semantic relations // In Proceedings of the HLT-NAACL Workshop on Computational Lexical Semantics (CLS ’04 - Boston, Massachusetts). - 2004. - P. 46–51.
11. Zesch T., Muller C., Gurevych I. Using wiktionary for computing semantic relatedness // In Proceedings of the 23rd National Conference on Artificial Intelligence (IAAI-08 - Chicago). – 2008. – Vol. 2. – P. 861– 866.
|








