|
Cybernetics and programming
Reference:
Raikhlin V.A., Minyazev R.S., Klassen R.K.
The efficiency of a large conservative type DBMS on a cluster platform
// Cybernetics and programming.
2018. ą 5.
P. 44-62.
DOI: 10.25136/2644-5522.2018.5.22301 URL: https://en.nbpublish.com/library_read_article.php?id=22301
The efficiency of a large conservative type DBMS on a cluster platform
Raikhlin Vadim Abramovich
Doctor of Physics and Mathematics
Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10

|
no-form@evm.kstu-kai.ru
|
|
 |
Minyazev Rinat Shavkatovich
PhD in Technical Science
Associate Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10
|
|
txf13@mail.ru
|
|
 |
|
Klassen Roman Konstantinovich
Postgraduate Student, Department of Computer Systems, Tupolev Kazan National Research Technical University
420111, Russia, respublika Tatarstan, g. Kazan', ul. K.marksa, 10
|
|
klassen.rk@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2018.5.22301
Received:
14-03-2017
Published:
25-11-2018
Abstract:
The results of original research on the principles of organization and features of the operation of conservative DBMS of cluster type are discussed. The relevance of the adopted orientation to work with large-scale databases is determined by modern trends in the intellectual processing of large information arrays. Increasing the volume of databases requires them to be hashed over cluster nodes. This necessitates the use of a regular query processing plan with dynamic segmentation of intermediate and temporary relationships. A comparative evaluation of the results obtained with the alternative "core-to-query" approach is provided, provided that the database is replicated across cluster nodes. A significant place in the article is occupied by a theoretical analysis of GPU-accelerations with respect to conservative DBMS with a regular query processing plan. Experimental studies were carried out on specially developed full-scale models - Clusterix, Clusterix-M, PerformSys with MySQL at the executive level. Theoretical analysis of the GPU-accelerations is performed using the example of the proposed project Clusterix-G. The following are shown: the peculiarities of the behavior of the Clusterix DBMS in dynamics and the optimal architectural variant of the system; Increased "many times" scalability and system performance in the transition to multiclustering (DBMS Clusterix-M) or to the advanced technology "core-to-query" (PerformSys); Non-competitiveness of GPU-acceleration in comparison with the "core-to-query" approach for medium-sized databases that do not exceed the size of the cluster's memory, but do not fit into the GPU's global memory. For large-scale databases, a hybrid technology (the Clusterix-G project) is proposed with the cluster divided into two parts. One of them performs selection and projection over a hashed by nodes and a compressed database. The other is a core-to-query connection. Functions of GPU accelerators in different parts are peculiar. Theoretical analysis showed greater effectiveness of such technology in comparison with Clusterix-M. But the question of the advisability of using graphic accelerators within this architecture requires further experimental research. It is noted that the Clusterix-M project remains viable in the Big Data field. Similarly - with the "core-to-query" approach with the availability of modern expensive information technologies.
Keywords:
Conservative DBMS, Big Data, Regular processing plan, Host hashing, Dynamic relationship segmentation, Scalability, Performance, Multiclusterisation, Advanced technology, GPU-accelerators efficiency
Čńďîëüçóĺěűĺ îáîçíŕ÷ĺíč˙ – Clusterix, Clusterix-M, Clusterix-G– íŕçâŕíč˙ çŕňđŕăčâŕĺěűő â ńňŕňüĺ ďđîĺęňîâ ęîíńĺđâŕňčâíűő ŃÓÁÄ íŕ ęëŕńňĺđíîé ďëŕňôîđěĺ, ďđčí˙ňűĺ đŕçđŕáîň÷čęŕěč ýňčő ďđîĺęňîâ.
– MySQL – ďđčěĺí˙ĺěŕ˙ â ýňčő ďđîĺęňŕő číńňđóěĺíňŕëüíŕ˙ ŃÓÁÄ.
– PerformSys («˙äđî íŕ çŕďđîń», «óçĺë íŕ ěíîćĺńňâî çŕďđîńîâ») – ďĺđńďĺęňčâíŕ˙ ňĺőíîëîăč˙ ęîíńĺđâŕňčâíűő ŃÓÁÄ.
– GPU(Graphics Processing Unit) – ńîďđîöĺńńîđ, řčđîęî ďđčěĺí˙ĺěűé ęŕę óńęîđčňĺëü ňđĺőěĺđíîé ăđŕôčęč. Čńďîëüçóĺňń˙ č ďđč âűďîëíĺíčč îáű÷íűő âű÷čńëĺíčé – ďîäőîä GPGPU (General-Purpose GPU).
– CPU – öĺíňđŕëüíűé ďđîöĺńńîđ.
– TPC(Transaction Processing Performance Council) – Ńîâĺň ďî ďđîčçâîäčňĺëüíîńňč îáđŕáîňęč ňđŕíçŕęöčé.
– TPC-H – îäčí čç ňĺńňîâ ďđîčçâîäčňĺëüíîńňč ńčńňĺě ďđčí˙ňč˙ đĺřĺíčé. Ââĺäĺíčĺ Ďđîáëĺěŕ ěŕńřňŕáčđóĺěîńňč ďî ÷čńëó óçëîâ ęëŕńňĺđŕ č ďîâűřĺíč˙ ďđîčçâîäčňĺëüíîńňč âńĺăäŕ áűëŕ č îńňŕĺňń˙ îäíîé čç ńĺđüĺçíĺéřčő ďđîáëĺě ďŕđŕëëĺëüíűő ŃÓÁÄ [1-4].  íŕńňî˙ůĺĺ âđĺě˙ čěĺĺňń˙ íĺěŕëîĺ ÷čńëî đŕçđŕáîňîę ňŕęčő ŃÓÁÄ íŕ ďëŕňôîđěĺ âű÷čńëčňĺëüíűő ęëŕńňĺđîâ. Áîëüřčíńňâî čç íčő îńóůĺńňâë˙ĺň ďîääĺđćęó đŕáîňű internet-ńĺđâčńîâ, âűďîëí˙ţůčő ńđŕâíčňĺëüíî ďđîńňűĺ îďĺđŕöčé ňčďŕ selectč insertíŕä äčíŕěč÷ĺńęč čçěĺí˙ĺěűěč áŕçŕěč äŕííűő. Ďđč÷číŕ â ňîě, ÷ňî ďîâűřĺíčĺ ńęîđîńňč îáđŕáîňęč ńëîćíűő çŕďđîńîâ äî ńčő ďîđ ďđîáëĺěŕňč÷íî [5]. Íŕřĺ đŕńńěîňđĺíčĺ îđčĺíňčđîâŕíî íŕ ďîńňđîĺíčĺ ďŕđŕëëĺëüíűő ŃÓÁÄ ęîíńĺđâŕňčâíîăî ňčďŕ (ń ýďčçîäč÷ĺńęčě îáíîâëĺíčĺě äŕííűő â ńďĺöčŕëüíî âűäĺë˙ĺěîĺ âđĺě˙) áîëüřčő îáúĺěîâ (äî ĺäčíčö TB). Ĺăî ŕęňóŕëüíîńňü îďđĺäĺë˙ĺňń˙ ňĺíäĺíöč˙ěč číňĺëëĺęňóŕëüíîé îáđŕáîňęč číôîđěŕöčîííűő ěŕńńčâîâ. Ďđčěĺđîě ňîěó ˙âë˙ĺňń˙ ďđîĺęň ńďĺöčŕëčçčđîâŕííîé ńčńňĺěű SciDB äë˙ îáđŕáîňęč íŕó÷íűő äŕííűő (đĺçóëüňŕňîâ čńďűňŕíčé, íŕáëţäĺíčé çŕ ńîńňî˙íčĺě ńđĺäű č äđ.) [6-8]. Äë˙ íčő őŕđŕęňĺđĺí âűńîęčé óäĺëüíűé âĺń čěĺííî ńëîćíűő çŕďđîńîâ ňčďŕ select – project – join, îďĺđčđóţůčő ěíîćĺńňâîě ňŕáëčö ń áîëüřčě ÷čńëîě îďĺđŕöčé ńîĺäčíĺíč˙ join. Ňŕęčĺ áŕçű äŕííűő ďđčőîäčňń˙ őĺřčđîâŕňü ďî óçëŕě ęëŕńňĺđŕ.
Ďîýňîěó ĺäčíńňâĺííî ďđčĺěëĺěűě ďëŕíîě îáđŕáîňęč çŕďđîńîâ îęŕçűâŕĺňń˙ đĺăóë˙đíűé [9] (đčń.1) ďî ńőĺěĺ
ŃĹËĹĘÖČß (σ) – ĎĐÎĹĘÖČß (π) – ŃÎĹÄČÍĹÍČĹ (σθ(R x S)) .
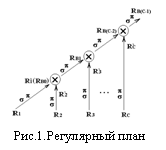 Çäĺńü < x > – äĺęŕđňîâî ďđîčçâĺäĺíčĺ, ńĺëĺęňčđîâŕíčĺ â îďĺđŕöčč ńîĺäčíĺíč˙ âĺäĺňń˙ ďî θ‑ńîîňâĺňńňâčţ ęîđňĺćĺé îňíîřĺíčé R č S. Ďî óńëîâčţńîĺäčíĺíčĺ âńĺăäŕ ĺńňĺńňâĺííîĺ č ďđîâîäčňń˙ ďî ďîë˙ě ďĺđâč÷íîăî ęëţ÷ŕ. Ďđč čńďîëüçîâŕíčč ńňđŕňĺăčč «ěíîćĺńňâî óçëîâ ęëŕńňĺđŕ – íŕ îäčí çŕďđîń» áŕçŕ äŕííűő îęŕçűâŕĺňń˙ đŕńďđĺäĺëĺííîé ďî óçëŕě. Ďîëó÷ĺíčĺ ëţáîăî ďđîěĺćóňî÷íîăî Ri' č ëţáîăî âđĺěĺííîăî RB(i-2) îňíîřĺíčé ďđîčńőîäčň ďŕđŕëëĺëüíî. Ďđč ýňîě ňĺîđĺňč÷ĺńęč âîçěîćíî ńîâěĺůĺíčĺ îáîčő ďđîöĺńńîâ, ĺńëč çŕ âđĺě˙ ńúĺěŕ ń äčńęîâ č ďđĺäâŕđčňĺëüíîé îáđŕáîňęč (ńĺëĺęöčč ń ďđîĺęöčĺé) čńőîäíîăî îňíîřĺíč˙ Rióńďĺâŕĺň ńôîđěčđîâŕňüń˙ âđĺěĺííîĺ îňíîřĺíčĺ RB(i-2). Äë˙ öĺëĺé čńńëĺäîâŕíč˙ áűëŕ đŕçđŕáîňŕíŕ íŕňóđíŕ˙ ěîäĺëü – ŃÓÁÄ Clusterix[10]. Çäĺńü < x > – äĺęŕđňîâî ďđîčçâĺäĺíčĺ, ńĺëĺęňčđîâŕíčĺ â îďĺđŕöčč ńîĺäčíĺíč˙ âĺäĺňń˙ ďî θ‑ńîîňâĺňńňâčţ ęîđňĺćĺé îňíîřĺíčé R č S. Ďî óńëîâčţńîĺäčíĺíčĺ âńĺăäŕ ĺńňĺńňâĺííîĺ č ďđîâîäčňń˙ ďî ďîë˙ě ďĺđâč÷íîăî ęëţ÷ŕ. Ďđč čńďîëüçîâŕíčč ńňđŕňĺăčč «ěíîćĺńňâî óçëîâ ęëŕńňĺđŕ – íŕ îäčí çŕďđîń» áŕçŕ äŕííűő îęŕçűâŕĺňń˙ đŕńďđĺäĺëĺííîé ďî óçëŕě. Ďîëó÷ĺíčĺ ëţáîăî ďđîěĺćóňî÷íîăî Ri' č ëţáîăî âđĺěĺííîăî RB(i-2) îňíîřĺíčé ďđîčńőîäčň ďŕđŕëëĺëüíî. Ďđč ýňîě ňĺîđĺňč÷ĺńęč âîçěîćíî ńîâěĺůĺíčĺ îáîčő ďđîöĺńńîâ, ĺńëč çŕ âđĺě˙ ńúĺěŕ ń äčńęîâ č ďđĺäâŕđčňĺëüíîé îáđŕáîňęč (ńĺëĺęöčč ń ďđîĺęöčĺé) čńőîäíîăî îňíîřĺíč˙ Rióńďĺâŕĺň ńôîđěčđîâŕňüń˙ âđĺěĺííîĺ îňíîřĺíčĺ RB(i-2). Äë˙ öĺëĺé čńńëĺäîâŕíč˙ áűëŕ đŕçđŕáîňŕíŕ íŕňóđíŕ˙ ěîäĺëü – ŃÓÁÄ Clusterix[10].
1. ŃÓÁÄ Clusterix Ôóíęöčîíŕëüíŕ˙ őŕđŕęňĺđčńňčęŕ. Îáđŕáîňęŕ çŕďđîńîâ – 2-óđîâíĺâŕ˙. Íŕ íčćíĺě óđîâĺíĺ âűďîëí˙ţňń˙ îďĺđŕöčč ńĺëĺęöčč (σ) č ďđîĺęöčč (π) íŕä čńőîäíűěč îňíîřĺíč˙ěč Riáŕçű äŕííűő. Đĺçóëüňŕňîě îáđŕáîňęč ýňîăî óđîâí˙ ˙âë˙ĺňń˙ ďđîěĺćóňî÷íîĺ îňíîřĺíčĺ Ri'. Íŕ âĺđőíĺě óđîâíĺ đĺŕëčçóĺňń˙ îďĺđŕöč˙ ńîĺäčíĺíč˙ RBi–1 = Ri' ►◄ RBi–2 = π (σθ(Ri'xRBi–2)), ăäĺ RBi–1 č RBi–2 – âđĺěĺííűĺ îňíîřĺíč˙ ęŕę đĺçóëüňŕňű ńîĺäčíĺíčé â i- č â (i-1)-řŕăŕő ńîîňâĺňńňâĺííî. Ôčëüňđŕöč˙ íŕ íčćíĺě óđîâíĺ çíŕ÷čňĺëüíî ńíčćŕĺň îáúĺěű äŕííűő, ďĺđĺäŕâŕĺěűő íŕ âĺđőíčé óđîâĺíü.
Îňíîřĺíč˙ ÁÄ đŕńďđĺäĺëĺíű ďî äčńęŕě íŕ ďđîöĺńńîđŕő íčćíĺăî óđîâí˙ (IOr) ń ďđčěĺíĺíčĺě őĺř-ôóíęöčč ę ďĺđâč÷íîěó ęëţ÷ó äë˙ ęŕćäîăî ęîđňĺćŕ îňíîřĺíč˙. Ňđĺáîâŕíčţ đŕâíîěĺđíîăî đŕńďđĺäĺëĺíč˙ ęîđňĺćĺé őîđîřî óäîâëĺňâîđ˙ĺň âűáîđ â ęŕ÷ĺńňâĺ íĺĺ ôóíęöčč äĺëĺíč˙ ďî ěîäóëţ [11]. Îńíîâŕíčĺ äĺëĺíč˙ – ÷čńëî ďđîöĺńńîđîâ íčćíĺăî óđîâí˙ (nIO). Îńňŕňîę îň äĺëĺíč˙ r îäíîçíŕ÷íî îďđĺäĺë˙ĺň íîěĺđ ńňđŕíčöű (ďđîöĺńńîđŕ IOr), ęóäŕ áóäĺň đŕńďđĺäĺëĺí ęîđňĺć. Ďđîöĺńńîđű âĺđőíĺăî óđîâí˙ îáđŕáîňęč çŕďđîńŕ íŕçűâŕţňń˙ ďđîöĺńńîđŕěč JOIN. Őĺř-ôóíęöč˙, čńďîëüçîâŕííŕ˙ â Clusterix, čěĺĺň ńëĺäóţůčé âčä:
hash=((key_field1 mod M) + (key_field2 mod M) + … + (key_fieldP mod M)) mod M,
ăäĺ P – ęîëč÷ĺńňâî ďîëĺé â ďĺđâč÷íîě ęëţ÷ĺ; M = nIO– îńíîâŕíčĺ äĺëĺíč˙ ďî ěîäóëţ; mod – îďĺđŕöč˙ äĺëĺíč˙ ďî ěîäóëţ. Ęŕę ďîęŕçŕëč ýęńďĺđčěĺíňű íŕ ďđčěĺđĺ ňĺńňŕ TPC-H (M=2,3,4,6,8,12,16,18,24), äŕííűé ďîäőîä îáĺńďĺ÷čâŕĺň äîńňŕňî÷íî đŕâíîěĺđíîĺ đŕńďđĺäĺëĺíčĺ äŕííűő ďî ńňđŕíčöŕě. Őĺřčđîâŕííűĺ ńňđŕíčöű őđŕí˙ňń˙ íŕ óçëŕő IOr â âčäĺ îňíîřĺíčé áŕçű äŕííűő tpchK, ăäĺ K = r.
Ęđîěĺ čńďîëíčňĺëüíűő ďđîöĺńńîđîâ (IOr č JOINj), ĺńňü ĺůĺ äâŕ ďđîöĺńńîđŕ. Ďđîöĺńńîđ ÓĎĐ đĺŕëčçóĺň ôóíęöčč ěîíčňîđčíăŕ č óďđŕâëĺíč˙ îńňŕëüíűěč ďđîöĺńńîđŕěč ńčńňĺěű. Äë˙ đĺŕëčçŕöčč ôóíęöčé îáúĺäčíĺíč˙ đĺçóëüňŕňîâ îáđŕáîňęč ń óđîâí˙ JOIN ââĺäĺí ďđîöĺńńîđ SORT. Îí äîďîëíčňĺëüíî âűďîëí˙ĺň ôóíęöčč ŕăđĺăŕöčč (SUM(), AVG(), MAX(), MIN() č äđ.) č ńîđňčđîâęč đĺçóëüňŕňŕ ďđĺäřĺńňâóţůĺé îďĺđŕöčč ńîĺäčíĺíč˙. Â Clusterix đĺŕëčçîâŕí âŕđčŕíň ńîâěĺńňíîé đŕáîňű ďđîöĺńńîđîâ ÓĎĐ č SORT íŕ Host ÝÂĚ. Đŕáîňŕ íŕ óđîâíĺ ôŕéëîâîé ńčńňĺěű, ńčńňĺěíűő áóôĺđîâ, ŕëăîđčňěîâ äîńňóďŕ ę äŕííűě, đŕáîňű ń číäĺęńŕěč č ň.ď. đĺŕëčçóĺňń˙ ń ďîěîůüţ ńňŕíäŕđňíîé ŃÓÁÄ MySQL.
Ńčńňĺěŕ đĺŕëčçóĺň ďîňîęîâî-ęîíâĺéĺđíűé ěĺőŕíčçě îáđŕáîňęč çŕďđîńîâ. Ęîíâĺéĺđíîńňü äîńňčăŕĺňń˙ çŕ ń÷ĺň ńîâěĺůĺíč˙ đŕáîň íŕ íčćíĺě, âĺđőíĺě óđîâí˙ő îáđŕáîňęč č íŕ óđîâíĺ SORT (đčń.2). Ňŕę đĺŕëčçóĺňń˙ âĺđňčęŕëüíűé ďŕđŕëëĺëčçě. Ĺăî îńîáĺííîńňüţ ˙âë˙ĺňń˙ ńîâěĺůĺíčĺ ďîńëĺäíĺé îďĺđŕöčč íŕ óđîâíĺ JOIN äë˙ îäíîăî çŕďđîńŕ č ďĺđâîé îďĺđŕöčč íŕ óđîâíĺ IO äë˙ ńëĺäóţůĺăî.

 Clusterix đĺŕëčçóĺňń˙ č ăîđčçîíňŕëüíűé ďŕđŕëëĺëčçě, ęîňîđűé äîńňčăŕĺňń˙ ďŕđŕëëĺëüíîé đŕáîňîé íĺńęîëüęčő ďđîöĺńńîđîâ îäíîăî óđîâí˙ íŕä đŕçíűěč ÷ŕńň˙ěč äŕííűő îäíîăî č ňîăî ćĺ çŕďđîńŕ. Ďđčěĺíĺíčĺ äčíŕěč÷ĺńęîé ńĺăěĺíňŕöčč ďđîěĺćóňî÷íűő č âđĺěĺííűő îňíîřĺíčé ďîçâîë˙ĺň đĺŕëčçîâŕňü ďŕđŕëëĺëüíîĺ âűďîëíĺíčĺ îďĺđŕöčč ńîĺäčíĺíč˙ íŕ ěíîćĺńňâĺ ďđîöĺńńîđîâ JOINj. Äë˙ îáĺńďĺ÷ĺíč˙ íŕäĺćíîé đŕáîňű ńčńňĺěű íŕ âńĺő óđîâí˙ő ďđčěĺíĺíŕ áŕđüĺđíŕ˙ ńčíőđîíčçŕöč˙.
Ďđîăđŕěěíŕ˙ ńčńňĺěŕ. Ďŕđŕëëĺëüíŕ˙ ŃÓÁÄ Clusterixďđĺäńňŕâë˙ĺň ęîěďîçčöčţ ÷ĺňűđĺő ďđîăđŕěěíűő ěîäóëĺé: mlisten, msort, irun, jrun. Ěîäóëü mlistenđĺŕëčçóĺň ôóíęöčţ ëîăč÷ĺńęîăî ďđîöĺńńîđŕ ÓĎĐ, ěîäóëü msort– SORT, ěîäóëü irun– IO, ěîäóëü jrun– JOIN. Ěîäóëč mlisten č msortôóíęöčîíčđóţň íŕ Host. Íŕçíŕ÷ĺíčĺ ěîäóë˙ mlisten: ďîëó÷ĺíčĺ âőîäíîăî çŕďđîńŕ îň ďîëüçîâŕňĺë˙ č ďĺđĺäŕ÷ŕ đĺçóëüňŕňîâ îáđŕáîňęč îáđŕňíî; ďĺđĺńűëęŕ ęîěŕíä óďđŕâëĺíč˙ ěîäóë˙ě irun, jrun, msort; ěîíčňîđčíă đŕáîňű ěîäóëĺé ńčńňĺěű; ńáîđ ńňŕňčńňč÷ĺńęîé číôîđěŕöčč. Ěîäóëü msortďđĺäíŕçíŕ÷ĺí äë˙ âűďîëíĺíč˙ îďĺđŕöčč îáúĺäčíĺíč˙ đĺçóëüňŕňîâ îáđŕáîňęč JOIN ń ďîńëĺäóţůčě âűďîëíĺíčĺě îďĺđŕöčé ŕăđĺăŕöčč č ńîđňčđîâęč đĺçóëüňŕňŕ. Íŕçíŕ÷ĺíčĺ ěîäóë˙ irun – âűďîëíĺíčĺ îďĺđŕöčé ńĺëĺęöčč č ďđîĺęöčč íŕä čńőîäíűěč îňíîřĺíč˙ěč áŕçű äŕííűő. Íŕ ęŕćäîě óçëĺ óđîâí˙ IO đŕńďîëŕăŕĺňń˙ ńâî˙ ńňđŕíčöŕ čńőîäíîé ÁÄ. Íîěĺđ ýňîé ńňđŕíčöű îďđĺäĺë˙ĺňń˙ ňĺęóůĺé ęîíôčăóđŕöčĺé č ďđčńâŕčâŕĺňń˙ ĺé ďđč çŕďóńęĺ ńčńňĺěű. Ďîýňîěó ęŕćäŕ˙ ńňđŕíčöŕ (č ńîîňâĺňńňâóţůčé ĺé ěîäóëü irun) čěĺĺň óíčęŕëüíűé íîěĺđ. Ňî ćĺ – č ń ěîäóëĺě jrun, ęîňîđűé âűďîëí˙ĺň îďĺđŕöčč ńîĺäčíĺíč˙. Ęîëč÷ĺńňâî ěîäóëĺé irunč jrunäë˙ ëţáîé ęîíôčăóđŕöčč îäčíŕęîâî. ×čńëî ôčçč÷ĺńęčő ďđîöĺńńîđîâ, íŕ ęîňîđűő ôóíęöčîíčđóţň ďđîăđŕěěíűĺ ěîäóëč irunč jrun, ěîćĺň áűňü đŕçëč÷íî.
Ěîäĺëčđîâŕíčĺ ďđîöĺńńîâ, ďđîňĺęŕţůčő â Clusterix, âűďîëí˙ëîńü ďđč đŕçíîě ÷čńëĺ óçëîâ ęëŕńňĺđŕ (ôčçč÷ĺńęčő ďđîöĺńńîđîâ) č đŕçíîě đŕńďđĺäĺëĺíčč â íčő ďđîăđŕěěíűő ěîäóëĺé (ëîăč÷ĺńęčő ďđîöĺńńîđîâ). Çäĺńü č äŕëĺĺ ďîí˙ňč˙ «ëîăč÷ĺńęčé ďđîöĺńńîđ» č «ďđîăđŕěěíűé ěîäóëü» (irunčëč jrun) čńďîëüçóţňń˙ ęŕę ńčíîíčěű. Íŕ ęŕćäîě ôčçč÷ĺńęîě ďđîöĺńńîđĺ ěîăóň âűďîëí˙ňüń˙ íĺńęîëüęî ëîăč÷ĺńęčő. Îáůĺĺ ęîëč÷ĺńňâî ôčçč÷ĺńęčő ďđîöĺńńîđîâ â ęëŕńňĺđĺ (âęëţ÷ŕ˙ Host) N=2n+1, ăäĺ n=1,2,… Âĺëč÷číŕ 2n = p+q, p č q – ÷čńëŕ ôčçč÷ĺńęčő ďđîöĺńńîđîâ IO č JOIN.  äŕëüíĺéřĺě ôčăóđčđóĺň čő îňíîřĺíčĺ k = q/p.
Đŕńńěŕňđčâŕëčńü ňđč ňčďŕ ęîíôčăóđŕöčé Clusterix: «ëčíĺéęŕ», «ńčěěĺňđč˙» č «ŕńčěěĺňđč˙».  ęîíôčăóđŕöčč «ëčíĺéęŕ» (ń óńëîâíűě çíŕ÷ĺíčĺě k=0) íŕ ęŕćäîě ôčçč÷ĺńęîě ďđîöĺńńîđĺ ęëŕńňĺđŕ âűďîëí˙ţňń˙ îáŕ ëîăč÷ĺńęčő ďđîöĺńńîđŕ: irunč jrun. Ěîäóëč ôóíęöčîíčđóţň â đĺćčěĺ đŕçäĺëĺíč˙ âđĺěĺíč ďđč óńëîâčč áŕđüĺđíîé ńčíőđîíčçŕöčč. Ńčőđîíčçŕöč˙ âűďîëí˙ĺňń˙ ďĺđĺäŕ÷ĺé ęîđîňęčő ńĺňĺâűő ńîîáůĺíčé č îńóůĺńňâë˙ĺňń˙ ěîäóëĺě mlisten. Ęŕćäűé óçĺë ęëŕńňĺđŕ čěĺĺň óńňđîéńňâî âíĺříĺé ďŕě˙ňč. Äë˙ ęîíôčăóđŕöčč «ńčěěĺňđč˙» őŕđŕęňĺđíŕ đĺŕëčçŕöč˙ ęŕćäîăî ëîăč÷ĺńęîăî ďđîöĺńńîđŕ íŕ îňäĺëüíîě ôčçč÷ĺńęîě ďđîöĺńńîđĺ. Ëţáîěó óçëó, íŕ ęîňîđîě âűďîëí˙ĺňń˙ ěîäóëü irun, ńîîňâĺňńňâóĺň óçĺë ń ěîäóëĺě jrun. ×čńëŕ óçëîâ JOIN č IO îäčíŕęîâű: p=q=n, k=1. Ęîíôčăóđŕöčč «ŕńčěěĺňđč˙» ďđĺäíŕçíŕ÷ĺíŕ äë˙ ěîäĺëčđîâŕíč˙ ňŕęčő íŕăđóçîę, ďđč ęîňîđűő îńíîâíŕ˙ ÷ŕńňü đŕáîň ďđčőîäčňń˙ íŕ óçëű IO. Ďîýňîěó ęîëč÷ĺńňâî ôčçč÷ĺńęčő ďđîöĺńńîđîâ IO áîëüřĺ ďî ńđŕâíĺíčţ ń ÷čńëîě ôčçč÷ĺńęčő ďđîöĺńńîđîâ JOIN. Íŕ ęŕćäîě ôčçč÷ĺńęîě ďđîöĺńńîđĺ JOIN âűďîëí˙ĺňń˙ íĺńęîëüęî ëîăč÷ĺńęčő ďđîöĺńńîđîâ jrun. Čńńëĺäîâŕíč˙ ďîęŕçŕëč, ÷ňî ęîëč÷ĺńňâî ńîâěĺńňíî đŕáîňŕţůčő ëîăč÷ĺńęčő ďđîöĺńńîđîâ jruníŕ îäíîě óçëĺ íĺ äîëćíî ďđĺâűřŕňü ňđĺő. Ďîýňîěó çäĺńü k=1/2, 1/3.
Çŕďđîńű, íŕ ęîňîđűő ďđîâîäčňń˙ ňĺńňčđîâŕíčĺ, đŕçěĺůŕţňń˙ â ńďĺöčŕëüíîě číňĺđôĺéńíîě îňíîřĺíčč queryńčńňĺěíîé áŕçű äŕííűő â îňňđŕíńëčđîâŕííîě âčäĺ äë˙ ęŕćäîăî čç ňđĺő ďđîăđŕěěíűő ěîäóëĺé: irun, jrun č msort. Ďđîăđŕěěŕ-ęëčĺíňŕ ďîńűëŕĺň íîěĺđ SQL-çŕďđîńŕ. Ěîäóëü mlistençŕďóńęŕĺň äë˙ îáđŕáîňęč çŕďđîńŕ ôóíęöčţ-ďîňîę Ďđîöĺńń h, ăäĺ h – ďîđ˙äęîâűé íîěĺđ çŕďđîńŕ â ńčńňĺěĺ. Ďđîöĺńń h ń÷čňűâŕĺň ďŕęĺň ęîěŕíä çŕďđîńŕ čç îňíîřĺíč˙ queryč ďĺđĺäŕĺň ĺăî ńîîňâĺňńňâóţůčě ěîäóë˙ě äë˙ čńďîëíĺíč˙.
Ŕíŕëčç ýęńďĺđčěĺíňŕëüíűő äŕííűő.  ęŕ÷ĺńňâĺ ďđĺäńňŕâčňĺëüńęîăî ňĺńňŕ (ĎŇ) čńďîëüçîâŕëń˙ îăđŕíč÷ĺííűé ňĺńň TPC-H čç 14 çŕďđîńîâ, íĺ ńîäĺđćŕůčő îďĺđŕöčé çŕďčńč. Äŕëĺĺ ďđčâîä˙ňń˙ đĺçóëüňŕňű ěîäĺëüíîăî ýęńďĺđčěĺíňŕ íŕ íŕňóđíîé ěîäĺëč – ŃÓÁÄ Clustrerix, ďîëó÷ĺííűĺ äë˙ äâóő ęëŕńňĺđíűő ďëŕňôîđě [12,13]:
– Ďëŕňôîđěŕ 1. Host – cĺđâĺđ Intel Core 4 Xeon 5320 (2,4 GHz, RAM 4GB). Čńďîëíčňĺëüíűĺ óçëű – 13 ĎĘ Intel Core 2 Duo 6320 (1,87 GHz, RAM 3GB, ćĺńňęčé äčńę SATA 125GB); ëîęŕëüíŕ˙ ńĺňü GigabitEthernet. Íŕ ęŕćäűé ęîěďüţňĺđ óńňŕíîâëĺíŕ îďĺđŕöčîííŕ˙ ńčńňĺěŕ Linux. Âńĺ ďđîöĺńńîđű äîďîëíčňĺëüíî îńíŕůĺíű ŃÓÁÄ MySQL.
– Ďëŕňôîđěŕ 2. Âű÷čńëčňĺëüíűé ęëŕńňĺđ ôčđěű SUN čç 22 óçëîâ 2 Quad-core Intel Xeon E5450 CPU/1,87GHz/32GB. Číňĺđęîííĺęň ěĺćäó óçëŕěč – GigabitEthernet/Infiniband 4X (20Gbps DDR) ń 24-ďîđňîâűěč ęîěěóňŕňîđŕěč Cisco. Äčńęîâŕ˙ ďîäńčńňĺěŕ óçëŕ – SAS äčńęč XRB-SS2CD-146G10KZ ń ďđîďóńęíîé ńďîńîáíîńňüţ 300 ĚB/s. Ęŕę č đŕíĺĺ, – Linux, MySQL.
Íŕ đčń.3a,b ďđčâĺäĺíű ýęńďĺđčěĺíňŕëüíűĺ çŕâčńčěîńňč ďđîčçâîäčňĺëüíîńňč, ďîëó÷ĺííűĺ óńđĺäíĺíčĺě íŕ 5 âŕđčŕíňŕő ďĺđĺńňŕíîâîę çŕďđîńîâ ĎŇ äë˙ ďëŕňôîđěű 1 č đŕçíűő îáúĺěîâ áŕç äŕííűő.
|
a
 Đčń.3. Ńđĺäíĺĺ âđĺě˙ âűďîëíĺíč˙ ĎŇ. Ďëŕňôîđěŕ 1. Đčń.3. Ńđĺäíĺĺ âđĺě˙ âűďîëíĺíč˙ ĎŇ. Ďëŕňôîđěŕ 1.
a) VÁÄ = 1GB; b) VÁÄ = 5,4 GB
|
b

|
Îáîçíŕ÷čě: hG – ăđŕíčöŕ ěŕńřňŕáčđóĺěîńňč ďî ÷čńëó óçëîâ h, mG – ăđŕíč÷íîĺ ÷čńëî ńňđŕíčö. Őŕđŕęňĺđíî, ÷ňî äë˙ ëţáîé ęîíôčăóđŕöčč ďđč h = hG= (1+k)mG ďđîčçâîäčňĺëüíîńňü ęëŕńňĺđŕ âńĺăäŕ ěŕęńčěŕëüíŕ. Ýňó çŕęîíîěĺđíîńňü ďîäňâĺđćäŕţň č đŕíĺĺ ďđîâĺäĺííűĺ čńńëĺäîâŕíč˙ äë˙ ńëó÷ŕ˙ îäíî˙äĺđíűő óçëîâ [14,15]. Çŕěĺňčě, ÷ňî ďŕđŕěĺňđ mGçŕâčńčň îň čńďîëüçóĺěîé ďëŕňôîđěű č, ďđč íĺčçěĺííűő ĎŇ č ńőĺěĺ ÁÄ, đŕńňĺň ń óâĺëč÷ĺíčĺě VÁÄ. Ăđŕíčöŕ ěŕńřňŕáčđóĺěîńňč ěŕęńčěŕëüíŕ äë˙ ńčěěĺňđčč: hGńčě = 2mG. Íî ďĺđĺőîä îň «ëčíĺéęč» ę «ńčěěĺňđčč» ďđč íĺčçěĺííîé íŕăđóçęĺ íĺ ďđčâîäčň ę ńóůĺńňâĺííîěó óâĺëč÷ĺíčţ ěŕęńčěóěŕ ďđîčçâîäčňĺëüíîńňč. Äë˙ ďđčí˙ňîăî ĎŇ ęîíôčăóđŕöč˙ «ëčíĺéęŕ» îęŕçűâŕĺňń˙ íŕčáîëĺĺ ýôôĺęňčâíîé.
Ńëó÷ŕţ 2-ďđîöĺńńîđíűő SMP-óçëîâ îňâĺ÷ŕĺň ďëŕňôîđěŕ 2. Ďî ŕńńîöčŕöčč ń ďđĺäűäóůčě îăđŕíč÷čěń˙ äë˙ íĺĺ čńńëĺäîâŕíčĺě ęîíôčăóđŕöčč «ëčíĺéęŕ». Íŕ đčń.4a ďîęŕçŕí ďîëó÷ĺííűé äë˙ «ëčíĺéęč» ăđŕôčę çŕâčńčěîńňč âđĺěĺíč T (ńĺę.) âűďîëíĺíč˙ ĎŇ îň ÷čńëŕ đŕáî÷čő óçëîâ ęëŕńňĺđŕ (h) â ńëó÷ŕĺ VÁÄ =5,4GB . Âčäčěűé ďîđîă ěŕńřňŕáčđóĺěîńňč hG =7-8.
Íŕëč÷čĺ äâóő ďđîöĺńńîđîâ â óçëĺ ďîçâîë˙ĺň ńóůĺńňâĺííî óëó÷řčňü ěŕńřňŕáčđóĺěîńňü «ëčíĺéęč» č ďîâűńčňü ĺĺ ěŕęńčěŕëüíîĺ áűńňđîäĺéńňâčĺ íŕ ăđŕíčöĺ ěŕńřňŕáčđóĺěîńňč. Ýňî äîńňčăŕĺňń˙ óńňŕíîâęîé íŕ ęŕćäűé SMP-óçĺë âű÷čńëčňĺëüíîăî ęëŕńňĺđŕ äâóő ńĺđâĺđîâ MySQL. Îäčí čç íčő ńâ˙çŕí ń ďđîöĺńńŕěč IO, äđóăîé – ń ďđîöĺńńŕěč Join.  čňîăĺ ďî˙âë˙ĺňń˙ ĺůĺ îäíŕ ęîíôčăóđŕöč˙, íŕçâŕííŕ˙ «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙». Äë˙ ńđŕâíĺíč˙ ďđîčçâîäčňĺëüíîńňč ęîíôčăóđŕöčé «ëčíĺéęŕ» č «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙» ďđč đŕçíîě ÷čńëĺ óçëîâ ďđîâĺäĺíŕ îáđŕáîňęŕ ďîńëĺäîâŕňĺëüíîńňč çŕďđîńîâ ęŕę ęîíęŕňĺíŕöčč ňđĺő ďĺđĺńňŕíîâîę ĎŇ. Ďîëó÷ĺííűĺ đĺçóëüňŕňű ďđĺäńňŕâëĺíű íŕ đčń.4b. Ňđîéíîĺ óâĺëč÷ĺíčĺ äëčíű č ńîîňâĺňńňâóţůĺĺ čçěĺíĺíčĺ őŕđŕęňĺđčńňčęč âíĺříĺé íŕăđóçęč íîâîăî ňĺńňŕ ďđčâĺëî ę ńíčćĺíčţ âĺëč÷číű hG äë˙ «ëčíĺéęč» ń 7 äî 5. Ęîíôčăóđŕöč˙ «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙» ďîęŕçűâŕĺň hG = 7 ń ďŕäĺíčĺě Tmin íŕ 25% â ńđŕâíĺíčč ń «ëčíĺéęîé».
|
a

Đčń. 4. Ďëŕňôîđěŕ 2, VÁÄ = 5,4GB
a) äĺéńňâčĺ ĎŇ; b) ęîíęŕňĺíŕöč˙ 3-ő ďĺđĺńňŕíîâîę ĎŇ
|
b

|
 ďđîöĺńńĺ čńńëĺäîâŕíčé ęîíôčăóđŕöčč «ëčíĺéęŕ» äîďîëíčňĺëüíî óńňŕíîâëĺíű [16] ôŕęňű: 1) çíŕ÷čňĺëüíîăî («â đŕçű») âđĺěĺííîăî äîěčíčđîâŕíč˙ çŕäĺđćĺę áŕđüĺđíîé ńčíőđîíčçŕöčč íŕä âńĺěč äđóăčěč çŕäĺđćęŕěč â ńčńňĺěĺ âáëčçč ďîđîăŕ ěŕńřňŕáčđóĺěîńňč; 2) đĺçęîăî íŕđŕńňŕíč˙ çŕäĺđćĺę íŕ âńĺő ýňŕďŕő îáđŕáîňęč ďđč h ≈ 1,5mG; 3) ęđčňč÷íîńňč ńčńňĺěű ę čńďîëüçîâŕíčţ ÷đĺçěĺđíîăî ÷čńëŕ óçëîâ â ńâ˙çč ń đîńňîě ďîđîăŕ ěŕńřňŕáčđóĺěîńňč ďđč óâĺëč÷ĺíčč îáúĺěîâ îáđŕáŕňűâŕĺěűő áŕç äŕííűő. Číňĺíńčâíŕ˙ äčíŕěč÷ĺńęŕ˙ ńĺăěĺíňŕöč˙ ďđč ÷đĺçěĺđíîě đîńňĺ h ďđčâîäčň ę ďĺđĺăđóçęĺ ďî číňĺđęîííĺęňó č, ęŕę ńëĺäńňâčĺ, ę «çŕâčńŕíčţ» ńčńňĺěű. 2. Ěóëüňčęëŕńňĺđčçŕöč˙ Ďĺđĺőîä ę ěóëüňčęëŕńňĺđčçŕöčč, ęîăäŕ íŕ îäíîě äîńňŕňî÷íî ěîůíîě âű÷čńëčňĺëüíîě ęëŕńňĺđĺ đĺŕëčçóĺňń˙ ěíîćĺńňâî îäíîâđĺěĺííî đŕáîňŕţůčő ŃÓÁÄ Clusterix ń đĺďëčęŕöčĺé ěĺćäó íčěč ęîíńĺđâŕňčâíîé áŕçű äŕííűő, äîëćĺí ńďîńîáńňâîâŕňü đîńňó ďđîčçâîäčňĺëüíîńňč ńčńňĺěű â öĺëîě. Ňŕęîé ďĺđĺőîä îçíŕ÷ŕĺň čçěĺíĺíčĺ čäĺîëîăčč îáđŕáîňęč çŕďđîńîâ â ęëŕńňĺđíîé ńčńňĺěĺ: îň «ěíîćĺńňâŕ ěŕëîěîůíűő óçëîâ íŕ îäčí çŕďđîń» ę îäíîěó ěîůíîěó óçëó íŕ ęŕćäűé çŕďđîń». Ďđč ýňîě «ěîůíűé óçĺë» đĺŕëčçóĺňń˙ ęŕę ěîíîęëŕńňĺđ – ęîěďîíĺíň ęëŕńňĺđŕ â öĺëîě ń óńňŕíîâęîé íŕ íĺăî ńčńňĺěű Clusterix. ×čńëî óçëîâ ěîíîęëŕńňĺđŕ îňâĺ÷ŕĺň ăđŕíč ěŕńřňŕáčđóĺěîńňč.
Čńńëĺäîâŕíčĺ âîďđîńîâ ěóëüňčęëŕcňĺđčçŕöčč ďđîâîäčëîńü íŕ ěîäčôčöčđîâŕííîé íŕňóđíîé ěîäĺëč – ŃÓÁÄ Clusterix-M [13]. Host (ăëŕâíŕ˙ ÝÂĚ) âęëţ÷ŕĺň ěîäóëü ROUTER, ęîňîđűé đŕńďđĺäĺë˙ĺň ďîňîę çŕďđîńîâ, ďîńňóďŕţůčő îň N ęëčĺíňîâ ěĺćäó n ěîíîęëŕńňĺđŕěč-ęîěďîíĺíňŕěč. Ďîääĺđćčâŕţňń˙ äâŕ âčäŕ î÷ĺđĺäĺé çŕďđîńîâ – âíóňđĺííčő(â ěîíîęëŕńňĺđŕő) č âíĺříĺé(â ROUTER). Ďî óńëîâčţ çŕďđîń íĺ ďîęčäŕĺň ńâîĺé î÷ĺđĺäč äî îęîí÷ŕíč˙ ĺăî îáđŕáîňęč. Î÷ĺđĺäíîé çŕďđîń îň ęŕćäîăî ďîëüçîâŕňĺë˙ ďîńňóďŕĺň íŕ âőîä ńĺđâĺđŕ ŃÓÁÄ ńđŕçó, ęŕę áóäĺň ďîëó÷ĺí îňâĺň íŕ ďđĺäűäóůčé çŕďđîń. Ďîýňîěó â ëţáîé ěîěĺíň âđĺěĺíč ńóěěŕđíîĺ ÷čńëî çŕďđîńîâ L, íŕőîä˙ůčőń˙ â ńĺđâĺđĺ, L = N. Ńóěěŕđíŕ˙ äëčíŕ âńĺő âíóňđĺííčő î÷ĺđĺäĺé Ɩn= r∙n ≤ N, r≥1. Äëčíŕ âíĺříĺé î÷ĺđĺäč L–Ɩn ≥ 0.
Îńíîâíŕ˙ çŕäŕ÷ŕ áŕëŕíńčđîâęč íŕăđóçęč â ěóëüňčęëŕńňĺđĺ ńîńňîčň â íŕőîćäĺíčč ňŕęîăî ńďîńîáŕ đŕńďđĺäĺëĺíč˙ çŕďđîńîâ ěĺćäó ěîíîęëŕńňĺđŕěč, ęîňîđűé ěčíčěčçčđóĺň (â ńđĺäíĺě) âđĺě˙ îćčäŕíč˙ îňâĺňŕ íŕ âíîâü ďîńňóďčâřčé çŕďđîń č đŕçáđîń ýňîăî âđĺěĺíč. Ęđóăîâîĺ đŕńďđĺäĺëĺíčĺ – íŕčáîëĺĺ ďđîńňîé č, ęŕę ďîęŕçŕëč čńńëĺäîâŕíč˙, äîńňŕňî÷íî ýôôĺęňčâíűé ěĺňîä áŕëŕíńčđîâęč íŕăđóçęč ěóëüňčęëŕńňĺđŕ. Ďđčí˙ňîĺ íŕçâŕíčĺ îá-óńëîâëĺíî ňĺě, ÷ňî ďĺđâűĺ Ɩn çŕďđîńîâ đŕńďđĺäĺë˙ţňń˙ ďî ěîíîęëŕńňĺđŕě-ęîěďîíĺíňŕě â ďîđ˙äęĺ ěĺńň, çŕíčěŕĺěűő čěč â îáđŕáŕňűâŕĺěîé ďîńëĺäîâŕňĺëüíîńňč:
|
Ɩn–n+1
|
Ɩn–n+2
|
- - -
|
Ɩn
|
← r- çŕďđîńű
|
|
- - -
|
- - -
|
- - -
|
|
- - -
|
|
+1
|
n+2
|
- - -
|
|
2n
|
|
1
|
2
|
- - -
|
n
|
←1-çŕďđîńű
|
 äŕëüíĺéřĺě âń˙ęčé đŕç ďîďîëí˙ĺňń˙ ňŕ čç âíóňđĺííčő î÷ĺđĺäĺé, ęîňîđŕ˙ ďĺđâîé çŕâĺđřčëŕ îáđŕáîňęó ńâîĺăî 1-çŕďđîńŕ. Ń÷čňŕĺňń˙, ÷ňî â ďđîöĺńńĺ đŕáîňű ńčńňĺěű çíŕ÷ĺíčĺ Ɩn íĺčçěĺííî. Ďî îęîí÷ŕíčč îáđŕáîňęč ëţáîăî 1-çŕďđîńŕ îńâîáîäčâřĺĺń˙ ěĺńňî çŕíčěŕĺň î÷ĺđĺäíîé çŕďđîń čç âíĺříĺé î÷ĺđĺäč. Č â ňîň ćĺ ěîěĺíň íŕ âőîä ŃÓÁÄ ďîńňóďŕĺň íîâűé çŕďđîń. Ďđîâĺäĺííűěč čńńëĺäîâŕíč˙ěč óńňŕíîâëĺíî, ÷ňî íŕčëó÷řĺĺ đĺřĺíčĺ ńôîđěóëčđîâŕííîé đŕíĺĺ çŕäŕ÷č áŕëŕíńčđîâęč íŕăđóçęč ěóëüňčęëŕńňĺđŕ ęđóăîâűě ńďîńîáîě îáĺńďĺ÷čâŕĺň âűáîđ çíŕ÷ĺíč˙ r = 2.
Ďđĺčěóůĺńňâŕ ěóëüňčęëŕńňĺđčçŕöčč ďîäňâĺđćäŕţň đĺçóëüňŕňű ďđîâĺäĺííîăî ńđŕâíčňĺëüíîăî ňĺńňčđîâŕíč˙ đŕâíîńëîćíűő îäíîęëŕńňĺđíűő č ěíîăîęëŕńňĺđíűő ŕđőčňĺęňóđ íŕ ďëŕňôňîđěŕő 1 č 2 (ńě. đŕçäĺë 1). Ýęńďĺđčěĺíň ďđîâîäčňń˙ íŕ ňĺńňîâűő áŕçŕő äŕííűő îáúĺěŕěč VÁÄ = 1GB č 5,4GB. Äë˙ îáĺčő ďëŕňôîđě â ńëó÷ŕĺ ěóëüňčęëŕńňĺđŕ çŕďđîńű đŕńďđĺäĺë˙ëčńü ěĺćäó ěîíîęëŕńňĺđŕěč ďî «ęđóăîâîěó» ŕëăîđčňěó ńî çíŕ÷ĺíčĺě ďŕđŕěĺňđŕ r = 2. Ďîäńčńňĺěîé ńáîđŕ ńňŕňčńňč÷ĺńęîé číôîđěŕöčč ŃÓÁÄ Clusterix ôčęńčđîâŕëîńü ńđĺäíĺĺ âđĺě˙ T âűďîëíĺíč˙ ĎŇ ďî ď˙ňč ĺăî ďĺđĺńňŕíîâęŕě. Ńíŕ÷ŕëŕ îáđŕáŕňűâŕëŕńü áŕçŕ äŕííűő îáúĺěîě 1GB íŕ ďëŕňôîđěĺ 1. Ěîíîęëŕńňĺđű ěóëüňčęëŕńňĺđíîé ŕđőčňĺęňóđű ęîíôčăóđčđîâŕëčńü ęŕę «ëčíĺéęŕ» ń ÷čńëîě óçëîâ hĚ ≅ hG=3 (ńě. đčń.3a). Đĺçóëüňŕňű ňĺńňčđîâŕíč˙ ďîęŕçŕíű íŕ đčń.5a. Ďđč ďĺđĺőîäĺ îň îäíîęëŕńňĺđíîé ŕđőčňĺęňóđű ę đŕâíîńëîćíîé ěóëüňčęëŕńňĺđíîé ďîâűřŕĺňń˙ č ěŕńřňŕáčđóĺěîńňü, č ďđîčçâîäčňĺëüíîńňü.
Çŕňĺě äë˙ ďëŕňôîđěű 2 áűëŕ ďđîâĺäĺíŕ îáđŕáîňęŕ ďîńëĺäîâŕňĺëüíîńňč ęŕę ęîíęŕňĺíŕöčč ňđĺő ďĺđĺńňŕíîâîę çŕďđîńîâ ĎŇ ń îáúĺěîě áŕçű äŕííűő 5,4GB (đčń.5b). Ěîíîęëŕńňĺđű-ęîěďîíĺíňű ęîíôčăóđčđîâŕëčńü ęŕę «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙», ÷ĺěó ńîîňâĺňńňâóĺň hG=7 (đčń.4b). Âŕđüčđîâŕëîńü ęîëč÷ĺńňâî ěîíîęëŕńňĺđîâ n č ÷čńëî čő óçëîâ hm.  ńëó÷ŕĺ hm= 4 íŕáëţäŕëń˙ đîńň ěŕńřňŕáčđóĺěîńňč ěóëüňčęëŕńňĺđŕ ďî ńđŕâíĺíčţ ń îäíîęëŕńňĺđíîé ńčńňĺěîé â 2,3 đŕçŕ; ďđč hĚ = 6 – áîëĺĺ ÷ĺě â 2,6 đŕç. Ńňĺďĺíü đîńňŕ ďđîčçâîäčňĺëüíîńňč íŕ ďîđîăĺ ěŕńřňŕáčđóĺěîńňč – â 2,4 č íĺ ěĺíĺĺ ÷ĺě â 3 đŕçŕ ńîîňâĺňńňâĺííî.
|
a

Đčń.5. Ňĺńňčđîâŕíčĺ ďđîčçâîäčňĺëüíîńňč ěóëüňčęëŕńňĺđŕ
a) ďëŕňôîđěŕ 1; b) ďëŕňôîđěŕ 2
|
b

|
3. Îäčí óçĺë ęëŕńňĺđŕ íŕ ěíîćĺńňâî çŕďđîńîâ Äî ńčő ďîđ ďđč đŕáîňŕő ń áŕçŕěč äŕííűő ěŕëî čńďîëüçóĺňń˙ âű÷čńëčňĺëüíűé ďîňĺíöčŕë ńîâđĺěĺííűő ěíîăî˙äĺđíűő ďđîöĺńńîđîâ. Ďđčěĺđîě ěîăóň ńëóćčňü đŕńńěîňđĺííűĺ đĺŕëčçŕöčč ŃÓÁÄ Clusterixč Clusterix-M íŕ SUN-ęëŕńňĺđĺ ń ěíîăî˙äĺđíűěč óçëŕěč. Čńďîëüçîâŕíčĺ ňŕęčő óçëîâ ďîçâîë˙ĺň ďî číîěó ďîäîéňč ę đĺřĺíčţ ďđîáëĺěű ńîçäŕíč˙ ěîůíîăî óçëŕ íŕ îńíîâĺ ňĺőíîëîăčč MySQL (ëčáî PostgreSQL). Ńŕěîńňî˙ňĺëüíîĺ ďđčěĺíĺíčĺ ŃÓÁÄ MySQL ďîńëĺäíčő âĺđńčé ďîçâîë˙ĺň ďîëíîńňüţ čńďîëüçîâŕňü đĺńóđńű ěíîăî˙äĺđíűő óçëîâ ń đĺŕëčçŕöčĺé ěîíîęëŕńňĺđŕ íŕ îäíîě óçëĺ (ńňđŕňĺăč˙ «îäčí óçĺë ęëŕńňĺđŕ íŕ ěíîćĺńňâî çŕďđîńîâ»).  đŕáîňĺ [17] óäŕëîńü îáĺńďĺ÷čňü 100% çŕăđóçęó âńĺő ˙äĺđ ďđč ńďĺöčŕëüíîé íŕńňđîéęĺ MySQL 5.6.
Ďîëó÷ĺííűé íŕ ďëŕňôîđěĺ 2 ďđč íîâűő óńëîâč˙ő ýęńďĺđčěĺíňŕ (ĎŇ – ńëó÷ŕéíŕ˙ ďîńëĺäîâŕňĺëüíîńňü čç 800 çŕďđîńîâ íŕ ěíîćĺńňâĺ çŕďđîńîâ îăđŕíč÷ĺííîăî ňĺńňŕ TPC-H), îďđĺäĺëĺííîé đîóňĺđčçŕöčč â óçëĺ č îăđŕíč÷ĺíčč VÁÄ đŕçěĺđŕěč îďĺđŕňčâíîé ďŕě˙ňč ÎĎ óçëŕ (âń˙ ÁÄ őđŕíčňń˙ â ÎĎ) ăđŕôčę çŕâčńčěîńňč âđĺěĺíč âűďîëíĺíč˙ ĎŇ â ěčíóňŕő îň ęîëč÷ĺńňâŕ óçëîâ â ńčńňĺěĺ ďîęŕçŕí íŕ đčń.6.

Đčń.6. Ăđŕôčę ńđĺäíĺăî âđĺěĺíč âűďîëíĺíč˙ ĎŇ
Íŕáëţäŕĺňń˙ ńíčćĺíčĺ Tminíŕ 25% â ńđŕâíĺíčč ń ęîíôčăóđŕöčĺé «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙» (đčń.4b) ďđč íĺčçěĺííîě hG=7, ďđĺćíĺě VÁÄ = 5,4 GB č áîëĺĺ ÷ĺě íŕ ďîđ˙äîę áîëüřĺě ÷čńëĺ îáđŕáŕňűâŕĺěűő çŕďđîńîâ. Íî ďđč çíŕ÷čňĺëüíűő VÁÄ >VÎĎ ňŕęîé ďîäőîä óćĺ íĺďđčěĺíčě. Çäĺńü, ŕíŕëîăč÷íî Clusterix, íĺîáőîäčěî ďđčěĺí˙ňü őĺřčđîâŕíčĺ ÁÄ íŕ ěíîćĺńňâĺ óçëîâ ęëŕńňĺđŕ ń čńďîëüçîâŕíčĺě đĺăóë˙đíîăî ďëŕíŕ áđŕáîňęč çŕďđîńîâ. 4. Ďđčěĺíĺíčĺ ăđŕôč÷ĺńęčő óńęîđčňĺëĺé Ăđŕôč÷ĺńęčĺ óńęîđčňĺëč (GPU) óćĺ ďđčěĺí˙ţňń˙ äë˙ óńęîđĺíč˙ đŕáîňű ŃÓÁÄ CoGaDb [18], ęŕę đŕńřčđĺíčĺ PG-Storm äë˙ Postgres [19] č äđ. Čńďîëüçîâŕíčĺ GPU ďîçâîë˙ĺň ńóůĺńňâĺííî ńíčçčňü âđĺě˙ âűďîëíĺíč˙ îňäĺëüíűő îďĺđŕöčé. Ďđč VÁÄ ≤ 3GB âń˙ ÁÄ ěîćĺň őđŕíčňüń˙ â ăëîáŕëüíîé ďŕě˙ňč GPU (6GB äë˙ GPU Fermi). Ňîăäŕ âűďîëíĺíčĺ ńĺđâčńíűő ôóíęöčé (ďđčĺě çŕďđîńîâ, čő ńčíňŕęńč÷ĺńęčé ŕíŕëčç č äđ.) âîçëŕăŕĺňń˙ íŕ CPU, ŕ îáđŕáîňęîé çŕďđîńîâ áóäĺň çŕíčěŕňüń˙ ňîëüęî GPU. Ýôôĺęňčâíîńňü ňŕęîé ŃÓÁÄ ěîćĺň áűňü äîńňŕňî÷íî âűńîęŕ. Ďđč çíŕ÷čňĺëüíűő VÁÄ íĺîáőîäčěîńňü îáěĺíŕ äŕííűěč ń GPU ńóůĺńňâĺííî ńíčćŕĺň ďđîčçâîäčňĺëüíîńňü. Ńęîđîńňü ďĺđĺäŕ÷č äŕííűő ďî řčíĺ PCI-e çíŕ÷čňĺëüíî íčćĺ, ÷ĺě ńęîđîńňü îáěĺíŕ ń îďĺđŕňčâíîé ďŕě˙ňüţ. Ňŕę, ńęîđîńňü ÷ňĺíč˙/çŕďčńč äë˙ 3-ęŕíŕëüíîé îďĺđŕňčâíîé ďŕě˙ňč ňčďŕ DDR3-1600 ńîńňŕâë˙ĺň 38,4 GB/s [20], â ňî âđĺě˙ ęŕę äë˙ řčíű PCI-e 2.0x16 – 6,4 GB/s [21]. Čěĺííî ďî ýňîé ďđč÷číĺ äîńňčăíóňűé â [22] đîńň ďđîčçâîäčňĺëüíîńňč ńĺđâĺđŕ ÁÄ îň čńďîëüçîâŕíč˙ GPU ďđč îáđŕáîňęĺ äîńňŕňî÷íî ďđîńňűő îäčíî÷íűő çŕďđîńîâ íĺ ďđĺâűńčë 40%. Äŕëĺĺ đŕńńěŕňđčâŕĺňń˙ âîçěîćíűé ďîäőîä ę čńďîëüçîâŕíčţ GPU-ŕęńĺëĺđŕňîđîâ íŕ óđîâíĺ IO â ńëó÷ŕĺ őđŕíĺíč˙ đŕńďđĺäĺëĺííîé áŕçű äŕííűő â îďĺđŕňčâíîé ďŕě˙ňč óçëîâ â ńćŕňîě âčäĺ, ďĺđĺäŕ÷č ďî ńĺňč ńćŕňűő îňíîřĺíčé Ri' č âîçěîćíî ěŕęńčěŕëüíîé çŕăđóçęĺ ˙äĺđ ěíîăî˙äĺđíîăî ďđîöĺńńîđŕ íŕ óđîâíĺ JOIN ń ďđčěĺíĺíčĺě â íĺě GPU-ŕęńĺëĺđŕöčč äë˙ đŕçćŕňč˙ ďîńňóďŕţůčő äŕííűő.
Ńćŕňčĺ áŕç äŕííűő. Ńćŕňŕ˙ áŕçŕ äŕííűő ńîőđŕí˙ĺňń˙ â îďĺđŕňčâíîé ďŕě˙ňč óçëŕ. Đŕçćŕňčĺ äŕííűő âíîńčň äîďîëíčňĺëüíóţ çŕäĺđćęó â îáđŕáîňęó äŕííűő íŕ GPU. Ýňŕ çŕäĺđćęŕ ÷ŕńňč÷íî íčâĺëčđóĺň âűčăđűř âî âđĺěĺíč ďĺđĺäŕ÷č. Đŕçëč÷ŕţň ŃÓÁÄ, îđčĺíňčđîâŕííűĺ íŕ őđŕíĺíčĺ äŕííűő ďî ńňđîęŕě č ďî ńňîëáöŕě. Ëó÷řčĺ ďîęŕçŕňĺëč ďî ńćŕňčţ čěĺţň ŃÓÁÄ âňîđîăî ňčďŕ. Ýňîň âîďđîń äĺňŕëüíî čńńëĺäîâŕí â [23]. Ńćŕňŕ˙ áŕçŕ äŕííűő đŕçäĺëĺíŕ íŕ áëîęč. Ďîä áëîęîě äŕííűő äŕëĺĺ ďîíčěŕĺňń˙ ÷ŕńňü ńćŕňîăî ńňîëáöŕ (ëčáî íŕáîđ «ęîđîňęčő» ńňîëáöîâ) ń îáúĺěîě đŕçćŕňűő äŕííűő, đŕâíűě îáúĺěó áóôĺđŕ đŕçćŕňűő äŕííűő GPU. Ŕëăîđčňě ďîäăîňîâęč äŕííűő äë˙ ńćŕňč˙ ńëĺäóţůčé:
1. Íŕéňč ńŕěîĺ «äëčííîĺ» ďîëĺ (äëčíîé RS) â îáđŕáŕňűâŕĺěîě îňíîřĺíčč R.
2. Íŕéňč â ńîîňâĺňńňâóţůĺě ńňîëáöĺ (ńňîëáöŕő) ęîëč÷ĺńňâî çŕďčńĺé RC, ęîňîđîĺ ăŕđŕíňčđîâŕííî óěĺůŕĺňń˙ â îňâĺäĺííîé ďŕě˙ňč, RC=[BS/RS], ăäĺ BS – îáúĺě ďŕě˙ňč, îňâĺäĺííîé äë˙ đŕçćŕňűő äŕííűő â ăđŕôč÷ĺńęîě óńęîđčňĺëĺ.
3. Âűäŕâŕňü čç îňíîřĺíč˙ R äŕííűĺ ďî ńňîëáöŕě äë˙ ńćŕňč˙ ń řŕăîě RC.
Ďî óńëîâčţ ę ęŕćäîěó IO-óçëó ďî řčíĺ PCI-e ďîäęëţ÷ŕţňń˙ 2 ăđŕôč÷ĺńęčő ďđîöĺńńîđŕ GPU 1 č GPU 2. Çŕďđîń ďîńňóďŕĺň â ńčńňĺěó «đŕçáčňűě» íŕ ďîäçŕďđîńű ńîăëŕńíî đĺăóë˙đíîěó ďëŕíó îáđŕáîňęč (ńě. đŕíĺĺ). Äë˙ ęŕćäîé ňŕáëčöű, ó÷ŕńňâóţůĺé â îáđŕáîňęĺ, ďđîĺöčđóĺňń˙ íŕáîđ ęîëîíîę, íĺîáőîäčěűő äë˙ âűďîëíĺíč˙ îďĺđŕöčé «select».  ăđŕôč÷ĺńęčĺ óęîđčňĺëč GPU 1 č GPU 2 ďî-áëî÷íî ďîńëĺäîâŕňĺëüíî ďĺđĺäŕţňń˙ ęîëîíęč îäíîé ňŕáëčöű. Ďîęŕ âűďîëí˙ĺňń˙ đŕńćŕňčĺ, ńĺëĺęňčđîâŕíčĺ îäíîăî áëîęŕ č ĺăî ńćŕňčĺ â GPU 1, ńëĺäóţůčé áëîę ďĺđĺäŕĺňń˙ â GPU 2 č íŕîáîđîň. Ńćŕňűĺ đĺçóëüňŕňű âîçâđŕůŕţňń˙ â őîńň-ďŕě˙ňü. Č ňŕę äë˙ âńĺő îňíîřĺíčé, ó÷ŕńňâóţůčő â îáđŕáîňęĺ ęŕćäîăî çŕďđîńŕ.
Áűë ďđîâĺäĺí ýęńďĺđčěĺíň ń öĺëüţ ńđŕâíĺíč˙ âđĺěĺí, çŕňđŕ÷čâŕĺěűő íŕ ďđîńňîĺ ęîďčđîâŕíčĺ, ń ńóěěîé âđĺěĺí, íĺîáőîäčěűő äë˙ ęîďčđîâŕíč˙ äŕííűő, ńćŕňűő ďî ŕëăîđčňěó RLE (Run Length Encoding) [24], č čő đŕçćŕňč˙ â GPU. Ýęńďĺđčěĺíň ďđîâîäčëń˙ íŕ áŕçĺ âű÷čńëčňĺëüíîăî óçëŕ ń ńëĺäóţůčěč őŕđŕęňĺđčńňčęŕěč: Quad-core Intel Core i5-4670K CPU/2,5GHz/ 24GB RAM (DDR3-1600 â äâóőęŕíŕëüíîě đĺćčěĺ), 64-áčňíŕ˙ ÎŃ Windows 10, äčńęîâŕ˙ ďîäńčńňĺěŕ óçëŕ – SSD SV300S37A/ 120GB ń ďđîďóńęíîé ńďîńîáíîńňüţ 450 ĚB/s, GPU – Nvidia GTX 770 (ń îáúĺěîě ďŕě˙ňč 2GB GDDR5).
Íŕčáîëüřŕ˙ ýôôĺęňčâíîńňü ďĺđĺäŕ÷č äŕííűő áűëŕ äîńňčăíóňŕ äë˙ ęîýôôčöčĺíňŕ ńćŕňč˙ K = 4-5. Ďđč áóëüřĺě ńćŕňčč óâĺëč÷čâŕĺňń˙ âđĺě˙ đŕçćŕňč˙ äŕííűő, ęîňîđîĺ ěîćĺň ďđĺâűńčňü âđĺě˙ îáű÷íîăî ęîďčđîâŕíč˙.  ňŕáë.1 ďîęŕçŕí ďđîöĺíň óâĺëč÷ĺíč˙ ýôôĺęňčâíîńňč ďĺđĺäŕ÷č ńćŕňűő äŕííűő (K = 4 č 5) ń ďîńëĺäóţůčě đŕçćŕňčĺě ďî ńđŕâíĺíčţ ń ďđîńňűě ęîďčđîâŕíčĺě. Ęŕę âčäíî čç ňŕáëčöű, ďđč ďĺđĺäŕ÷ĺ íĺáîëüřîăî îáúĺěŕ äŕííűő ďđîńňîĺ ęîďčđîâŕíčĺ îęŕçűâŕĺňń˙ áűńňđĺĺ. Ďđč îáúĺěŕő >12 Ěáŕéň ďđĺäâŕđčňĺëüíîĺ ńćŕňčĺ äŕĺň óńęîđĺíčĺ â îęđĺńňíîńňč 30% (ďđčěĺđíî â 1,5 đŕçŕ). Äë˙ ńîňĺí Ěáŕéň ěîćíî îćčäŕňü óńęîđĺíčĺ äî 40%.
Ňŕáëčöŕ 1. Čçěĺíĺíčĺ ýôôĺęňčâíîńňč ďĺđĺäŕ÷č äŕííűő
|
Đŕçěĺđ (Ěáŕéň)
|
Ęîďčđîâŕíčĺ, ěń
|
Ęîďčđîâŕíčĺ č âîńńňŕíîâëĺíčĺ ńćŕňîé číôîđěŕöčč, ěń
|
Óâĺëč÷ĺíčĺ ýôôĺęňčâíîńňč ďĺđĺäŕ÷č, %
|
|
K = 4
|
K = 5
|
K = 4
|
K = 5
|
|
0,38
|
1
|
4
|
4
|
-300%
|
-300%
|
|
4,20
|
3
|
6
|
8
|
-167%
|
-100%
|
|
8,01
|
5
|
9
|
9
|
-80%
|
-80%
|
|
11,83
|
7
|
12
|
12
|
-71%
|
-71%
|
|
15,64
|
21
|
15
|
15
|
29%
|
29%
|
|
19,45
|
26
|
20
|
19
|
27%
|
23%
|
|
23,27
|
31
|
23
|
24
|
23%
|
26%
|
|
27,08
|
35
|
26
|
27
|
23%
|
26%
|
|
30,90
|
41
|
30
|
29
|
29%
|
27%
|
|
34,71
|
45
|
35
|
32
|
29%
|
22%
|
|
38,53
|
50
|
35
|
35
|
30%
|
30%
|
|
42,34
|
55
|
38
|
38
|
31%
|
31%
|
|
46,16
|
59
|
41
|
42
|
29%
|
31%
|
|
49,97
|
64
|
44
|
44
|
31%
|
31%
|
|
53,79
|
68
|
48
|
48
|
29%
|
29%
|
|
57,60
|
75
|
50
|
51
|
32%
|
33%
|
|
61,42
|
80
|
53
|
53
|
34%
|
34%
|
Ńđŕâíčňĺëüíűĺ îöĺíęč âđĺěĺíč âűďîëíĺíč˙ îďĺđŕöčé «select-project» č «join». Čńďîëüçóĺňń˙ ďđĺćí˙˙ ďëŕňôîđěŕ, íî áĺç GPU.  ęŕ÷ĺńňâĺ číńňđóěĺíňŕëüíîé áűëŕ âűáđŕíŕ ŃÓÁÄ MySQL 5.7. Äë˙ çŕďđîńîâ ďđĺćíĺăî ĎŇ áűëč ńôîđěčđîâŕíű çŕăđóçî÷íűĺ ěîäóëč «select-project» (ďî ęŕćäîěó Ri) č «join» (ďî ęŕćäîěó çŕďđîńó â öĺëîě). Ďđč ýňîě âńĺ îďĺđŕöčč «project» áűëč «îďóůĺíű âíčç». Îáúĺě ňĺńňîâîé ÁÄ ńîńňŕâčë 1GB. Îíŕ ďđĺäâŕđčňĺëüíî çŕăđóćŕëŕńü â îďĺđŕňčâíóţ ďŕě˙ňü. Ńđŕâíčâŕëčńü âđĺěĺíŕ, çŕňđŕ÷čâŕĺěűĺ íŕ đĺŕëčçŕöčţ âńĺő îďĺđŕöčé «select-project» č ĺäčíîé ďđîöĺäóđű «join» ďî ęŕćäîěó çŕďđîńó ĎŇ (ńě. íčćĺ; ĺĺ ďîńëĺäîâŕňĺëüíîĺ âűďîëíĺíčĺ ńîăëŕńíî đĺăóë˙đíîěó ďëŕíó đčń.1 îęŕçűâŕĺňń˙ âäâîĺ ěĺäëĺííĺĺ), ńî âđĺěĺíŕěč ń âűďîëíĺíčĺě ýňčő çŕďđîńîâ â öĺëîě ŃÓÁÄ MySQL 5.7. Ýňŕ ďđîöĺäóđŕ âűďîëí˙ëŕńü ďî ńëĺäóţůĺěó ŕëăîđčňěó:
- Ńîçäŕíčĺ ďđîěĺćóňî÷íűő îňíîřĺíčé â ďŕě˙ňč MySQL äë˙ őđŕíĺíč˙ đĺçóëüňŕňŕ «select-project».
- Číäĺęńŕöč˙ ďđîěĺćóňî÷íűő îňíîřĺíčé.
- Âűďîëíĺíčĺ îďĺđŕöčč R1′join (join R2′(join R3′( … ))) … ).
Ďîëó÷ĺííűĺ đĺçóëüňŕňű ďđĺäńňŕâëĺíű â ňŕáë.2
Ňŕáëčöŕ 2. Ńđŕâíĺíčĺ âđĺěĺí íŕ đĺŕëčçŕöčţ ďî-îňäĺëüíîńňč îďĺđŕöčé «select-project», «join»č çŕďđîńŕ â öĺëîě
|
ą çŕ- ďđîńŕ
|
Âđĺě˙ îáđŕáîňęč çŕďđîńŕ, ńĺę
|
Îňíîřĺíčĺ âđĺěĺí îáđŕáîňęč
|
|
Îđčăčíŕëüíîăî çŕďđîńŕ
|
Âűďîëíĺíčĺ «select-project»
|
Číäĺęńŕöč˙ đĺç-ňŕ
«select-project»
|
Âűďîëíĺíčĺ «join»
|
tΣjoin
|
|
|
tîáů
|
tΣσ,π
|
tčíä
|
t join
|
tčíä+ t join
|
tîáů / tΣσ,π
|
tîáů /tΣjoin
|
|
1
|
21,579
|
9,808
|
0,000
|
0,000
|
0,000
|
2,20
|
íĺň «join»
|
|
2
|
0,145
|
2,050
|
3,633
|
0,011
|
3,644
|
0,07
|
0,040
|
|
3
|
2,142
|
7,939
|
3,270
|
0,163
|
3,433
|
0,27
|
0,624
|
|
4
|
1,035
|
6,668
|
1,623
|
0,470
|
2,093
|
0,16
|
0,495
|
|
5
|
1,123
|
8,721
|
11,892
|
0,154
|
12,046
|
0,13
|
0,093
|
|
6
|
2,846
|
5,054
|
0,000
|
0,000
|
0,000
|
0,56
|
íĺň «join»
|
|
7
|
0,901
|
7,624
|
5,506
|
0,261
|
5,767
|
0,12
|
0,156
|
|
8
|
3,335
|
9,837
|
22,394
|
0,081
|
22,475
|
0,34
|
0,148
|
|
9
|
5,315
|
11,355
|
26,805
|
2,234
|
29,039
|
1,00
|
0,183
|
|
10
|
1,850
|
6,707
|
1,614
|
0,944
|
2,558
|
0,28
|
0,723
|
|
11
|
0,229
|
1,896
|
1,209
|
0,069
|
1,278
|
0,12
|
0,179
|
|
12
|
3,760
|
6,561
|
0,809
|
0,075
|
0,884
|
0,57
|
4,253
|
|
13
|
3,302
|
1,833
|
0,714
|
4,703
|
5,417
|
1,80
|
0,610
|
|
14
|
3,270
|
5,339
|
0,198
|
0,264
|
0,462
|
0,61
|
7,078
|
|
Čňîăî
|
50,830
|
91,392
|
79,667
|
9,428
|
89,096
|
0,556
|
0,571
|
Ęŕę ńëĺäóĺň čç ňŕáë.2, çíŕ÷ĺíč˙ tΣσ,π(ęđîěĺ çŕďđîńîâ ą 1, 13) č tΣjoin (ęđîěĺ çŕďđîńîâ ą 12, 14) ďđĺâűřŕţň tîáů. Ýňî îáú˙ńí˙ĺňń˙ ňĺě, ÷ňî MySQL 5.7 îďňčěčçčđóĺň čńďîëíĺíčĺ çŕďđîńîâ. Óńđĺäíĺííűĺ çíŕ÷ĺíč˙ tîáů/tΣσ,π= 0,556 č tîáů/tΣjoin = 0,571 ďđčěĺđíî îäčíŕęîâű: tΣjoin /tΣσ,π =0,975.  ÷ŕńňíîńňč, ďîëó÷ĺííűé đĺçóëüňŕň ďîçâîë˙ĺň ńäĺëŕňü číňĺđĺńíűé âűâîä îňíîńčňĺëüíî ďĺđńďĺęňčâíîé ńňđŕňĺăčč «ěíîćĺńňâî çŕďđîńîâ íŕ îäčí óçĺë ęëŕńňĺđŕ» ń đĺďëčęŕöčĺé ÁÄ ďî îňäĺëüíűě óçëŕě, îđčĺíňčđîâŕííîé íŕ đŕáîňó ń ęîíńĺđâŕňčâíűěč áŕçŕěč äŕííűő óěĺđĺííűő îáúĺěîâ – äî 100GB , íĺ ďđĺâűřŕţůčő îáúĺě îďĺđŕňčâíîé ďŕě˙ňč óçëŕ (ďî óńëîâčţ îííĺ ďđĺâűřŕĺň 128GB): ďĺđĺőîä ę GPU-ęëŕńňĺđŕě ń čńďîëüçîâŕíčĺě đĺăóë˙đíîăî ďëŕíŕ îáđŕáîňęč çŕďđîńîâ č ŕäŕďňŕöčĺé číńňđóěĺíňŕëüíűő ŃÓÁÄ ę ňŕęîé ďëŕňôîđěĺ â ýňîě ńëó÷ŕĺ íĺęîíęóđĺíňîńďîńîáĺí, íĺçŕâčńčěî îň ěĺńňŕ đĺŕëčçŕöčč «select–project»- č «join»-îáđŕáîňîę: íŕ CPU čëč GPU. Çäĺńü öĺëĺńîîáđŕçíŕ đŕçđŕáîňęŕ ńďĺöčŕëčçčđîâŕííűő ŃÓÁÄ ń îďňčěčçŕöčĺé çŕďđîńîâ ďđčěĺíčňĺëüíî ę čńďîëüçîâŕíčţ ăđŕôč÷ĺńęčő óńęîđčňĺëĺé [25].
Ńćŕňčĺ äŕííűő â đĺçóëüňŕňĺ «select-project»-îáđŕáîňęč – ďîëĺçíîĺ äë˙ äŕëüíĺéřĺăî çíŕíčĺ. Ďđč ďîäń÷ĺňĺ îáúĺěŕ íĺńćŕňűő äŕííűő äë˙ ëţáîăî čç đŕńńěŕňđčâŕĺěűő çŕďđîńîâ, îďđĺäĺë˙ëŕńü äëčíŕ ęŕćäîăî ďîë˙ ęŕćäîé ńňđîęč âńĺő ňŕáëčö, ó÷ŕńňâóţůčő â îáđŕáîňęĺ çŕďđîńŕ, č âńĺ ďîëó÷ĺííűĺ äëčíű ńóěěčđîâŕëčńü. Ďîäń÷ĺň âűďîëí˙ëń˙ ńđĺäńňâŕěč MySQL ďóňĺě ěîäčôčęŕöčč çŕďđîńîâ. Ďđčěĺđ ěîäčôčęŕöčč çŕďđîńŕ ą3:
-- O'
SELECT O_ORDERDATE, O_SHIPPRIORITY, O_ORDERKEY, O_CUSTKEY
FROM ORDERS
WHERE O_ORDERDATE < DATE '1995-03-31';
-- O' LENGTH
SELECT SUM(LENGTH(O_ORDERDATE), LENGTH(O_SHIPPRIORITY), LENGTH(O_ORDERKEY), LENGTH(O_CUSTKEY))
FROM ORDERS
WHERE O_ORDERDATE < DATE '1995-03-31';
|
Çäĺńü O' – îäčí čç ďîäçŕďđîńîâ «select – project», ďîëó÷ĺííűő ďîńëĺ ďđĺňđŕíńë˙öčč ýňîăî çŕďđîńŕ; O' LENGTH – çŕďđîń äë˙ ďîäń÷ĺňŕ îáúĺěŕ âîçâđŕůŕĺěűő äŕííűő. Đĺçóëüňŕňű čçěĺđĺíčé îáúĺěîâ číôîđěŕöčč íĺîáőîäčěîé äë˙ îáđŕáîňęč çŕďđîńîâ ďđčâĺäĺíű â ňŕáë.3.
Ňŕáëčöŕ 3. Îáúĺěű äŕííűő äë˙ îáđŕáîňęč çŕďđîńîâ TPC-H
|
ą çŕďđîńŕ
|
Îáúĺě äŕííűő äë˙ îáđŕáîňęč, áŕéň
|
Ęîýôôčöčĺíň óěĺíüřĺíč˙ îáúĺěŕ äŕííűő
|
|
Äî âűáîđęč ďî óńëîâč˙ě
|
Ďîńëĺ âűáîđęč ďî óńëîâč˙ě
|
|
|
Vîáů
|
(σ, π)Σ
|
Vîáů/(σ, π)Σ
|
|
1
|
675 846 277
|
134 255 929
|
5,03
|
|
2
|
137 651 393
|
13 526 703
|
10,18
|
|
3
|
855 794 582
|
76 991 966
|
11,12
|
|
4
|
832 798 438
|
428 049 230
|
1,95
|
|
5
|
857 126 234
|
139 324 211
|
6,15
|
|
6
|
675 846 277
|
1 339 256
|
504,64
|
|
7
|
857 125 865
|
78 759 670
|
10,88
|
|
8
|
879 261 359
|
179 338 247
|
4,90
|
|
9
|
970 449 462
|
234 598 226
|
4,14
|
|
10
|
855 796 681
|
49 964 804
|
17,13
|
|
11
|
342 555 947
|
27 528 586
|
12,44
|
|
12
|
832 798 438
|
23 140 549
|
35,99
|
|
13
|
179 948 305
|
18 706 950
|
9,62
|
|
4
|
697 981 402
|
6 548 108
|
106,59
|
|
Čňîăî
|
9 695 098 066
|
1 412 072 435
|
6,87
|
 ýňîé ňŕáëčöĺ: – ďîëíűé îáúĺě îňíîřĺíčé, íĺîáőîäčěűé äë˙ âűďîëíĺíč˙ çŕďđîńŕ; – ńóěěŕ îáúĺěîâ ňĺő ćĺ îňíîřĺíčé ďîńëĺ óěĺíüřĺíč˙ îáúĺěŕ äŕííűő ń čńďîëüçîâŕíčĺě óńëîâčé âűáîđęč čç çŕďđîńŕ (ńĺęöčč where). Čěĺĺě, â ńđĺäíĺě, ďđčěĺđíî 7-ęđŕňíîĺ óěĺíüřĺíčĺ îáúĺěŕ äŕííűő.
Ŕíŕëčç äë˙ ďđîńňĺéřĺăî ńëó÷ŕ˙. Đŕńńěîňđčě ďđčěĺđ îáđŕáîňęč ńčńňĺěîé đčń.7 ń äâóě˙ čńďîëíčňĺëüíűěč óçëŕěč (óçëű: 1 – IO č 2 – JOIN) č îäíčě óďđŕâë˙ţůčě (Mgm) ďđĺäńňŕâčňĺëüńęîăî ňĺńňŕ ĎŇ čç 14 çŕďđîńîâ â ńëó÷ŕĺ VÁÄ= 1GB. Âńĺ óçëű – 12-˙äĺđíűĺ. Óçĺë IO (ń GPU) âűďîëí˙ĺň «select–project»-îáđŕáîňęó çŕďđîńîâ íŕä ńćŕňîé ÁÄ. Óçĺë JOIN – ĺäčíűĺ ďđîöĺäóđű «join» ďî ęŕćäîěó çŕďđîńó ĎŇ, ďŕđŕëëĺëüíî ďî 12 çŕďđîńŕě (˙äđî íŕ çŕďđîń). GPU â JOIN âűďîëí˙ĺň đŕçćŕňčĺ ńćŕňűő îňíîřĺíčé Ri' «íŕ ďđîőîäĺ», ďî ěĺđĺ čő ďîńňóďëĺíč˙ â JOIN.
Ďđč ýňîě, ńîăëŕńíî ňŕáë.3, ńóěěŕđíűé îáúĺě îňíîřĺíčé, çŕäĺéńňâîâŕííűő â ďđîöĺńńĺ âűďîëíĺíč˙ ĎŇ, Vîáů∑≈ 9,7GB.  đĺçóëüňŕňĺ ńćŕňč˙ čńőîäíîé číôîđěŕöčč ďîńëĺ «select–project»-îáđŕáîňęč îńňŕĺňń˙ (σ, π)Σ ≈1,4GB ń ęîýôôčöčĺíňîě ńćŕňč˙ Vîáů∑/(σ, π)Σ ≈6,87. Ňîăäŕ äë˙ íĺńćŕňîé ÁÄ îáůčé îáúĺě číôîđěŕöčč, ďĺđĺäŕâŕĺěîé ďđč îáđŕáîňęĺ ĎŇ â IO-óçëĺ îň CPU ę GPU č îáđŕňíî, ńîńňŕâčň [ Vîáů∑+ (σ, π)Σ ] ≈ 11,1GB. Ďîńęîëüęó ďđĺäďîëŕăŕĺňń˙ ńđŕâíĺíčĺ đĺçóëüňŕňîâ ňĺîđĺňč÷ĺńęîăî ŕíŕëčçŕ ń ďîëó÷ĺííűěč đŕíĺĺ äë˙ ŃÓÁÄ Clusterix-M, ňî đŕńńěŕňđčâŕĺňń˙ čńďîëüçîâŕíčĺ ńĺňč GigabitEthernet. Âîçěîćíűěč ďĺđĺăđóçęŕěč ďî číňĺđęîííĺęňó (ęîăäŕ âđĺě˙ îćčäŕíč˙ ďĺđĺäŕ÷č ďî ńĺňč äë˙ íĺęîňîđűő ńîîáůĺíčé ďđĺâűřŕĺň çíŕ÷ĺíčĺ ňŕéě-ŕóňŕ, ÷ňî ďđčâîäčň ę «çŕâčńŕíčţ» ńčńňĺěű) áóäĺě ďđĺíĺáđĺăŕňü. Ďîëŕăŕĺě äîďîëíčňĺëüíî, ÷ňî ýňŕďű îáđŕáîňęč ĎŇ â öĺëîě («select–project»-îáđŕáîňęŕ → ďĺđĺäŕ÷ŕ ĺĺ đĺçóëüňŕňŕ ń óđîâí˙ IO ę Mgm č äŕëĺĺ – îň Mgm íŕ óđîâĺíü JOIN → ńîáńňâĺííî «join»-îáđŕáîňęŕ) ńëĺäóţň äđóă çŕ äđóăîě.

Đčń.7. Ŕíŕëčçčđóĺěűé ďđîńňĺéřčé ńëó÷ŕé
Ňĺîđĺňč÷ĺńęŕ˙ ńęîđîńňü ďĺđĺäŕ÷č ďî řčíĺ PCI-e đŕâíŕ 6,4GB/s. Ďîëó÷ĺíčĺ íŕ ďđŕęňčęĺ 3,2GB/s ěîćíî ăŕđŕíňčđîâŕňü. Ďîýňîěó äë˙ íĺńćŕňîé ÁÄ ńóěěŕđíîĺ âđĺě˙ ďĺđĺäŕ÷ číôîđěŕöčč â ęŕćäîě IO-óçëĺ îň CPU ę GPU îáúĺěîě Vîáů∑ ńîńňŕâčň tď1 = 9,7GB/(3,2GB/s) = 3,03ńĺę, ŕ îň GPU ę CPU – tď2 = 1,4GB/(3,2GB/s) = 0,44ńĺę. Ęŕę íŕěč óńňŕíîâëĺíî đŕíĺĺ (ńě. ňŕáë.1), őđŕíĺíčĺ čńőîäíîé ÁÄ â ńćŕňîě âčäĺ ń ęîýôôčöčĺíňîě ńćŕňč˙ K=5 óěĺíüřŕĺň tď1 ďđčěĺđíî íŕ 40%. Ńîîňâĺňńňâĺííî äë˙ 14 çŕďđîńîâ ĎŇ ďîëó÷ŕĺě tď′ = (3,03+ 0,44) ∙0,6 = 2,08 ńĺę. Äîďîëíčňĺëüíî íĺîáőîäčěî ó÷ĺńňü âđĺě˙ íŕ ďĺđĺäŕ÷ó ńćŕňűő äŕííűő ďî ńĺňč GigabitEthernet îň IO ę Mgm tď'′ = (σ, π)Σ /(5∙υńĺňč) =1,4GB/(5∙0,1GB/s) = 2,8ńĺę.  čňîăĺ ďîëó÷ŕĺě (tΣσ,π)′ = tď′ +tď'′ = 4,88ńĺę.
Ďîëŕăŕĺě, ÷ňî âűďîëíĺíčĺ ĺäčíűő ďî çŕďđîńŕě îďĺđŕöčé «join» íŕ÷číŕĺňń˙ ďî îęîí÷ŕíčč âńĺő ńĺňĺâűő ďĺđĺäŕ÷ äë˙ ďŕęĺňŕ čç 14 çŕďđîńîâ íĺďđĺđűâíîăî ďîňîęŕ. Ďđč îöĺíęĺ îáůĺăî âđĺěĺíč íŕ «join»-îáđŕáîňęó (tΣjoin)′ áóäĺě ó÷čňűâŕňü ńóěěŕđíîĺ âđĺě˙ ďĺđĺäŕ÷č tď'′' ńćŕňűő îňíîřĺíčé Ri′ (ďîńëĺäîâŕňĺëüíî ôîđěčđóĺěűő â BUF) îň Mgm íŕ óđîâĺíü JOIN ń ďîďđŕâęîé íŕ îňńóňńňâčĺ ďĺđĺäŕ÷ Ri′ äë˙ çŕďđîńîâ ą1 č ą6, íĺ ńîäĺđćŕůčő îďĺđŕöčé «join».Ńęŕíęŕňĺíčđîâŕííűĺ â BUF Mgm ÷ŕńňč Ri′ ýňčő çŕďđîńîâ áóäóň đĺňđŕíńëčđîâŕíű Mgm áĺç äîďîëíčňĺëüíîé «join»-îáđŕáîňęč. Ńîăëŕńíî ňŕáë.3, ńóěěěŕđíűé îáúĺě Ri′ ďî ýňčě çŕďđîńŕě đŕâĺí 135,6 MB. Ďîńëĺ ńćŕňč˙ čěĺĺě 0,028GB. Ďîýňîěó tď'′' = tď'′ –0,28ńĺę = 2,52ńĺę.
Ďŕęĺň čç îńňŕâřčőń˙ 12 çŕďđîńîâ áóäĺň ďŕđŕëëĺëüíî îáđŕáŕňűâŕňüń˙ íŕ 12 ˙äđŕő óçëŕ JOIN. Âđĺě˙ «join»-îáđŕáîňęč ýňîăî ďŕęĺňŕ (tΣjoin)12 îďđĺäĺëčňń˙ ńŕěîé ěĺäëĺííîé ďđîöĺäóđîé. Ńîăëŕńíî ňŕáë.2, ďîńëĺäíĺé çŕâĺđřčňń˙ îáđŕáîňęŕ ďî çŕďđîńó ą9, ň.ĺ. (tΣjoin)12 ≈ 29,04ńĺę. Îáůĺĺ âđĺě˙ (tΣjoin)′ = tď'′' + (tΣjoin)12 = 2,52ńĺę + 29,04ńĺę = 31,56ńĺę. Âđĺě˙ îáđŕáîňęč ńčńňĺěîé ďŕęĺňŕ čç 14 çŕďđîńîâ T = (tΣσ,π)′ + (tΣjoin)′ = 4,88ńĺę + 31,56ńĺę =36,44ńĺę. Ďîďđŕâęŕ íŕ GPU-đŕçćŕňčĺ äŕííűő â JOIN äîëćíŕ áűňü íč÷ňîćíî ěŕëîé.
ŃÓÁÄ Clusterix-M íŕ ďëŕňôîđěĺ 1 ń 6-ţ čńďîëíčňĺëüíűěč óçëŕěč ďîęŕçŕëŕ äë˙ ĎŇ (ńě. đčń.5) T1 = 268 ńĺę. Ó÷čňűâŕ˙, ÷ňî ďđč ďĺđĺőîäĺ ń ďëŕňôîđěű 1 íŕ ďëŕňôîđěó 2, áëŕăîäŕđ˙ čçěĺíĺíčţ ęîíôčăóđŕöčč óçëŕ îň «ëčíĺéęč» ę «ńîâěĺůĺííîé ńčěěĺňđčč», âđĺě˙ îáđŕáîňęč ĎŇ óěĺíüřŕĺňń˙ ďđčěĺđíî íŕ 25% (ńě. đčń.4á), ďîëó÷ŕĺě T2 ≈ 0,75T1 = 201 ńĺę. >> T. Äŕćĺ ďđčíčěŕ˙ âî âíčěŕíčĺ, ÷ňî čńőîäíŕ˙ ÁÄ ďđč ďđîâĺäĺíčč ýęńďĺđčěĺíňŕ ń Clusterix-M íŕőîäčëŕńü íŕ äčńęĺ, ďđčőîäčě ę âűâîäó: ďđč îáđŕáîňęĺ ďŕęĺňŕ 14 çŕďđîńîâ ĎŇ č ńđŕâíčňĺëüíî íĺáîëüřčő VÁÄ đŕńńěîňđĺííŕ˙ ďđîńňĺéřŕ˙ ńčńňĺěŕ äîëćíŕ áűňü çíŕ÷čňĺëüíî ýôôĺęňčâíĺĺ Clusterix-M.
Ďđčí˙ňŕ˙ ę đŕçđŕáîňęĺ íŕňóđíŕ˙ ěîäĺëü Clusterix-G îđăŕíčçóĺňń˙ íŕ ďëŕňôîđěĺ GPU-ęëŕńňĺđŕ ĘÍČŇÓ-ĘŔČ ń řĺńňüţ čńďîëíčňĺëüíűěč óçëŕěč (óçëű 1-6) č îäíčě óďđŕâë˙ţůčě (Mgm). Ďŕđŕěĺňđű óçëîâ: 2 six-core E5-2640 CPU/2,5GHz/DDR3 128GB; 2 448-core GPU Tesla C-2075/1,15GHz/GDDR5 6GB (íŕ Mgm GPU îňńóňńňâóţň). Äčńęîâŕ˙ ďîäńčńňĺěŕ óçëŕ – RAID-ěŕńńčâ 4 WD1000 DHTZ/1TB. Îďĺđŕöčîííŕ˙ ńčńňĺěŕ – SUSE Linux Enterprise Server âĺđńčč 11. Číňĺđęîííĺęň ěĺćäó óçëŕěč – GigabitEthernet c 24-ďîđňîâűě ęîěěóňŕňîđîě SSE G24-TG4 /10 GigabitEthernet ń 8-ďîđňîâűě ęîěěóňŕňîđîě NETGETAR XS708T-100NES.
Ńíŕ÷ŕëŕ đŕńńěîňđčě ńëó÷ŕé đŕâíîěĺđíîăî đŕńďđĺäĺëĺíč˙ čńďîëíčňĺëüíűő óçëîâ (đčń.8): óçëű 1-3 – IO, óçëű 4-6 – JOIN. Íŕ âńĺ óçëű óńňŕíîâëĺíŕ ŃÓÁÄ MySQL 5.7. Ńđŕâíčňĺëüíî íĺáîëüřčĺ đŕçěĺđű čńďîëüçóĺěîăî GPU-ęëŕńňĺđŕ îăđŕíč÷čâŕţň âîçěîćíîńňč ďđîâĺäĺíč˙ čńńëĺäîâŕíčé íŕ ĺăî îńíîâĺ ńëó÷ŕĺě VÁÄ ≤ 200GB. Ďđč÷číŕ â ńëĺäóţůĺě. Ńîăëŕńíî ňŕáë.3, ńóěěŕđíűé îáúĺě ďđîěĺćóňî÷íűő îňíîřĺíčé ĎŇ ≈ 1,4 VÁÄ. Ďđč VÁÄ = 200GB ýňî äŕĺň 280GB. Äŕííűĺ ňŕęîăî îáúĺěŕ (íî íĺ áîëĺĺ!) ĺůĺ ěîćíî đŕçěĺńňčňü â îďĺđŕňčâíîé ďŕě˙ňč ňđĺő óçëîâ JOIN (ďî óńëîâčţ îäčí óçĺë «ďđčíčěŕĺň» íĺ áîëĺĺ 100GB). Čç ňîé ćĺ ňŕáëčöű ńëĺäóĺň, ÷ňî ńóěěŕđíűĺ îáúĺěű Ri' äë˙ đŕçíűő çŕďđîńîâ ĎŇ ń «join»-îáđŕáîňęîé ńčëüíî đŕçëč÷ŕţňń˙ ~ îň 0,0065VÁÄ äî 0,428VÁÄ. Ňŕę ÷ňî ďđč äĺéńňâčč íĺďđĺđűâíîăî ďîňîęŕ çŕďđîńîâ, ńëó÷ŕéíî ôîđěčđóĺěűő íŕ ěíîćĺńňâĺ çŕďđîńîâ ĎŇ, â ęŕćäűé ěîěĺíň âđĺěĺíč â îäíîě JOIN-óçëĺ ěîăóň îáđŕáŕňűâŕňüń˙ îň îäíîăî äî äĺń˙ňč çŕďđîńîâ.

Đčń.8. Ńňđóęňóđŕ íŕňóđíîé ěîäĺëč Clusterix-G. Ńëó÷ŕé đŕâíîěĺđíîăî đŕńďđĺäĺëĺíč˙ čńďîëíčňĺëüíűő óçëîâ
Ďî ŕíŕëîăčč ń đŕíĺĺ đŕçđŕáîňŕííűěč ŃÓÁÄ Clusterix č ěóëüňčęëŕńňĺđíîé ŃÓÁÄ Clusterix-M, äë˙ öĺëĺé đŕçđŕáîňęč íŕňóđíîé ěîäĺëč Clusterix-G ďđčí˙ň ńëĺäóţůčé îđčĺíňčđîâî÷íűé ďëŕí ĺĺ ôóíęöčîíčđîâŕíč˙. Ěîäóëü ÓĎĐ â Mgm âĺäĺň î÷ĺđĺäü çŕďđîńîâ, đŕçäŕĺň çŕäŕíčĺ íŕ îáđŕáîňęó, áŕëŕíńčđóĺň íŕăđóçęó ěĺćäó óçëŕěč IO (â îňëč÷čĺ îň Clusterixč Clusterix-M, îíčđŕáîňŕţň ŕńčíőđîííî), ďîëó÷ŕĺň ďđîěĺćóňî÷íűĺ č ęîíĺ÷íűĺ đĺçóëüňŕňű čńďîëíĺíč˙ çŕďđîńîâ. Ěîäóëü SORT âűďîëí˙ĺň ôóíęöčč ŕăđĺăŕöčč č ńîđňčđîâęč đĺçóëüňŕňŕ îáđŕáîňęč çŕďđîńŕ. Ěîäóëü ROUTER – ôóíęöčţ áŕëŕíńčđîâęč íŕăđóçęč ěĺćäó óçëŕěč JOIN.  áóôĺđĺ BUF ďî ęŕćäîěó çŕďđîńó îńóůĺńňâë˙ĺňń˙ ęîíęŕňĺíŕöč˙ ÷ŕńňĺé ńćŕňűő îňíîřĺíčé Ri′ , ďîäëĺćŕůčő äŕëüíĺéřĺěó ńîĺäčíĺíčţ. Ôóíęöčč óďđŕâëĺíč˙ đĺŕëčçóţňń˙ ďî ńĺňč GigabitEthernet.
Íŕ óđîâíĺ IO ďîńëĺäîâŕňĺëüíî âűďîëí˙ţňń˙ îďĺđŕöčč «select – project» ďî ęŕćäîěó çŕďđîńó. Ďî óńëîâčţ âńĺ îďĺđŕöčč «project» «îďóůĺíű âíčç».CPU â IO ďđîĺöčđóţň ęîëîíęč, ôîđěčđóţň áëîęč ńćŕňîé ÁÄ, óďđŕâë˙ţň î÷ĺđĺäüţ ńâîčő ęîěŕíä, đŕáîňîé ăđŕôč÷ĺńęčő óńęîđčňĺëĺé (2 GPU íŕ óçĺë), ďĺđĺńűëęîé ńćŕňűő äŕííűő ďî řčíĺ PCI-e č ńĺňč 10 GigabitEthernet. Íŕ óđîâíĺ JOIN đĺŕëčçóţňń˙ číňĺăđčđîâŕííűĺ ďđîöĺäóđű «join» ďî çŕďđîńó â öĺëîě.Cđĺäńňâŕěč MySQL 5.7 îďňčěčçčđóĺňń˙ čő âűďîëíĺíčĺ.Âńĺ îňíîřĺíč˙ Ri′ ďî ęŕćäîěó çŕďđîńó äîëćíű ďîńňóďčňü â ďŕě˙ňü óçëŕ JOIN ďĺđĺä íŕ÷ŕëîě ďđîöĺäóđű.
Äŕäčě îđčĺíňčđîâî÷íűĺ îöĺíęč äë˙ ńëó÷ŕ˙ îáđŕáîňęč íŕňóđíîé ěîäĺëüţ đčń.8 ďŕęĺňŕ çŕďđîńîâ ĎŇ ďđč VÁÄ = 200GB. Ńîăëŕńíî ňŕáë.3, áóäĺě ďîëŕăŕňü, ÷ňî îäčí čç óçëîâ JOIN âűäĺë˙ĺňń˙ čńęëţ÷čňĺëüíî äë˙ îáđŕáîňęč çŕďđîńŕ ą4, ŕ äâŕ äđóăčő – äë˙ îáđŕáîňęč îńňŕëüíűő 11 çŕďđîńîâ ń «join».Ó÷ňĺě äîďîëíčňĺëüíî ńëĺäóţůĺĺ. Äóďëĺęńíűé őŕđŕęňĺđ ńĺňč ďĺđĺäŕ÷č äŕííűő ďîçâîëčň îđăŕíčçîâŕňü ńîâěĺůĺíčĺ ďĺđĺäŕ÷ îň IO ę Mgm č îň Mgm ę JOIN. Ŕíŕëîăč÷íűé äóďëĺęń ďî řčíĺ PCI-e č čńďîëüçîâŕíčĺ äâóő óńęîđčňĺëĺé â ęŕćäîě IO-óçëĺ ďîçâîëčň ńîâěĺńňčňü âî âđĺěĺíč đŕçćŕňčĺ, îáđŕáîňęó ďîđöčč äŕííűő, ńćŕňčĺ č ďĺđĺäŕ÷ó đĺçóëüňŕňŕ host-ďđîöĺńńîđó â îäíîě GPU ń ďĺđĺäŕ÷ĺé î÷ĺđĺäíîé ďîđöčč äđóăîěó GPU. Ňîăäŕ âđĺě˙ ńîáńňâĺííî «select–project»-îáđŕáîňęč îďđĺäĺëčňń˙ îäíîńňîđîííčě îáěĺíîě CPU →GPU ďî řčíĺ PCI-e.
Ńîîňâĺňńňâĺííî, ďđč óńëîâčč ëčíĺéíűő çŕâčńčěîńňĺé îň VÁÄ č â ďđĺćíčő îáîçíŕ÷ĺíč˙ő: tď′ ≈ tď1 = 3,03ńĺę∙0,6∙200/3 = 121,2ńĺę; tď'′ ≈ 1,4GB∙200/(5∙1GB/s) = 56ńĺę č (tΣσ,π)′ = tď′ +tď'′ ≈ 177,2ńĺę ≈ 0,05 ÷ŕń. Ó÷čňűâŕ˙, ńîăëŕńíî ňŕáë.2, ÷ňî (tΣjoin)12 îďđĺäĺë˙ĺňń˙ âđĺěĺíĺě «join»-îáđŕáîňęč çŕďđîńŕ ą9, čěĺĺě: (tΣjoin)′= (tΣjoin)12 = 200∙29,04 = 5808ńĺę ≈ 1,61 ÷ŕń. Ďîńęîëüęó (tΣjoin)′ >> (tΣσ,π)′, ňî îáůĺĺ âđĺě˙ T îáđŕáîňęč ĎŇ â öĺëîě T = (tΣσ,π)′ + (tΣjoin)′ ≈ (tΣjoin)′. Ďîýňîěó â áëîęĺ IO öĺëĺńîîáđŕçíî îńňŕâčňü ëčřü îäčí óçĺë, äîďîëíčâ áëîę JOIN äî ď˙ňč óçëîâ. Ňîăäŕ (tΣσ,π)′ ≈ 0,12÷ŕń, ÷ňî íĺçíŕ÷čňĺëüíî ďîâëč˙ĺň íŕ âĺëč÷číó T.
Đĺŕëüíŕ˙ äčíŕěčęŕ ďđîöĺńńîâ â ńčńňĺěĺďđč äĺéńňâčč íĺďđĺđűâíîăî ďîňîęŕ çŕďđîńîâ, ńëó÷ŕéíî ôîđěčđóĺěűő íŕ ěíîćĺńňâĺ çŕďđîńîâ ĎŇ, áóäĺň ńóůĺńňâĺííî áîëĺĺ ńëîćíîé ďî ńđŕâíĺíčţ ń đŕńńěîňđĺííîé. Ďđč ýňîě đîńň ÷čńëŕ óçëîâ JOIN ďîěîćĺň đŕçăđóçčňü BUF Mgm îň íŕęîďëĺíč˙ Ri′ ďî îćčäŕţůčě čńďîëíĺíč˙ çŕďđîńŕě č áóäĺň ńďîńîáńňâîâŕňü ďîâűřĺíčţ ďđîčçâîäčňĺëüíîńňč ńčńňĺěű. Îáńóćäĺíčĺ Ďđč čńďîëüçîâŕíčč îáű÷íűő âű÷čńëčňĺëüíűő ęëŕńňĺđîâ, îđăŕíčçŕöč˙ îáđŕáîňęč çŕďđîńîâ ę ęîíńĺđâŕňčâíűě ÁÄ áîëüřčő îáúĺěîâ ďî đĺăóë˙đíîěó ďëŕíó – ďîęŕ ÷ňî îáúĺęňčâíŕ˙ çŕęîíîěĺđíîńňü. Ýňî îáóńëîâëĺíî íĺîáőîäčěîńňüţ őĺřčđîâŕíč˙ ňŕęčő ÁÄ íŕ ěíîćĺńňâĺ óçëîâ ęëŕńňĺđŕ. Ńňîëü ćĺ îáîńíîâŕíî č äčíŕěč÷ĺńęîĺ ńĺăěĺíňčđîâŕíčĺ ďđîěĺćóňî÷íűő č âđĺěĺííűő îňíîřĺíčé. Ńëĺäńňâčĺě óęŕçŕííűő îáńňî˙ňĺëüńňâ îęŕçűâŕĺňń˙ «ęâŕçčďŕđŕáîëč÷ĺńęŕ˙» çŕâčńčěîńňü âđĺěĺíč îáđŕáîňęč ĎŇ îň ÷čńëŕ óçëîâ (äë˙ âű÷čńëčňĺëüíűő ęëŕńňĺđîâ áîëĺĺ őŕđŕęňĺđíî ďđčáëčćĺíčĺ ę ăčďĺđáîëĺ). Ďđč ýňîě ěŕęńčěóě ďđîčçâîäčňĺëüíîńňč íŕ ăđŕíč ěŕńřňŕáčđóĺěîńňč îęŕçűâŕĺňń˙ äîńňŕňî÷íî íčçęčě. Ňŕęîâŕ â äŕííîě ńëó÷ŕĺ ďëŕňŕ çŕ đŕáîňó ń áŕçŕěč äŕííűő áîëüřčő îáúĺěîâ. Ďĺđĺőîä ę ěóëüňčęëŕńňĺđčçŕöčč ďđč îăđŕíč÷ĺíčč ÷čńëŕ óçëîâ â ěîíîęëŕńňĺđŕő-ęîěďîíĺíňŕő č čńďîëüçîâŕíčč ŕđőčňĺęňóđű «ńîâěĺůĺííŕ˙ ńčěěĺňđč˙» çíŕ÷čňĺëüíî óëó÷řŕĺň ďîëîćĺíčĺ, ďđčáëčćŕ˙ óęŕçŕííóţ çŕâčńčěîńňü ę ăčďĺđáîëĺ. Ďđčěĺíĺíčĺ ďĺđńďĺęňčâíîé ňĺőíîëîăčč «îäčí óçĺë ęëŕńňĺđŕ íŕ ěíîćĺńňâî çŕďđîńîâ» îăđŕíč÷ĺíî îáúĺěîě îďĺđŕňčâíîé ďŕě˙ňč óçëŕ.
 ńňŕňüĺ ďîęŕçŕíî, ÷ňî ńĺđüĺçíîĺ ďîâűřĺíčĺ ýôôĺęňčâíîńňč (â ńđŕâíĺíčč ń Clusterix-M) ďđč đŕáîňĺ ń áŕçŕěč äŕííűő ńđŕâíčňĺëüíî íĺáîëüřčő îáúĺěîâ äîëćíî čěĺňü ěĺńňî ďđč ďĺđĺőîäĺ íŕ ďëŕňôîđěó GPU-ęëŕńňĺđŕ ďđč óńëîâčč őđŕíĺíč˙ đŕńďđĺäĺëĺííîé ÁÄ â ńćŕňîě âčäĺ â îďĺđŕňčâíîé ďŕě˙ňč IO-óçëîâ č îđăŕíčçŕöčč îáđŕáîňęč â JOIN-óçëŕő ďî ńőĺěĺ «çŕďđîń íŕ ˙äđî».  IO-óçëŕő GPU-ŕęńĺëĺđŕöč˙ čńďîëüçóĺňń˙ äë˙ đĺŕëčçŕöčč îďĺđŕöčč «select».  JOIN-óçëŕő – äë˙ âűďîëíĺíč˙ đŕçćŕňč˙ «íŕ ďđîőîäĺ» ďîńëĺäîâŕňĺëüíî ďîńňóďŕţůčő ńćŕňűő ďđîěĺćóňî÷íűő îňíîřĺíčé. Đĺŕëčçŕöč˙ ďî ňŕęîěó ďđčíöčďó GPU-ŃÓÁÄ îáúĺěŕěč äî íĺńęîëüęčő TB ňđĺáóĺň ďîńňđîĺíč˙ ŕńčěěĺňđč÷íűő ęëŕńňĺđîâ ńî ńđŕâíčňĺëüíî ěŕëűě ÷čńëîě IO-óçëîâ, äîńňŕňî÷íî áîëüřčě ÷čńëîě JOIN-óçëîâ č ńęîđîńňíîé ńĺňüţ ďĺđĺäŕ÷č äŕííűő. Íî čěĺĺňń˙ îăđŕíč÷čňĺëüíîĺ óńëîâčĺ: cóěěŕđíűé îáúĺě ďđîěĺćóňî÷íűő îňíîřĺíčé äë˙ ëţáîăî çŕďđîńŕ äĺéńňâóţůĺăî ďîňîęŕ íĺ äîëćĺí ďđĺâűřŕňü îáúĺěŕ îďĺđŕňčâíîé ďŕě˙ňč óçëŕ.
Ďđĺäńňŕâë˙ĺň číňĺđĺń âîďđîń: íŕńęîëüęî âńĺ ćĺ îďđŕâäŕíî čńďîëüçîâŕíčĺ â ďđčí˙ňîé íŕňóđíîé ěîäĺëč (Clusterix-G) GPU-ŕęńĺëĺđŕöčč, č íĺëüç˙ ëč â äŕííîě ńëó÷ŕĺ ďđčěĺíčňü ńőĺěó «çŕďđîń íŕ ˙äđî» â áëîęĺ IO ń őđŕíĺíčĺě íĺńćŕňîé ÁÄ â îďĺđŕňčâíîé ďŕě˙ňč óçëŕ (ÎĎ) č ďĺđĺäŕ÷ĺé ďî ńĺňč íĺńćŕňűő ďđîěĺćóňî÷íűő îňíîřĺíčé? Ďîńęîëüęó ďî óńëîâčţ đŕçěĺđű ÎĎ íĺ ďîçâîë˙ţň çŕăđóçęó äŕííűő îáúĺěîě >100GB, ďđčäĺňń˙ ÁÄ őĺřčđîâŕňü ďî äâóě óçëŕě, ňŕę ÷ňî â áëîęĺ JOJN îńňŕíĺňń˙ 4 óçëŕ. Íî ýňî íĺ ďîâëč˙ĺň íŕ çíŕ÷ĺíčĺ (tΣjoin)′ = 1,61÷ŕń äë˙ ĎŇ. Âđĺě˙ ďŕđŕëëĺëüíîăî ôóíęöčîíčđîâŕíč˙ áëîęŕ IO îďđĺäĺëčňń˙ âĺëč÷číîé tΣσ,π äë˙ ńŕěîăî «ň˙ćĺëîăî» íŕ ĎŇ çŕďđîńŕ. Ńîăëŕńíî ňŕáë.3, ňŕęîâűě âíîâü ˙âë˙ĺňń˙ çŕďđîń ą9. Äë˙ íĺăî tΣσ,π = 11,355ńĺę∙100 = 1135,5ńĺę ≈ 0,32÷ŕń. Ńóěěŕđíîĺ âđĺě˙ ďĺđĺäŕ÷č Ri′ ďî ńĺňč ńîńňŕâčň ňĺďĺđü tď'′ ≈ 280ńĺę ≈ 0,078 ÷ŕń. Ňŕę ÷ňî (tΣσ,π)′ = tΣσ,π + tď'′ ≈ 0,4÷ŕń, ňîăäŕ ęŕę äë˙ îäíîăî IO-óçëŕ ń GPU áűëî ďîëó÷ĺíî (tΣσ,π)′ ≈ 0,12÷ŕń. Íŕéäĺííŕ˙ đŕçíčöŕ ěîćĺň ńĺđüĺçíî ďîâëč˙ňü íŕ âűáîđ öĺëĺńîîáđŕçíîăî ÷čńëŕ JOJN-óëîâ č äîńňčćčěóţ ďđîčçâîäčňĺëüíîńňü ďđč äĺéńňâčč íĺďđĺđűâíîăî ďîňîęŕ çŕďđîńîâ.
Ďîëó÷ĺíčĺ îęîí÷ŕňĺëüíîăî îňâĺňŕ íŕ âîďđîń îá ýôôĺęňčâíîńňč ďđčěĺíĺíč˙ GPU â ńëó÷ŕĺ áŕç äŕííűő áîëüřčő îáúĺěîâ ńâ˙çűâŕĺňń˙ ń đŕçđŕáîňęîé č čńńëĺäîâŕíčĺě íŕňóđíîé ěîäĺëč ŃÓÁÄ Clusterix-G.
Ęŕę áű ňî íč áűëî, íî ďîńëĺäíčé đŕńńěîňđĺííűé âŕđčŕíň ďđĺäńňŕâë˙ĺň ďđčíöčďčŕëüíîĺ čçěĺíĺíčĺ ěĺňîäîëîăčč Clusterix. Ńóňü ýňîăî čçěĺíĺíč˙ ńîńňîčň â îňęŕçĺ îň đŕńďđĺäĺëĺííîé îáđŕáîňęč çŕďđîńŕ íŕ óđîâíĺ JOIN č îň äčíŕěč÷ĺńęîăî ńĺăěĺíňčđîâŕíč˙ ďđîěĺćóňî÷íűő č âđĺěĺííűő îňíîřĺíčé, ÷ňî ńóůĺńňâĺííî îáëĺă÷ŕĺň đŕçđŕáîňęó ŃÓÁÄ â öĺëîě č ďîâűřŕĺň ĺĺ ýôôĺęňčâűíîńňü. Íî íĺëüç˙ çŕáűâŕňü î đŕíĺĺ ńôîđěóëčđîâŕííîě óńëîâčč îňíîńčňĺëüíî cóěěŕđíîăî îáúĺěŕ ďđîěĺćóňî÷íűő îňíîřĺíčé. Ăŕđŕíňčđîâŕňü ĺăî âűďîëíĺíčĺ â îáůĺě ńëó÷ŕĺ íĺâîçěîćíî (ďđčěĺđ çŕďđîńŕ ą4). Ńí˙ňčĺ ýňîăî óńëîâč˙ îçíŕ÷ŕĺň âîçâđŕň ę ěĺňîäîëîăčč Clusterix-M.
Âî čçáĺćŕíčĺ ďĺđĺďîëíĺíč˙ ďŕě˙ňč Mgm, ęŕćäîĺ Ri′ îňńűëŕĺňń˙ â ďîäőîä˙ůčé óçĺë JOJN ńđŕçó ďî îęîí÷ŕíčč íŕęîďëĺíč˙ ýňîăî Ri′ â BUF. Âîçěîćíűĺ çŕňđóäíĺíč˙, ńâ˙çŕííűĺ ń îăđŕíč÷ĺííűě îáúĺěîě óçëîâîé îďĺđŕňčâíîé ďŕě˙ňč, ěîćíî îáëĺă÷čňü äë˙ óçëîâ JOJN, ĺńëč ďđĺäóńěîňđĺňü â íčő ďîńëĺäîâŕňĺëüíîĺ (íĺ číňĺăđčđîâŕííîĺ) âűďîëíĺíčĺ îďĺđŕöčé «join» (ńîăëŕńíî đčń.1). Č őîň˙ ňŕęîĺ âűďîëíĺíčĺ âäâîĺ óâĺëč÷čň tΣjoin, íî «join»-îáđŕáîňęŕ â öĺëîě áóäĺň ÷ŕńňč÷íî ńîâěĺůĺíŕ ń ďĺđĺäŕ÷ĺé ďî ńĺňč îňíîřĺíčé Ri′.
Âűďîëíĺííűé äë˙ ńëó÷ŕ˙ GPU-ŕęńĺëĺđŕöčč ŕíŕëčç â öĺëîě čěĺë öĺëüţ îáńóćäĺíčĺ ďđčíöčďîâ âűńîęîýôôĺęňčâíîăî ďîńňđîĺíč˙ ęîíńĺđâŕňčâíűő ŃÓÁÄ îáúĺěîě ≥ 100GB äîâîëüíî ńęđîěíűěč ńđĺäńňâŕěč, äîńňóďíűěč â íŕńňî˙ůĺĺ âđĺě˙ řčđîęîěó ęđóăó íŕó÷íî-îáđŕçîâŕňĺëüíűő îđăŕíčçŕöčé. Čńďîëüçîâŕíčĺ ďĺđńďĺęňčâíűő, íî äîâîëüíî äîđîăčő ňĺőíîëîăčé ń îáúĺěŕěč îďĺđŕňčâíîé ďŕě˙ňč äî 2TB č çíŕ÷čňĺëüíűě ÷čńëîě ˙äĺđ (íĺ ěĺíĺĺ 18) â óçëĺ äĺëŕĺň ďîäőîä [17] íĺäîń˙ăŕĺěűě ďî ýôôĺęňčâíîńňč äđóăčěč čçâĺńňíűěč ěĺňîäŕěč ďîńňđîĺíč˙ áîëüřĺîáúĺěíűő ęîíńĺđâŕňčâíűő ŃÓÁÄ ęëŕńňĺđíîăî ňčďŕ. Âî âń˙ęîě ńëó÷ŕĺ, ýęńďĺđčěĺíňŕëüíűő äŕííűő, îďđîâĺđăŕţůčő ýňî óňâĺđćäĺíčĺ, ďîęŕ íĺ čěĺĺňń˙.
References
1. Jae-Woo Chang, Young-Chang Kim. Cluster-based DBMS Management Tool with High-Availability //Journal of Systemics, Cybernetics and Informatics. V. 3. 2005. ą1. P.46-51.
2. Ferhatosmanoglu H., Tosun A. S., Canahuate G., Ramachandran A. Efficient parallel processing of range queries through replicated declustering //Distrib. Parallel Databases. 2006. Vol.20, No.2. P.117—147.
3. Ahrendt E. Extreme databases: The biggest and fastest. IBM developer Works //IBM Data Management Magazine Issue 1, 2010. — P.18-23.
4. Stonebraker M. 10 rules for scalable performance in 'simple operation' datastores //Communications of the ACM. 2011. Vol.54, No.6. P.72-80.
5. Xu Y., Kostamaa P., Zhou X., Chen L. Handling data skew in parallel joins in shared-nothing systems //ACM SIGMOD international Conference on Management 9of Data Canada, 2008, proceedings. ACM, 2008. — P.1043-1052.
6. Szalay A.S. The Sloan Digital Sky Survey and beyond //SIGMOD Record. 2008. Vol.37, No.2. P. 61—66.
7. Shiers J. The Worldwide LHC Computing Grid (worldwide LCG) //Computer Physics Communications. 2007. Vol. 177 No. 1-2. P. 219—223.
8. Taniar D., Leung C., Rahayu J. W. High-performance parallel database processing and grid databases. — John Wiley & Sons Inc., Hoboken, 2008. 553 pp. DOI: 10.1002/9780470391365
9. Raikhlin, V.A. Simulation of Distributed Database Machines //Programming and Computer Software. Vol. 22, Issue 2, 1996, P. 68-74.
10. Abramov E. V. Parallel'naya SUBD Clusterix. Razrabotka prototipa i ego naturnoe issledovanie // Vestnik KGTU im. A. N. Tupoleva. 2006. ą 2. S. 50–55.
11. Martin, J. Computer database organization. Second Edition — Prentice-Hall, Inc., Englewood Cliffs, New Jersey 07632, 1977. 662 pp.
12. Raikhlin, V.A., Shagejev D.O. Information clusters as dissapative systems //Nonlinear world. Vol.7. 2009. No.5. P.323-334.
13. Raikhlin V. A., Shageev D. O. Informatsionnye klastery kak dissipativnye sistemy // Nelineinyi mir. 2009. T. 7. ą 5. S. 323–334.
14. Raikhlin V.A., Abramov E.V. K teorii modelei sinteza klasterov baz dannykh //Vestnik KGTU im. A.N. Tupoleva. 2004. No1. C.44-49.
15. Raikhlin V.A., Abramov E.V. Klastery baz dannykh. Modelirovanie evolyutsii //Vestnik KGTU im. A.N. Tupoleva. 2006. No3. S. 22-27.
16. Raikhlin V.A., Minyazev R.Sh. Analiz protsessov v klasterakh konservativnykh baz dannykh s pozitsii samoorganizatsii //Vestnik KGTU im. A.N. Tupoleva. 2015. No.2. S.120-126.
17. Klassen R.K. Povyshenie effektivnosti parallel'noi subd konservativnogo tipa na klasternoi platforme s mnogoyadernymi uzlami //Vestnik KGTU im. A.N. Tupoleva. 2015. No.1. S.112-118.
18. CoGaDB — Column-oriented GPU-accelerated DBMS. URL:http://cogadb.cs.tudortmund.de/wordpress.
19. PGStrom 2016. URL: https://wiki.postgresql.org/index.php?title=PGStrom&oldid=25517.
20. Besedin D. Pervyi vzglyad na DDR3. Izuchaem novoe pokolenie pamyati DDR SDRAM, teoreticheski i prakticheski //ixbt.com. 2007. URL: http://www.ixbt.com/mainboard/ddr3-rmma.shtml (data obrashcheniya: 01.10.2016).ixbt.com. 2007.
21. Petrov S.V. Shiny PCI, PCI Express. Arkhitektura, dizain, printsipy funktsionirovaniya. SPb.: BKhV-Peterburg, 2006. 321-322 s.
22. Rauhe H. Finding the Right Processor for the Job Co-Processors in a DBMS, Ilmenau University of Technology, Ilmenau, Dissertation. 125 pp. urn:nbn:de:gbv:ilm1-2014000240, 2014.
23. Wenbin F., Bingsheng H., Qiong L. Database Compression on Graphics Processors //Proc. VLDB Endow., Vol. 3, No. 1-2, Sep 2010. P.670-680.
24. Blelloch G. Introduction to Data Compression. Pittsburgh: Carnegie Mellon University, 2013. P.25-26.
25. Bres S. Efficient query processing in co-processor-accelerated database //University of Magdeburg, 2015. 207 pp.
|








